 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSometimes You Want to Go Where Everybody Knows your Name
Paper and Code
Jan 30, 2018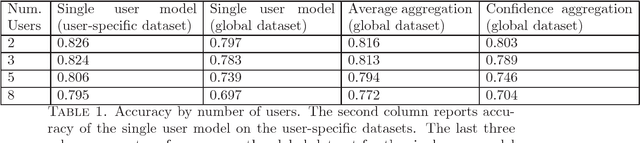
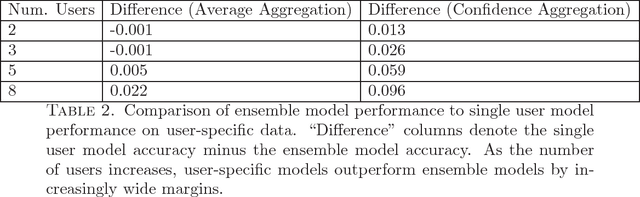
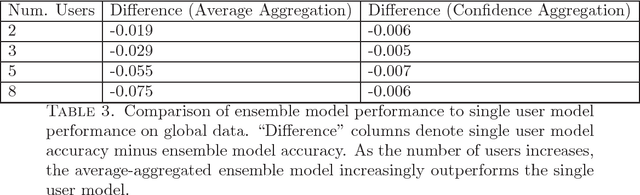
We introduce a new metric for measuring how well a model personalizes to a user's specific preferences. We define personalization as a weighting between performance on user specific data and performance on a more general global dataset that represents many different users. This global term serves as a form of regularization that forces us to not overfit to individual users who have small amounts of data. In order to protect user privacy, we add the constraint that we may not centralize or share user data. We also contribute a simple experiment in which we simulate classifying sentiment for users with very distinct vocabularies. This experiment functions as an example of the tension between doing well globally on all users, and doing well on any specific individual user. It also provides a concrete example of how to employ our new metric to help reason about and resolve this tension. We hope this work can help frame and ground future work into personalization.