 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-class segmentation under severe class imbalance: A case study in roof damage assessment
Oct 14, 2020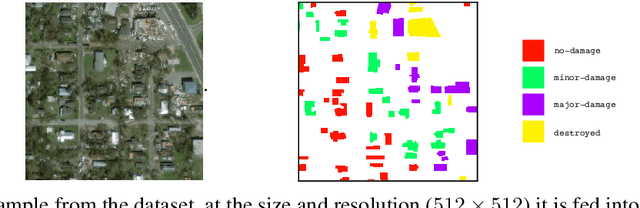



The task of roof damage classification and segmentation from overhead imagery presents unique challenges. In this work we choose to address the challenge posed due to strong class imbalance. We propose four distinct techniques that aim at mitigating this problem. Through a new scheme that feeds the data to the network by oversampling the minority classes, and three other network architectural improvements, we manage to boost the macro-averaged F1-score of a model by 39.9 percentage points, thus achieving improved segmentation performance, especially on the minority classes.
One of these Things is Not Like the Others
May 22, 2020
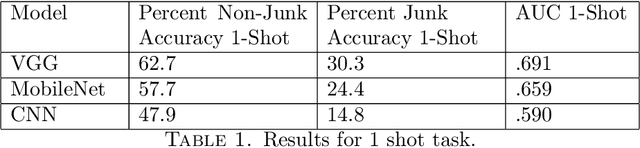
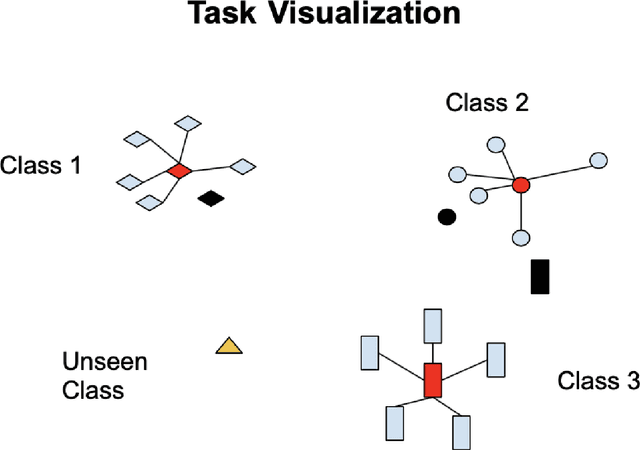
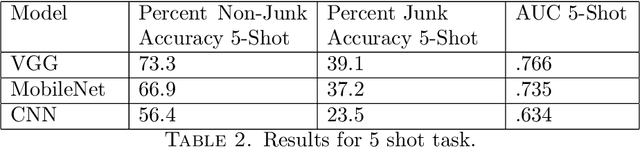
To perform well, most deep learning based image classification systems require large amounts of data and computing resources. These constraints make it difficult to quickly personalize to individual users or train models outside of fairly powerful machines. To deal with these problems, there has been a large body of research into teaching machines to learn to classify images based on only a handful of training examples, a field known as few-shot learning. Few-shot learning research traditionally makes the simplifying assumption that all images belong to one of a fixed number of previously seen groups. However, many image datasets, such as a camera roll on a phone, will be noisy and contain images that may not be relevant or fit into any clear group. We propose a model which can both classify new images based on a small number of examples and recognize images which do not belong to any previously seen group. We adapt previous few-shot learning work to include a simple mechanism for learning a cutoff that determines whether an image should be excluded or classified. We examine how well our method performs in a realistic setting, benchmarking the approach on a noisy and ambiguous dataset of images. We evaluate performance over a spectrum of model architectures, including setups small enough to be run on low powered devices, such as mobile phones or web browsers. We find that this task of excluding irrelevant images poses significant extra difficulty beyond that of the traditional few-shot task. We decompose the sources of this error, and suggest future improvements that might alleviate this difficulty.
Sometimes You Want to Go Where Everybody Knows your Name
Jan 30, 2018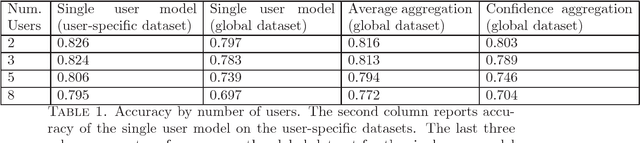
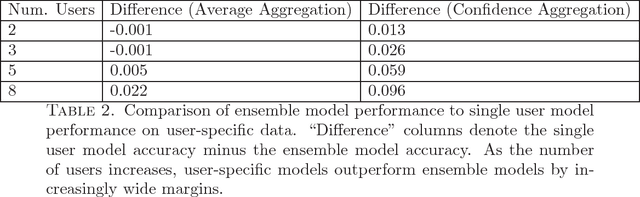
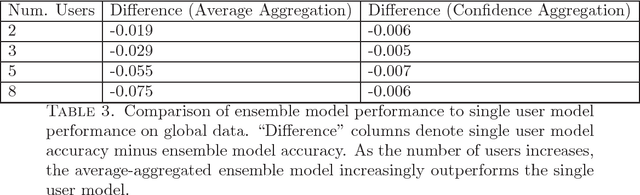
We introduce a new metric for measuring how well a model personalizes to a user's specific preferences. We define personalization as a weighting between performance on user specific data and performance on a more general global dataset that represents many different users. This global term serves as a form of regularization that forces us to not overfit to individual users who have small amounts of data. In order to protect user privacy, we add the constraint that we may not centralize or share user data. We also contribute a simple experiment in which we simulate classifying sentiment for users with very distinct vocabularies. This experiment functions as an example of the tension between doing well globally on all users, and doing well on any specific individual user. It also provides a concrete example of how to employ our new metric to help reason about and resolve this tension. We hope this work can help frame and ground future work into personalization.