 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoLoRA: Composable Specialization via Per-Token Adapter Routing
Mar 16, 2026Multi-adapter serving systems route entire sequences to a single adapter, forcing a choice when requests span multiple domains. This assumption fails in two important settings: (1) multimodal generation, where text and image tokens require different adapters within the same sequence, and (2) mixed-capability requests like "write code to solve this equation," which need expertise from multiple specialized adapters. We introduce per-token routing, which routes individual tokens to adapters based on either vocabulary structure (for multimodal models) or learned gating (for semantic specialization). Per-token routing is provably optimal, achieving work N for N tokens versus K \cdot N for per-sequence routing with K adapter types. Our key contribution is MoLoRA (Mixture of LoRA), which enables composable specialization: load multiple domain-specific adapters and let a learned router select the appropriate adapter per-token. We demonstrate that specialization dramatically beats scale: MoLoRA enables Qwen3-1.7B to exceed Qwen3-8B across four reasoning benchmarks while being 4.7x smaller. This enables modular expertise at inference time: train focused LoRAs independently, combine them without retraining, and add new capabilities by simply loading new adapters.
CUA-Skill: Develop Skills for Computer Using Agent
Jan 28, 2026Computer-Using Agents (CUAs) aim to autonomously operate computer systems to complete real-world tasks. However, existing agentic systems remain difficult to scale and lag behind human performance. A key limitation is the absence of reusable and structured skill abstractions that capture how humans interact with graphical user interfaces and how to leverage these skills. We introduce CUA-Skill, a computer-using agentic skill base that encodes human computer-use knowledge as skills coupled with parameterized execution and composition graphs. CUA-Skill is a large-scale library of carefully engineered skills spanning common Windows applications, serving as a practical infrastructure and tool substrate for scalable, reliable agent development. Built upon this skill base, we construct CUA-Skill Agent, an end-to-end computer-using agent that supports dynamic skill retrieval, argument instantiation, and memory-aware failure recovery. Our results demonstrate that CUA-Skill substantially improves execution success rates and robustness on challenging end-to-end agent benchmarks, establishing a strong foundation for future computer-using agent development. On WindowsAgentArena, CUA-Skill Agent achieves state-of-the-art 57.5% (best of three) successful rate while being significantly more efficient than prior and concurrent approaches. The project page is available at https://microsoft.github.io/cua_skill/.
Instruction Agent: Enhancing Agent with Expert Demonstration
Sep 08, 2025Graphical user interface (GUI) agents have advanced rapidly but still struggle with complex tasks involving novel UI elements, long-horizon actions, and personalized trajectories. In this work, we introduce Instruction Agent, a GUI agent that leverages expert demonstrations to solve such tasks, enabling completion of otherwise difficult workflows. Given a single demonstration, the agent extracts step-by-step instructions and executes them by strictly following the trajectory intended by the user, which avoids making mistakes during execution. The agent leverages the verifier and backtracker modules further to improve robustness. Both modules are critical to understand the current outcome from each action and handle unexpected interruptions(such as pop-up windows) during execution. Our experiments show that Instruction Agent achieves a 60% success rate on a set of tasks in OSWorld that all top-ranked agents failed to complete. The Instruction Agent offers a practical and extensible framework, bridging the gap between current GUI agents and reliable real-world GUI task automation.
