 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUA-Skill: Develop Skills for Computer Using Agent
Jan 28, 2026Computer-Using Agents (CUAs) aim to autonomously operate computer systems to complete real-world tasks. However, existing agentic systems remain difficult to scale and lag behind human performance. A key limitation is the absence of reusable and structured skill abstractions that capture how humans interact with graphical user interfaces and how to leverage these skills. We introduce CUA-Skill, a computer-using agentic skill base that encodes human computer-use knowledge as skills coupled with parameterized execution and composition graphs. CUA-Skill is a large-scale library of carefully engineered skills spanning common Windows applications, serving as a practical infrastructure and tool substrate for scalable, reliable agent development. Built upon this skill base, we construct CUA-Skill Agent, an end-to-end computer-using agent that supports dynamic skill retrieval, argument instantiation, and memory-aware failure recovery. Our results demonstrate that CUA-Skill substantially improves execution success rates and robustness on challenging end-to-end agent benchmarks, establishing a strong foundation for future computer-using agent development. On WindowsAgentArena, CUA-Skill Agent achieves state-of-the-art 57.5% (best of three) successful rate while being significantly more efficient than prior and concurrent approaches. The project page is available at https://microsoft.github.io/cua_skill/.
Hierarchical Self-Attention: Generalizing Neural Attention Mechanics to Multi-Scale Problems
Sep 18, 2025



Transformers and their attention mechanism have been revolutionary in the field of Machine Learning. While originally proposed for the language data, they quickly found their way to the image, video, graph, etc. data modalities with various signal geometries. Despite this versatility, generalizing the attention mechanism to scenarios where data is presented at different scales from potentially different modalities is not straightforward. The attempts to incorporate hierarchy and multi-modality within transformers are largely based on ad hoc heuristics, which are not seamlessly generalizable to similar problems with potentially different structures. To address this problem, in this paper, we take a fundamentally different approach: we first propose a mathematical construct to represent multi-modal, multi-scale data. We then mathematically derive the neural attention mechanics for the proposed construct from the first principle of entropy minimization. We show that the derived formulation is optimal in the sense of being the closest to the standard Softmax attention while incorporating the inductive biases originating from the hierarchical/geometric information of the problem. We further propose an efficient algorithm based on dynamic programming to compute our derived attention mechanism. By incorporating it within transformers, we show that the proposed hierarchical attention mechanism not only can be employed to train transformer models in hierarchical/multi-modal settings from scratch, but it can also be used to inject hierarchical information into classical, pre-trained transformer models post training, resulting in more efficient models in zero-shot manner.
Instruction Agent: Enhancing Agent with Expert Demonstration
Sep 08, 2025Graphical user interface (GUI) agents have advanced rapidly but still struggle with complex tasks involving novel UI elements, long-horizon actions, and personalized trajectories. In this work, we introduce Instruction Agent, a GUI agent that leverages expert demonstrations to solve such tasks, enabling completion of otherwise difficult workflows. Given a single demonstration, the agent extracts step-by-step instructions and executes them by strictly following the trajectory intended by the user, which avoids making mistakes during execution. The agent leverages the verifier and backtracker modules further to improve robustness. Both modules are critical to understand the current outcome from each action and handle unexpected interruptions(such as pop-up windows) during execution. Our experiments show that Instruction Agent achieves a 60% success rate on a set of tasks in OSWorld that all top-ranked agents failed to complete. The Instruction Agent offers a practical and extensible framework, bridging the gap between current GUI agents and reliable real-world GUI task automation.
Automatic Joint Structured Pruning and Quantization for Efficient Neural Network Training and Compression
Feb 23, 2025Structured pruning and quantization are fundamental techniques used to reduce the size of deep neural networks (DNNs) and typically are applied independently. Applying these techniques jointly via co-optimization has the potential to produce smaller, high-quality models. However, existing joint schemes are not widely used because of (1) engineering difficulties (complicated multi-stage processes), (2) black-box optimization (extensive hyperparameter tuning to control the overall compression), and (3) insufficient architecture generalization. To address these limitations, we present the framework GETA, which automatically and efficiently performs joint structured pruning and quantization-aware training on any DNNs. GETA introduces three key innovations: (i) a quantization-aware dependency graph (QADG) that constructs a pruning search space for generic quantization-aware DNN, (ii) a partially projected stochastic gradient method that guarantees layerwise bit constraints are satisfied, and (iii) a new joint learning strategy that incorporates interpretable relationships between pruning and quantization. We present numerical experiments on both convolutional neural networks and transformer architectures that show that our approach achieves competitive (often superior) performance compared to existing joint pruning and quantization methods.
