 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne of these Things is Not Like the Others
Paper and Code
May 22, 2020
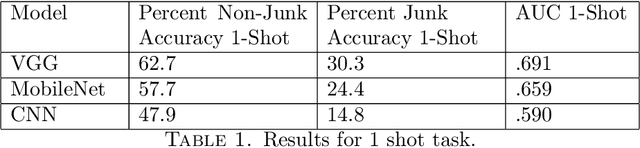
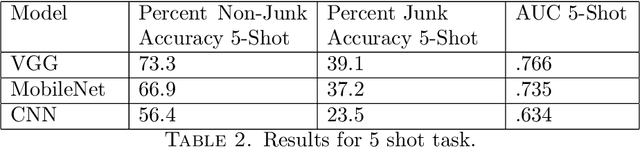
To perform well, most deep learning based image classification systems require large amounts of data and computing resources. These constraints make it difficult to quickly personalize to individual users or train models outside of fairly powerful machines. To deal with these problems, there has been a large body of research into teaching machines to learn to classify images based on only a handful of training examples, a field known as few-shot learning. Few-shot learning research traditionally makes the simplifying assumption that all images belong to one of a fixed number of previously seen groups. However, many image datasets, such as a camera roll on a phone, will be noisy and contain images that may not be relevant or fit into any clear group. We propose a model which can both classify new images based on a small number of examples and recognize images which do not belong to any previously seen group. We adapt previous few-shot learning work to include a simple mechanism for learning a cutoff that determines whether an image should be excluded or classified. We examine how well our method performs in a realistic setting, benchmarking the approach on a noisy and ambiguous dataset of images. We evaluate performance over a spectrum of model architectures, including setups small enough to be run on low powered devices, such as mobile phones or web browsers. We find that this task of excluding irrelevant images poses significant extra difficulty beyond that of the traditional few-shot task. We decompose the sources of this error, and suggest future improvements that might alleviate this difficulty.