 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciDr at SDU-2020: IDEAS -- Identifying and Disambiguating Everyday Acronyms for Scientific Domain
Mar 08, 2021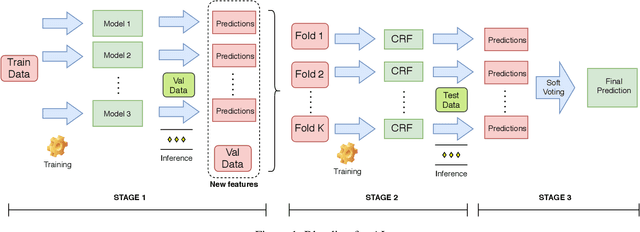
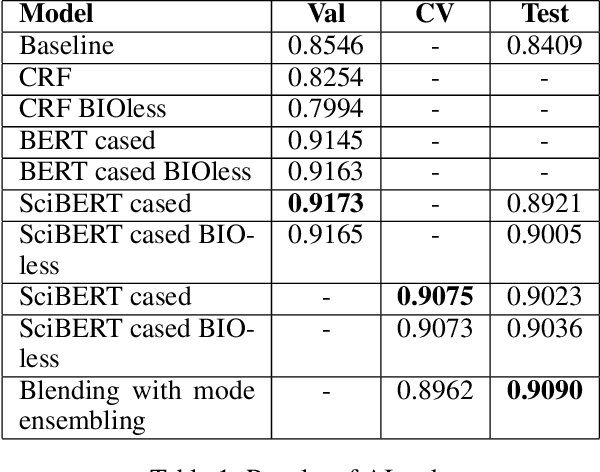
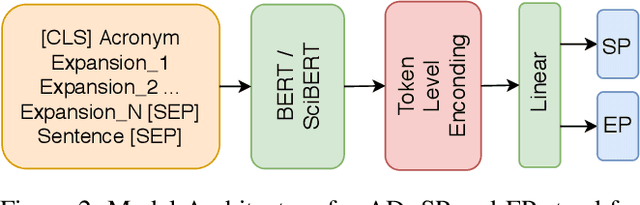
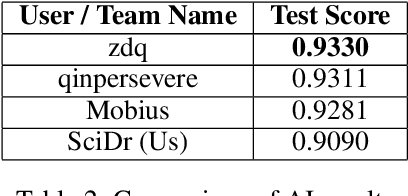
We present our systems submitted for the shared tasks of Acronym Identification (AI) and Acronym Disambiguation (AD) held under Workshop on SDU. We mainly experiment with BERT and SciBERT. In addition, we assess the effectiveness of "BIOless" tagging and blending along with the prowess of ensembling in AI. For AD, we formulate the problem as a span prediction task, experiment with different training techniques and also leverage the use of external data. Our systems rank 11th and 3rd in AI and AD tasks respectively.
NutCracker at WNUT-2020 Task 2: Robustly Identifying Informative COVID-19 Tweets using Ensembling and Adversarial Training
Oct 09, 2020

We experiment with COVID-Twitter-BERT and RoBERTa models to identify informative COVID-19 tweets. We further experiment with adversarial training to make our models robust. The ensemble of COVID-Twitter-BERT and RoBERTa obtains a F1-score of 0.9096 (on the positive class) on the test data of WNUT-2020 Task 2 and ranks 1st on the leaderboard. The ensemble of the models trained using adversarial training also produces similar result.
DSC IIT-ISM at SemEval-2020 Task 6: Boosting BERT with Dependencies for Definition Extraction
Sep 17, 2020


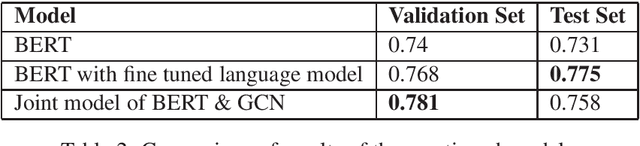
We explore the performance of Bidirectional Encoder Representations from Transformers (BERT) at definition extraction. We further propose a joint model of BERT and Text Level Graph Convolutional Network so as to incorporate dependencies into the model. Our proposed model produces better results than BERT and achieves comparable results to BERT with fine tuned language model in DeftEval (Task 6 of SemEval 2020), a shared task of classifying whether a sentence contains a definition or not (Subtask 1).