 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Robot Policies with Visuomotor Language Guidance
Oct 10, 2024
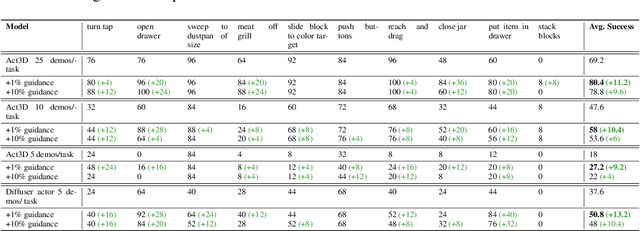


Recent advances in the fields of natural language processing and computer vision have shown great potential in understanding the underlying dynamics of the world from large-scale internet data. However, translating this knowledge into robotic systems remains an open challenge, given the scarcity of human-robot interactions and the lack of large-scale datasets of real-world robotic data. Previous robot learning approaches such as behavior cloning and reinforcement learning have shown great capabilities in learning robotic skills from human demonstrations or from scratch in specific environments. However, these approaches often require task-specific demonstrations or designing complex simulation environments, which limits the development of generalizable and robust policies for new settings. Aiming to address these limitations, we propose an agent-based framework for grounding robot policies to the current context, considering the constraints of a current robot and its environment using visuomotor-grounded language guidance. The proposed framework is composed of a set of conversational agents designed for specific roles -- namely, high-level advisor, visual grounding, monitoring, and robotic agents. Given a base policy, the agents collectively generate guidance at run time to shift the action distribution of the base policy towards more desirable future states. We demonstrate that our approach can effectively guide manipulation policies to achieve significantly higher success rates both in simulation and in real-world experiments without the need for additional human demonstrations or extensive exploration. Project videos at https://sites.google.com/view/motorcortex/home.
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
Sep 12, 2024
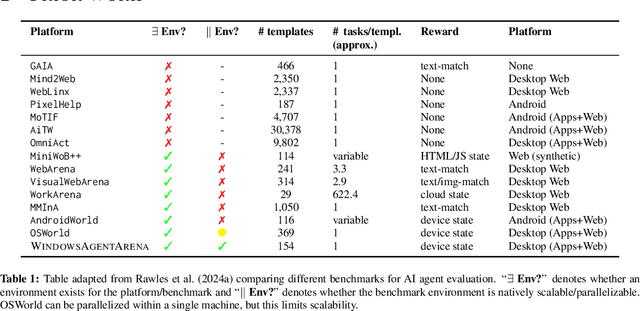

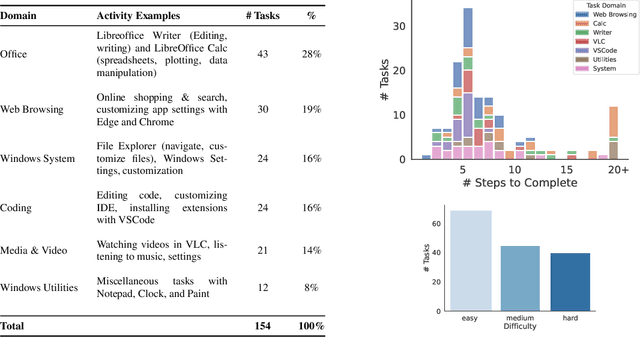
Large language models (LLMs) show remarkable potential to act as computer agents, enhancing human productivity and software accessibility in multi-modal tasks that require planning and reasoning. However, measuring agent performance in realistic environments remains a challenge since: (i) most benchmarks are limited to specific modalities or domains (e.g. text-only, web navigation, Q&A, coding) and (ii) full benchmark evaluations are slow (on order of magnitude of days) given the multi-step sequential nature of tasks. To address these challenges, we introduce the Windows Agent Arena: a reproducible, general environment focusing exclusively on the Windows operating system (OS) where agents can operate freely within a real Windows OS and use the same wide range of applications, tools, and web browsers available to human users when solving tasks. We adapt the OSWorld framework (Xie et al., 2024) to create 150+ diverse Windows tasks across representative domains that require agent abilities in planning, screen understanding, and tool usage. Our benchmark is scalable and can be seamlessly parallelized in Azure for a full benchmark evaluation in as little as 20 minutes. To demonstrate Windows Agent Arena's capabilities, we also introduce a new multi-modal agent, Navi. Our agent achieves a success rate of 19.5% in the Windows domain, compared to 74.5% performance of an unassisted human. Navi also demonstrates strong performance on another popular web-based benchmark, Mind2Web. We offer extensive quantitative and qualitative analysis of Navi's performance, and provide insights into the opportunities for future research in agent development and data generation using Windows Agent Arena. Webpage: https://microsoft.github.io/WindowsAgentArena Code: https://github.com/microsoft/WindowsAgentArena
LaTTe: Language Trajectory TransformEr
Aug 09, 2022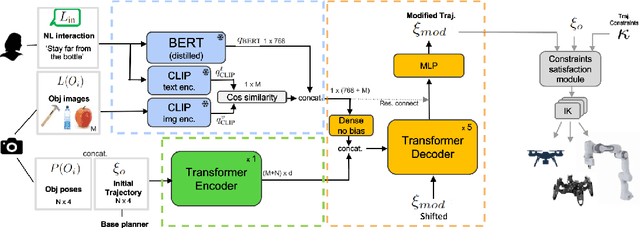
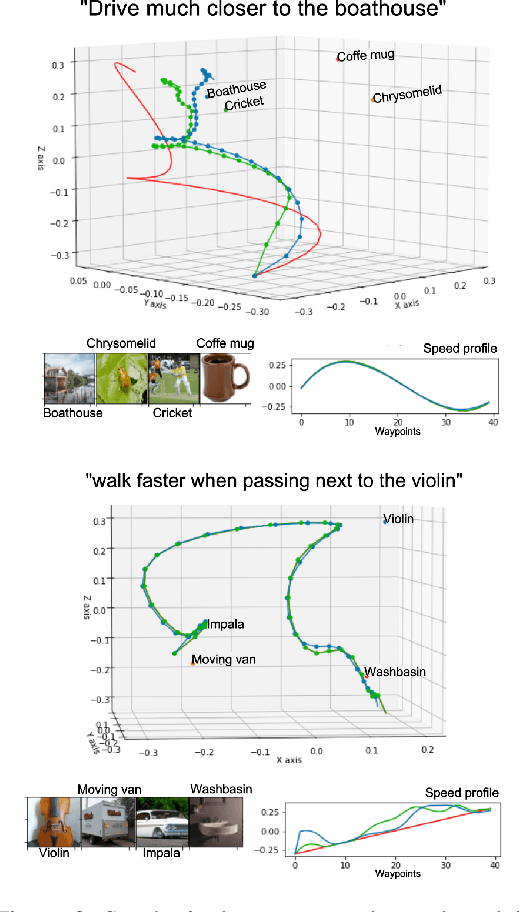