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
Oct 24, 2024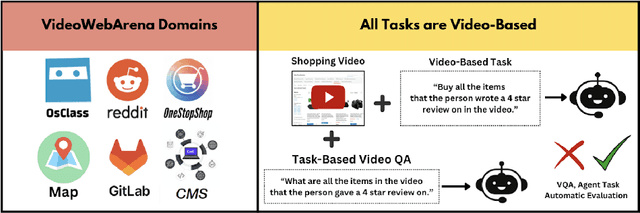
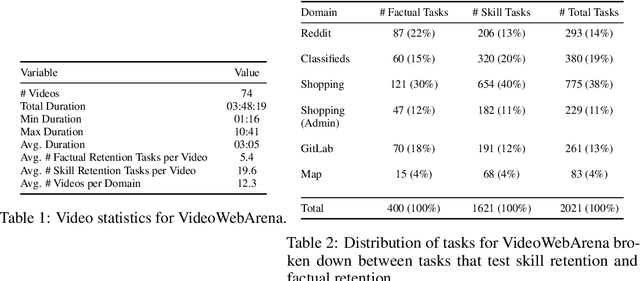
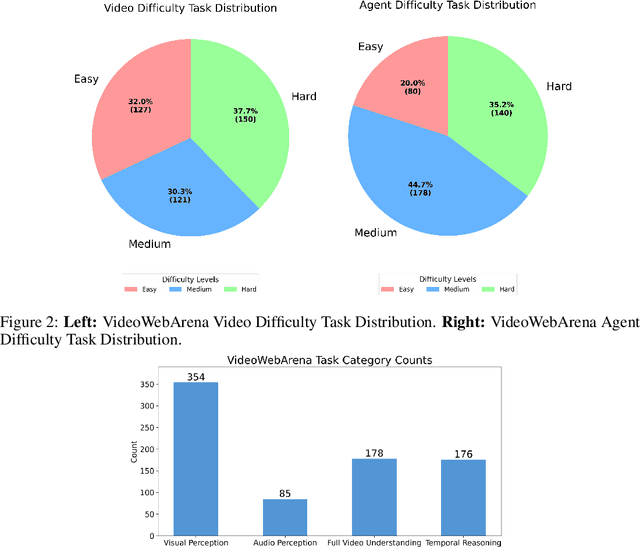
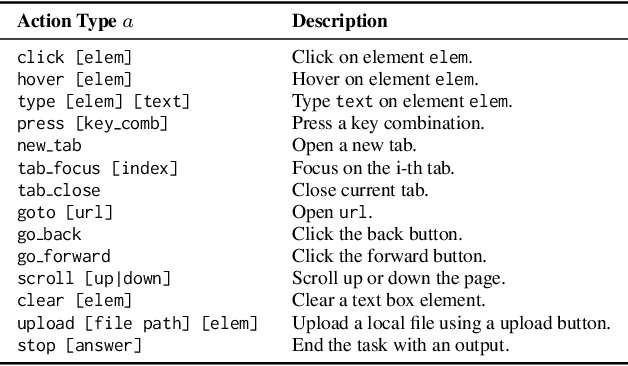
Videos are often used to learn or extract the necessary information to complete tasks in ways different than what text and static imagery alone can provide. However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs. To bridge this gap, we introduce VideoWebArena (VideoWA), a benchmark for evaluating the capabilities of long-context multimodal agents for video understanding. VideoWA consists of 2,021 web agent tasks based on manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demonstration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task. We find that the best model achieves 13.3% success on factual retention tasks and 45.8% on factual retention QA pairs, far below human performance at 73.9% and 79.3%, respectively. On skill retention tasks, long-context models perform worse with tutorials than without, exhibiting a 5% performance decrease in WebArena tasks and a 10.3% decrease in VisualWebArena tasks. Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
Zero-Shot Text-to-Speech from Continuous Text Streams
Oct 01, 2024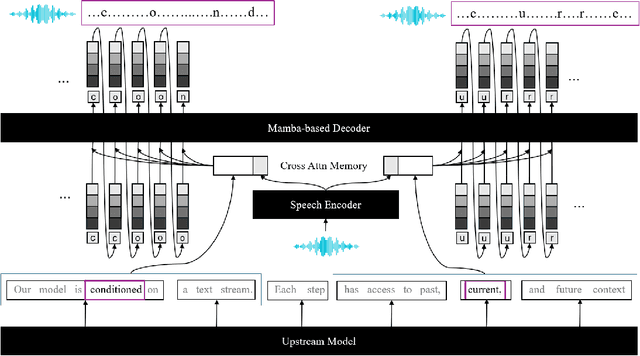

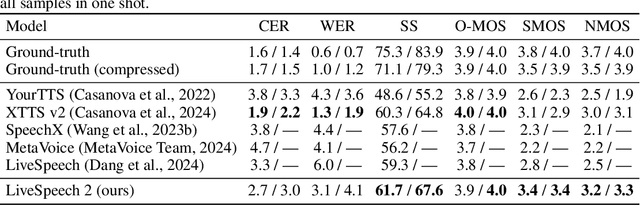

Existing zero-shot text-to-speech (TTS) systems are typically designed to process complete sentences and are constrained by the maximum duration for which they have been trained. However, in many streaming applications, texts arrive continuously in short chunks, necessitating instant responses from the system. We identify the essential capabilities required for chunk-level streaming and introduce LiveSpeech 2, a stream-aware model that supports infinitely long speech generation, text-audio stream synchronization, and seamless transitions between short speech chunks. To achieve these, we propose (1) adopting Mamba, a class of sequence modeling distinguished by linear-time decoding, which is augmented