 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiLo: Efficient Quantized MoE Inference with Mixture of Low-Rank Compensators
Apr 03, 2025A critical approach for efficiently deploying Mixture-of-Experts (MoE) models with massive parameters is quantization. However, state-of-the-art MoE models suffer from non-negligible accuracy loss with extreme quantization, such as under 4 bits. To address this, we introduce MiLo, a novel method that augments highly quantized MoEs with a mixture of low-rank compensators. These compensators consume only a small amount of additional memory but significantly recover accuracy loss from extreme quantization. MiLo also identifies that MoEmodels exhibit distinctive characteristics across weights due to their hybrid dense-sparse architectures, and employs adaptive rank selection policies along with iterative optimizations to close the accuracy gap. MiLo does not rely on calibration data, allowing it to generalize to different MoE models and datasets without overfitting to a calibration set. To avoid the hardware inefficiencies of extreme quantization, such as 3-bit, MiLo develops Tensor Core-friendly 3-bit kernels, enabling measured latency speedups on 3-bit quantized MoE models. Our evaluation shows that MiLo outperforms existing methods on SoTA MoE models across various tasks.
SPLAT: A framework for optimised GPU code-generation for SParse reguLar ATtention
Jul 23, 2024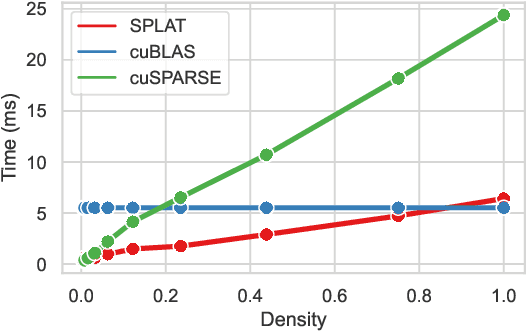
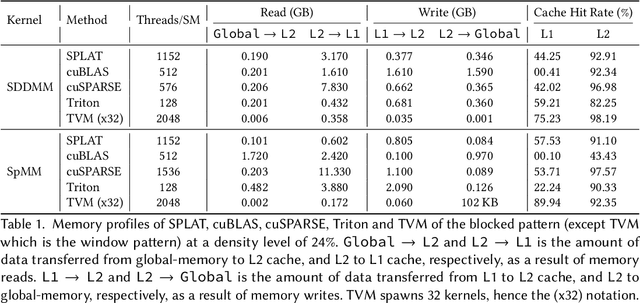
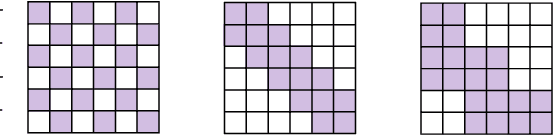

Multi-head-self-attention (MHSA) mechanisms achieve state-of-the-art (SOTA) performance across natural language processing and vision tasks. However, their quadratic dependence on sequence lengths has bottlenecked inference speeds. To circumvent this bottleneck, researchers have proposed various sparse-MHSA models, where a subset of full attention is computed. Despite their promise, current sparse libraries and compilers do not support high-performance implementations for diverse sparse-MHSA patterns due to the underlying sparse formats they operate on. These formats, which are typically designed for high-performance & scientific computing applications, are either curated for extreme amounts of random sparsity (<1% non-zero values), or specific sparsity patterns. However, the sparsity patterns in sparse-MHSA are moderately sparse (10-50% non-zero values) and varied, resulting in existing sparse-formats trading off generality for performance. We bridge this gap, achieving both generality and performance, by proposing a novel sparse format: affine-compressed-sparse-row (ACSR) and supporting code-generation scheme, SPLAT, that generates high-performance implementations for diverse sparse-MHSA patterns on GPUs. Core to our proposed format and code generation algorithm is the observation that common sparse-MHSA patterns have uniquely regular geometric properties. These properties, which can be analyzed just-in-time, expose novel optimizations and tiling strategies that SPLAT exploits to generate high-performance implementations for diverse patterns. To demonstrate SPLAT's efficacy, we use it to generate code for various sparse-MHSA models, achieving geomean speedups of 2.05x and 4.05x over hand-written kernels written in triton and TVM respectively on A100 GPUs. Moreover, its interfaces are intuitive and easy to use with existing implementations of MHSA in JAX.
FLuRKA: Fast fused Low-Rank & Kernel Attention
Jun 27, 2023



Many efficient approximate self-attention techniques have become prevalent since the inception of the transformer architecture. Two popular classes of these techniques are low-rank and kernel methods. Each of these methods has its own strengths. We observe these strengths synergistically complement each other and exploit these synergies to fuse low-rank and kernel methods, producing a new class of transformers: FLuRKA (Fast Low-Rank and Kernel Attention). FLuRKA provide sizable performance gains over these approximate techniques and are of high quality. We theoretically and empirically evaluate both the runtime performance and quality of FLuRKA. Our runtime analysis posits a variety of parameter configurations where FLuRKA exhibit speedups and our accuracy analysis bounds the error of FLuRKA with respect to full-attention. We instantiate three FLuRKA variants which experience empirical speedups of up to 3.3x and 1.7x over low-rank and kernel methods respectively. This translates to speedups of up to 30x over models with full-attention. With respect to model quality, FLuRKA can match the accuracy of low-rank and kernel methods on GLUE after pre-training on wiki-text 103. When pre-training on a fixed time budget, FLuRKA yield better perplexity scores than models with full-attention.