Phi-Ground Tech Report: Advancing Perception in GUI Grounding
Jul 31, 2025



With the development of multimodal reasoning models, Computer Use Agents (CUAs), akin to Jarvis from \textit{"Iron Man"}, are becoming a reality. GUI grounding is a core component for CUAs to execute actual actions, similar to mechanical control in robotics, and it directly leads to the success or failure of the system. It determines actions such as clicking and typing, as well as related parameters like the coordinates for clicks. Current end-to-end grounding models still achieve less than 65\% accuracy on challenging benchmarks like ScreenSpot-pro and UI-Vision, indicating they are far from being ready for deployment. % , as a single misclick can result in unacceptable consequences. In this work, we conduct an empirical study on the training of grounding models, examining details from data collection to model training. Ultimately, we developed the \textbf{Phi-Ground} model family, which achieves state-of-the-art performance across all five grounding benchmarks for models under $10B$ parameters in agent settings. In the end-to-end model setting, our model still achieves SOTA results with scores of \textit{\textbf{43.2}} on ScreenSpot-pro and \textit{\textbf{27.2}} on UI-Vision. We believe that the various details discussed in this paper, along with our successes and failures, not only clarify the construction of grounding models but also benefit other perception tasks. Project homepage: \href{https://zhangmiaosen2000.github.io/Phi-Ground/}{https://zhangmiaosen2000.github.io/Phi-Ground/}
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
Sep 12, 2024
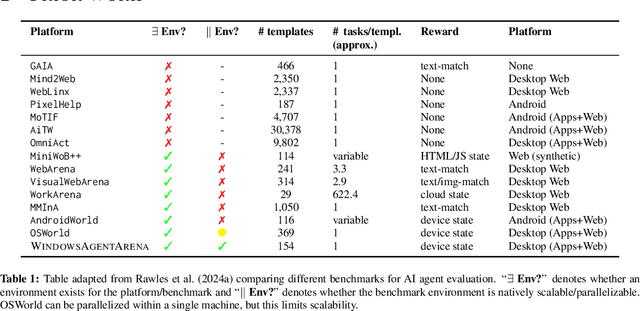

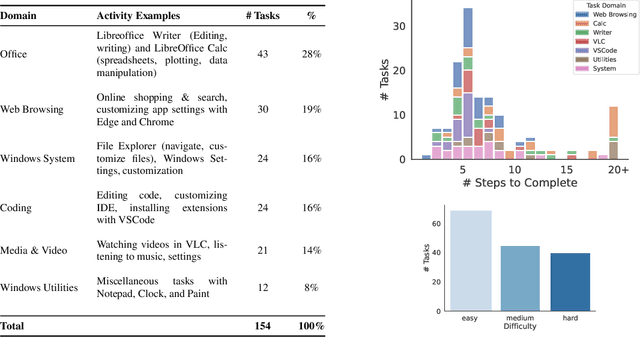
Large language models (LLMs) show remarkable potential to act as computer agents, enhancing human productivity and software accessibility in multi-modal tasks that require planning and reasoning. However, measuring agent performance in realistic environments remains a challenge since: (i) most benchmarks are limited to specific modalities or domains (e.g. text-only, web navigation, Q&A, coding) and (ii) full benchmark evaluations are slow (on order of magnitude of days) given the multi-step sequential nature of tasks. To address these challenges, we introduce the Windows Agent Arena: a reproducible, general environment focusing exclusively on the Windows operating system (OS) where agents can operate freely within a real Windows OS and use the same wide range of applications, tools, and web browsers available to human users when solving tasks. We adapt the OSWorld framework (Xie et al., 2024) to create 150+ diverse Windows tasks across representative domains that require agent abilities in planning, screen understanding, and tool usage. Our benchmark is scalable and can be seamlessly parallelized in Azure for a full benchmark evaluation in as little as 20 minutes. To demonstrate Windows Agent Arena's capabilities, we also introduce a new multi-modal agent, Navi. Our agent achieves a success rate of 19.5% in the Windows domain, compared to 74.5% performance of an unassisted human. Navi also demonstrates strong performance on another popular web-based benchmark, Mind2Web. We offer extensive quantitative and qualitative analysis of Navi's performance, and provide insights into the opportunities for future research in agent development and data generation using Windows Agent Arena. Webpage: https://microsoft.github.io/WindowsAgentArena Code: https://github.com/microsoft/WindowsAgentArena