by cross-attention mechanisms for conditioning, (2) utilizing rotary positional embeddings in the computation of cross-attention, enabling the model to process an infinite text stream by sliding a window, and (3) decoding with semantic guidance, a technique that aligns speech with the transcript during inference with minimal overhead. Experimental results demonstrate that our models are competitive with state-of-the-art language model-based zero-shot TTS models, while also providing flexibility to support a wide range of streaming scenarios.
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
Sep 12, 2024
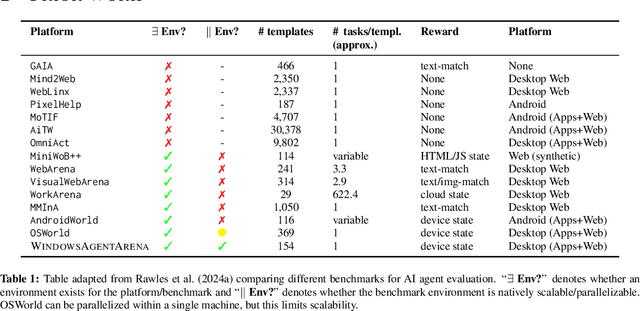

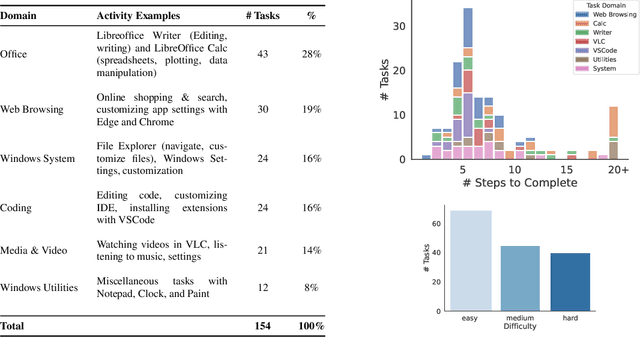
Large language models (LLMs) show remarkable potential to act as computer agents, enhancing human productivity and software accessibility in multi-modal tasks that require planning and reasoning. However, measuring agent performance in realistic environments remains a challenge since: (i) most benchmarks are limited to specific modalities or domains (e.g. text-only, web navigation, Q&A, coding) and (ii) full benchmark evaluations are slow (on order of magnitude of days) given the multi-step sequential nature of tasks. To address these challenges, we introduce the Windows Agent Arena: a reproducible, general environment focusing exclusively on the Windows operating system (OS) where agents can operate freely within a real Windows OS and use the same wide range of applications, tools, and web browsers available to human users when solving tasks. We adapt the OSWorld framework (Xie et al., 2024) to create 150+ diverse Windows tasks across representative domains that require agent abilities in planning, screen understanding, and tool usage. Our benchmark is scalable and can be seamlessly parallelized in Azure for a full benchmark evaluation in as little as 20 minutes. To demonstrate Windows Agent Arena's capabilities, we also introduce a new multi-modal agent, Navi. Our agent achieves a success rate of 19.5% in the Windows domain, compared to 