 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyGuard: A Multilingual Safety Moderation Tool for 17 Languages
Apr 06, 2025Truly multilingual safety moderation efforts for Large Language Models (LLMs) have been hindered by a narrow focus on a small set of languages (e.g., English, Chinese) as well as a limited scope of safety definition, resulting in significant gaps in moderation capabilities. To bridge these gaps, we release POLYGUARD, a new state-of-the-art multilingual safety model for safeguarding LLM generations, and the corresponding training and evaluation datasets. POLYGUARD is trained on POLYGUARDMIX, the largest multilingual safety training corpus to date containing 1.91M samples across 17 languages (e.g., Chinese, Czech, English, Hindi). We also introduce POLYGUARDPROMPTS, a high quality multilingual benchmark with 29K samples for the evaluation of safety guardrails. Created by combining naturally occurring multilingual human-LLM interactions and human-verified machine translations of an English-only safety dataset (WildGuardMix; Han et al., 2024), our datasets contain prompt-output pairs with labels of prompt harmfulness, response harmfulness, and response refusal. Through extensive evaluations across multiple safety and toxicity benchmarks, we demonstrate that POLYGUARD outperforms existing state-of-the-art open-weight and commercial safety classifiers by 5.5%. Our contributions advance efforts toward safer multilingual LLMs for all global users.
SPLAT: A framework for optimised GPU code-generation for SParse reguLar ATtention
Jul 23, 2024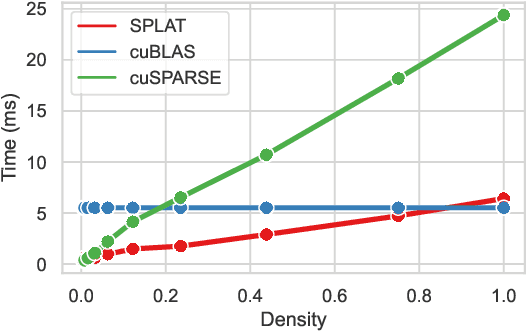
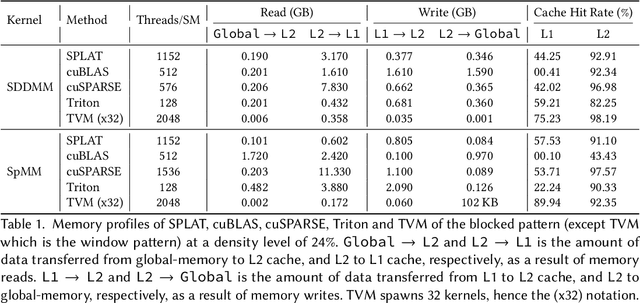
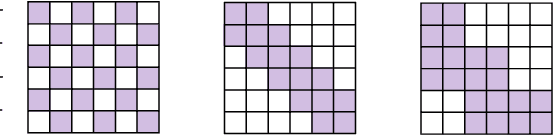

Multi-head-self-attention (MHSA) mechanisms achieve state-of-the-art (SOTA) performance across natural language processing and vision tasks. However, their quadratic dependence on sequence lengths has bottlenecked inference speeds. To circumvent this bottleneck, researchers have proposed various sparse-MHSA models, where a subset of full attention is computed. Despite their promise, current sparse libraries and compilers do not support high-performance implementations for diverse sparse-MHSA patterns due to the underlying sparse formats they operate on. These formats, which are typically designed for high-performance & scientific computing applications, are either curated for extreme amounts of random sparsity (<1% non-zero values), or specific sparsity patterns. However, the sparsity patterns in sparse-MHSA are moderately sparse (10-50% non-zero values) and varied, resulting in existing sparse-formats trading off generality for performance. We bridge this gap, achieving both generality and performance, by proposing a novel sparse format: affine-compressed-sparse-row (ACSR) and supporting code-generation scheme, SPLAT, that generates high-performance implementations for diverse sparse-MHSA patterns on GPUs. Core to our proposed format and code generation algorithm is the observation that common sparse-MHSA patterns have uniquely regular geometric properties. These properties, which can be analyzed just-in-time, expose novel optimizations and tiling strategies that SPLAT exploits to generate high-performance implementations for diverse patterns. To demonstrate SPLAT's efficacy, we use it to generate code for various sparse-MHSA models, achieving geomean speedups of 2.05x and 4.05x over hand-written kernels written in triton and TVM respectively on A100 GPUs. Moreover, its interfaces are intuitive and easy to use with existing implementations of MHSA in JAX.
PolygloToxicityPrompts: Multilingual Evaluation of Neural Toxic Degeneration in Large Language Models
May 15, 2024Recent advances in large language models (LLMs) have led to their extensive global deployment, and ensuring their safety calls for comprehensive and multilingual toxicity evaluations. However, existing toxicity benchmarks are overwhelmingly focused on English, posing serious risks to deploying LLMs in other languages. We address this by introducing PolygloToxicityPrompts (PTP), the first large-scale multilingual toxicity evaluation benchmark of 425K naturally occurring prompts spanning 17 languages. We overcome the scarcity of naturally occurring toxicity in web-text and ensure coverage across languages with varying resources by automatically scraping over 100M web-text documents. Using PTP, we investigate research questions to study the impact of model size, prompt language, and instruction and preference-tuning methods on toxicity by benchmarking over 60 LLMs. Notably, we find that toxicity increases as language resources decrease or model size increases. Although instruction- and preference-tuning reduce toxicity, the choice of preference-tuning method does not have any significant impact. Our findings shed light on crucial shortcomings of LLM safeguarding and highlight areas for future research.
