 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Joint Structured Pruning and Quantization for Efficient Neural Network Training and Compression
Feb 23, 2025Structured pruning and quantization are fundamental techniques used to reduce the size of deep neural networks (DNNs) and typically are applied independently. Applying these techniques jointly via co-optimization has the potential to produce smaller, high-quality models. However, existing joint schemes are not widely used because of (1) engineering difficulties (complicated multi-stage processes), (2) black-box optimization (extensive hyperparameter tuning to control the overall compression), and (3) insufficient architecture generalization. To address these limitations, we present the framework GETA, which automatically and efficiently performs joint structured pruning and quantization-aware training on any DNNs. GETA introduces three key innovations: (i) a quantization-aware dependency graph (QADG) that constructs a pruning search space for generic quantization-aware DNN, (ii) a partially projected stochastic gradient method that guarantees layerwise bit constraints are satisfied, and (iii) a new joint learning strategy that incorporates interpretable relationships between pruning and quantization. We present numerical experiments on both convolutional neural networks and transformer architectures that show that our approach achieves competitive (often superior) performance compared to existing joint pruning and quantization methods.
Zero-Shot Text-to-Speech from Continuous Text Streams
Oct 01, 2024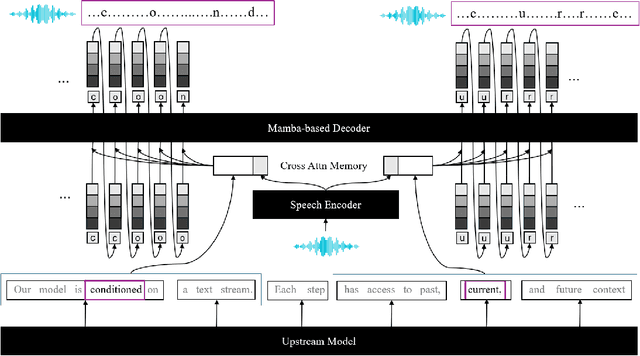

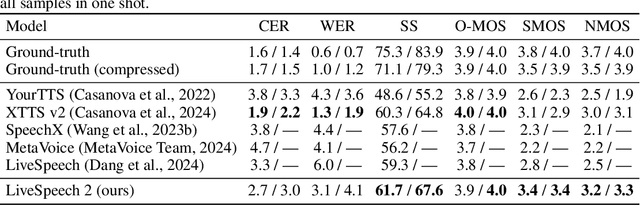

Existing zero-shot text-to-speech (TTS) systems are typically designed to process complete sentences and are constrained by the maximum duration for which they have been trained. However, in many streaming applications, texts arrive continuously in short chunks, necessitating instant responses from the system. We identify the essential capabilities required for chunk-level streaming and introduce LiveSpeech 2, a stream-aware model that supports infinitely long speech generation, text-audio stream synchronization, and seamless transitions between short speech chunks. To achieve these, we propose (1) adopting Mamba, a class of sequence modeling distinguished by linear-time decoding, which is augmented by cross-attention mechanisms for conditioning, (2) utilizing rotary positional embeddings in the computation of cross-attention, enabling the model to process an infinite text stream by sliding a window, and (3) decoding with semantic guidance, a technique that aligns speech with the transcript during inference with minimal overhead. Experimental results demonstrate that our models are competitive with state-of-the-art language model-based zero-shot TTS models, while also providing flexibility to support a wide range of streaming scenarios.
SPLAT: A framework for optimised GPU code-generation for SParse reguLar ATtention
Jul 23, 2024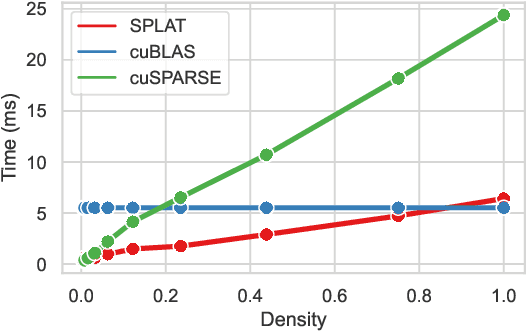
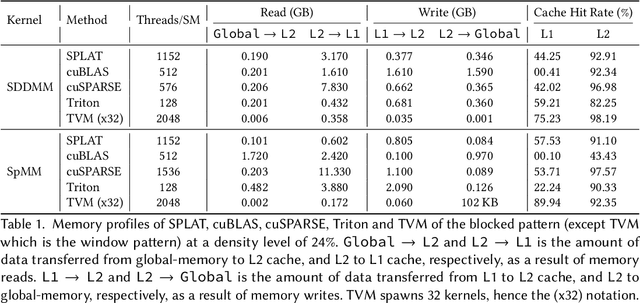