One of these Things is Not Like the Others
May 22, 2020
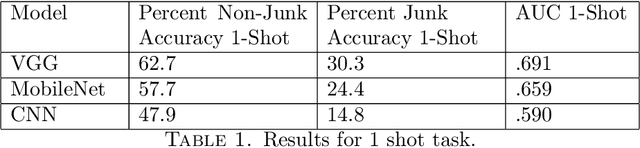
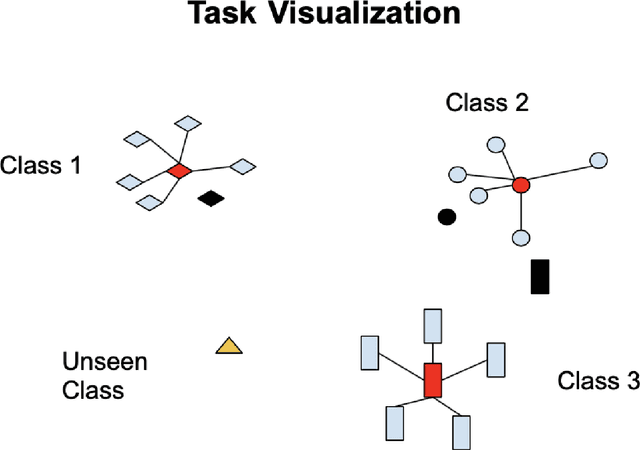
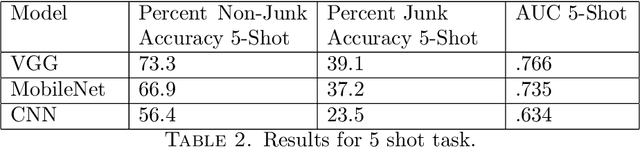
To perform well, most deep learning based image classification systems require large amounts of data and computing resources. These constraints make it difficult to quickly personalize to individual users or train models outside of fairly powerful machines. To deal with these problems, there has been a large body of research into teaching machines to learn to classify images based on only a handful of training examples, a field known as few-shot learning. Few-shot learning research traditionally makes the simplifying assumption that all images belong to one of a fixed number of previously seen groups. However, many image datasets, such as a camera roll on a phone, will be noisy and contain images that may not be relevant or fit into any clear group. We propose a model which can both classify new images based on a small number of examples and recognize images which do not belong to any previously seen group. We adapt previous few-shot learning work to include a simple mechanism for learning a cutoff that determines whether an image should be excluded or classified. We examine how well our method performs in a realistic setting, benchmarking the approach on a noisy and ambiguous dataset of images. We evaluate performance over a spectrum of model architectures, including setups small enough to be run on low powered devices, such as mobile phones or web browsers. We find that this task of excluding irrelevant images poses significant extra difficulty beyond that of the traditional few-shot task. We decompose the sources of this error, and suggest future improvements that might alleviate this difficulty.
Sometimes You Want to Go Where Everybody Knows your Name
Jan 30, 2018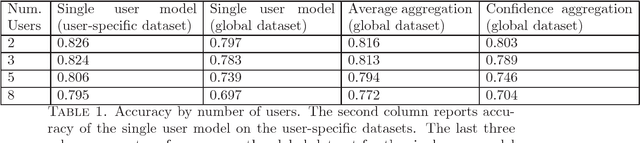
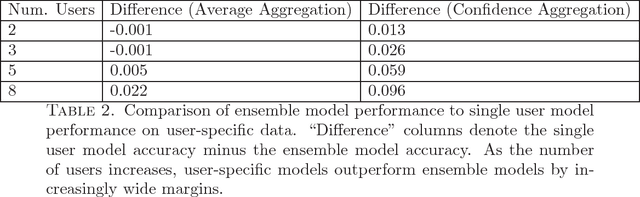
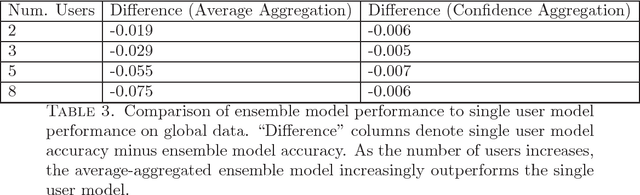
We introduce a new metric for measuring how well a model personalizes to a user's specific preferences. We define personalization as a weighting between performance on user specific data and performance on a more general global dataset that represents many different users. This global term serves as a form of regularization that forces us to not overfit to individual users who have small amounts of data. In order to protect user privacy, we add the constraint that we may not centralize or share user data. We also contribute a simple experiment in which we simulate classifying sentiment for users with very distinct vocabularies. This experiment functions as an example of the tension between doing well globally on all users, and doing well on any specific individual user. It also provides a concrete example of how to employ our new metric to help reason about and resolve this tension. We hope this work can help frame and ground future work into personalization.