GlobalFlowNet: Video Stabilization using Deep Distilled Global Motion Estimates
Nov 04, 2022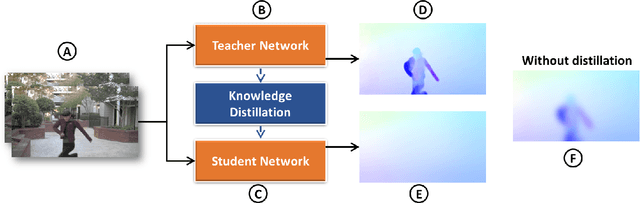

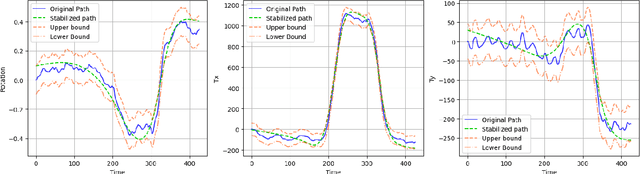
Videos shot by laymen using hand-held cameras contain undesirable shaky motion. Estimating the global motion between successive frames, in a manner not influenced by moving objects, is central to many video stabilization techniques, but poses significant challenges. A large body of work uses 2D affine transformations or homography for the global motion. However, in this work, we introduce a more general representation scheme, which adapts any existing optical flow network to ignore the moving objects and obtain a spatially smooth approximation of the global motion between video frames. We achieve this by a knowledge distillation approach, where we first introduce a low pass filter module into the optical flow network to constrain the predicted optical flow to be spatially smooth. This becomes our student network, named as \textsc{GlobalFlowNet}. Then, using the original optical flow network as the teacher network, we train the student network using a robust loss function. Given a trained \textsc{GlobalFlowNet}, we stabilize videos using a two stage process. In the first stage, we correct the instability in affine parameters using a quadratic programming approach constrained by a user-specified cropping limit to control loss of field of view. In the second stage, we stabilize the video further by smoothing global motion parameters, expressed using a small number of discrete cosine transform coefficients. In extensive experiments on a variety of different videos, our technique outperforms state of the art techniques in terms of subjective quality and different quantitative measures of video stability. The source code is publicly available at \href{https://github.com/GlobalFlowNet/GlobalFlowNet}{https://github.com/GlobalFlowNet/GlobalFlowNet}
Distilling Hypernymy Relations from Language Models: On the Effectiveness of Zero-Shot Taxonomy Induction
Feb 10, 2022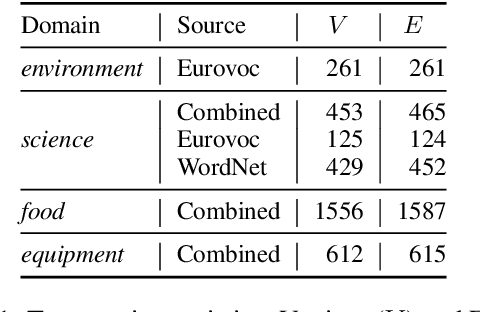
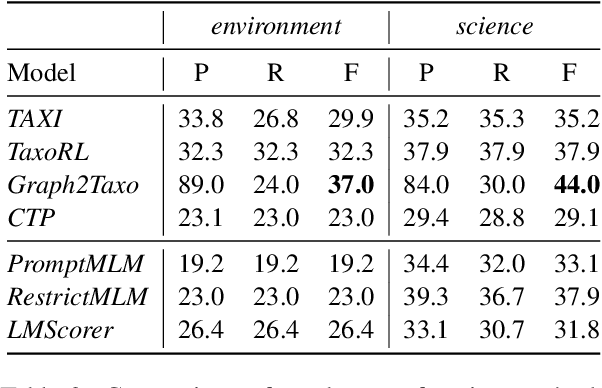
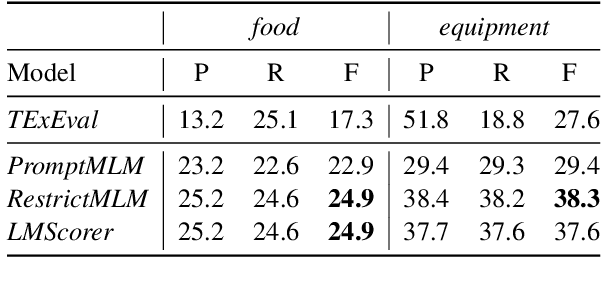
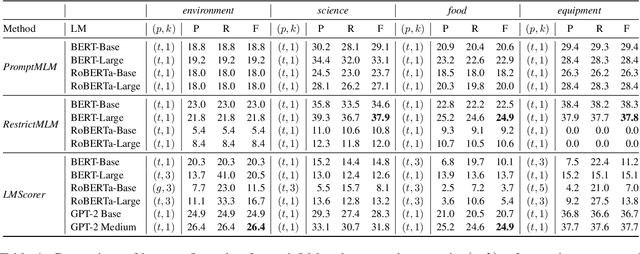
In this paper, we analyze zero-shot taxonomy learning methods which are based on distilling knowledge from language models via prompting and sentence scoring. We show that, despite their simplicity, these methods outperform some supervised strategies and are competitive with the current state-of-the-art under adequate conditions. We also show that statistical and linguistic properties of prompts dictate downstream performance.