Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciDr at SDU-2020: IDEAS -- Identifying and Disambiguating Everyday Acronyms for Scientific Domain
Paper and Code
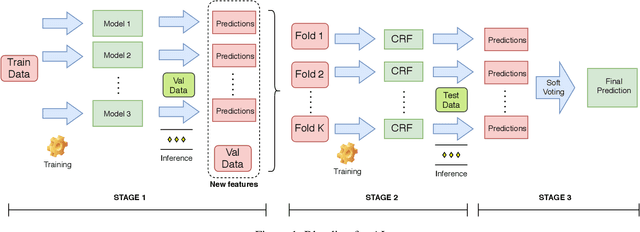
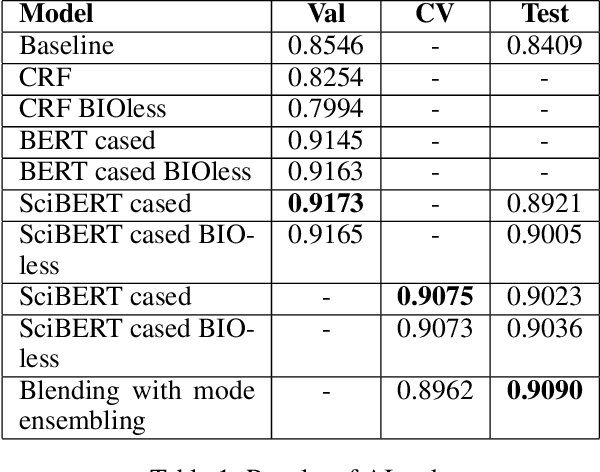
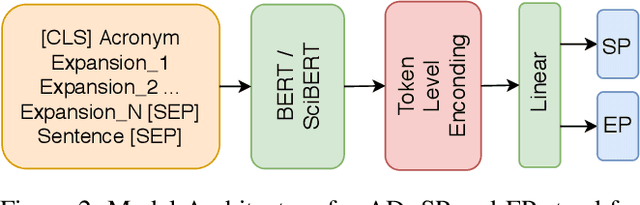
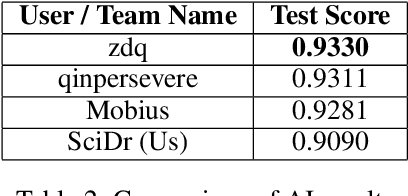
We present our systems submitted for the shared tasks of Acronym Identification (AI) and Acronym Disambiguation (AD) held under Workshop on SDU. We mainly experiment with BERT and SciBERT. In addition, we assess the effectiveness of "BIOless" tagging and blending along with the prowess of ensembling in AI. For AD, we formulate the problem as a span prediction task, experiment with different training techniques and also leverage the use of external data. Our systems rank 11th and 3rd in AI and AD tasks respectively.
View paper on