Multi-head-self-attention (MHSA) mechanisms achieve state-of-the-art (SOTA) performance across natural language processing and vision tasks. However, their quadratic dependence on sequence lengths has bottlenecked inference speeds. To circumvent this bottleneck, researchers have proposed various sparse-MHSA models, where a subset of full attention is computed. Despite their promise, current sparse libraries and compilers do not support high-performance implementations for diverse sparse-MHSA patterns due to the underlying sparse formats they operate on. These formats, which are typically designed for high-performance & scientific computing applications, are either curated for extreme amounts of random sparsity (<1% non-zero values), or specific sparsity patterns. However, the sparsity patterns in sparse-MHSA are moderately sparse (10-50% non-zero values) and varied, resulting in existing sparse-formats trading off generality for performance. We bridge this gap, achieving both generality and performance, by proposing a novel sparse format: affine-compressed-sparse-row (ACSR) and supporting code-generation scheme, SPLAT, that generates high-performance implementations for diverse sparse-MHSA patterns on GPUs. Core to our proposed format and code generation algorithm is the observation that common sparse-MHSA patterns have uniquely regular geometric properties. These properties, which can be analyzed just-in-time, expose novel optimizations and tiling strategies that SPLAT exploits to generate high-performance implementations for diverse patterns. To demonstrate SPLAT's efficacy, we use it to generate code for various sparse-MHSA models, achieving geomean speedups of 2.05x and 4.05x over hand-written kernels written in triton and TVM respectively on A100 GPUs. Moreover, its interfaces are intuitive and easy to use with existing implementations of MHSA in JAX.
LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Jun 05, 2024
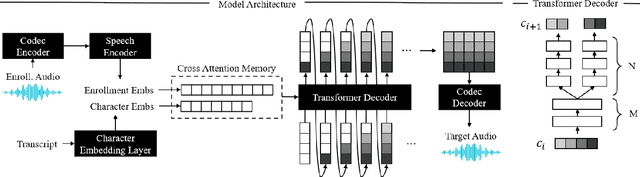
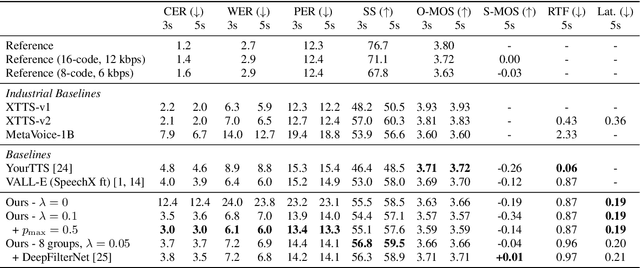
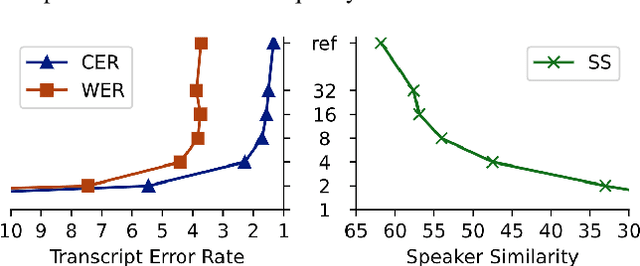
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.