74.5% performance of an unassisted human. Navi also demonstrates strong performance on another popular web-based benchmark, Mind2Web. We offer extensive quantitative and qualitative analysis of Navi's performance, and provide insights into the opportunities for future research in agent development and data generation using Windows Agent Arena. Webpage: https://microsoft.github.io/WindowsAgentArena Code: https://github.com/microsoft/WindowsAgentArena
LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Jun 05, 2024
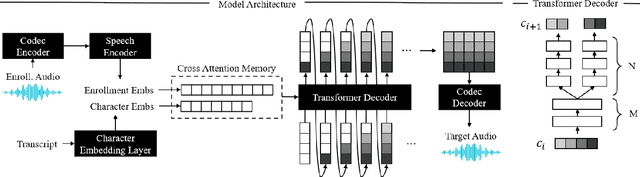
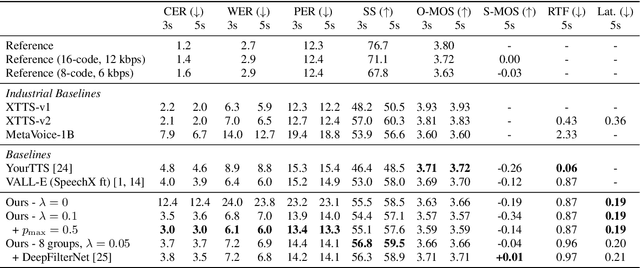
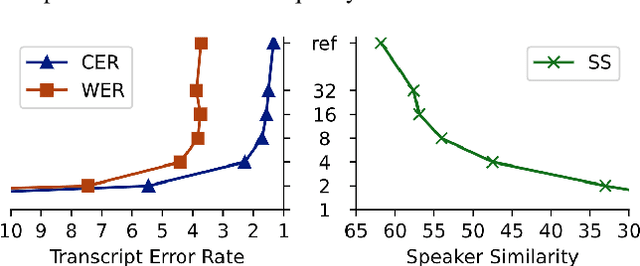
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Apr 02, 2024



Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
uaMix-MAE: Efficient Tuning of Pretrained Audio Transformers with Unsupervised Audio Mixtures
Mar 14, 2024Masked Autoencoders (MAEs) learn rich low-level representations from unlabeled data but require substantial labeled data to effectively adapt to downstream tasks. Conversely, Instance Discrimination (ID) emphasizes high-level semantics, offering a potential solution to alleviate annotation requirements in MAEs. Although combining these two approaches can address downstream tasks with limited labeled data, naively integrating ID into MAEs leads to extended training times and high computational costs. To address this challenge, we introduce uaMix-MAE, an efficient ID tuning strategy that leverages unsupervised audio mixtures. Utilizing contrastive tuning, uaMix-MAE aligns the representations of pretrained MAEs, thereby facilitating effective adaptation to task-specific semantics. To optimize the model with small amounts of unlabeled data, we propose an audio mixing technique that manipulates audio samples in both input and virtual label spaces. Experiments in low/few-shot settings demonstrate that \modelname achieves 4-6% accuracy improvements over various benchmarks when tuned with limited unlabeled data, such as AudioSet-20K. Code is available at https://github.com/PLAN-Lab/uamix-MAE