Natural language is one of the most intuitive ways to express human intent. However, translating instructions and commands towards robotic motion generation, and deployment in the real world, is far from being an easy task. Indeed, combining robotic's inherent low-level geometric and kinodynamic constraints with human's high-level semantic information reinvigorates and raises new challenges to the task-design problem -- typically leading to task or hardware specific solutions with a static set of action targets and commands. This work instead proposes a flexible language-based framework that allows to modify generic 3D robotic trajectories using language commands with reduced constraints about prior task or robot information. By taking advantage of pre-trained language models, we employ an auto-regressive transformer to map natural language inputs and contextual images into changes in 3D trajectories. We show through simulations and real-life experiments that the model can successfully follow human intent, modifying the shape and speed of trajectories for multiple robotic platforms and contexts. This study takes a step into building large pre-trained foundational models for robotics and shows how such models can create more intuitive and flexible interactions between human and machines. Codebase available at: https://github.com/arthurfenderbucker/NL_trajectory_reshaper.
Reshaping Robot Trajectories Using Natural Language Commands: A Study of Multi-Modal Data Alignment Using Transformers
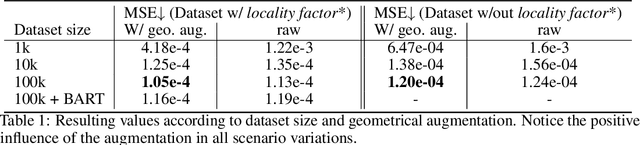
Mar 25, 2022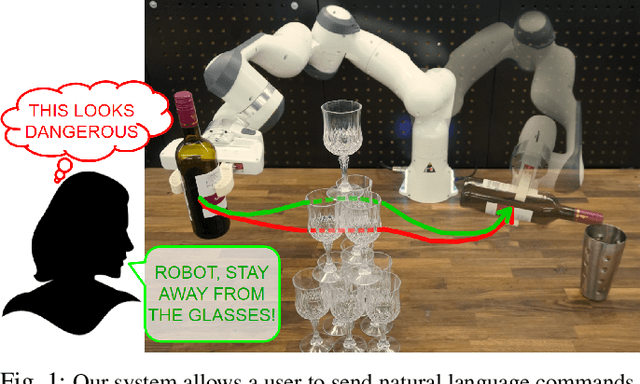
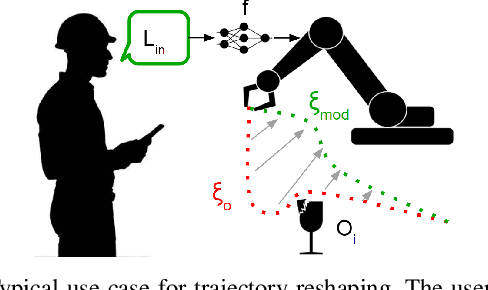
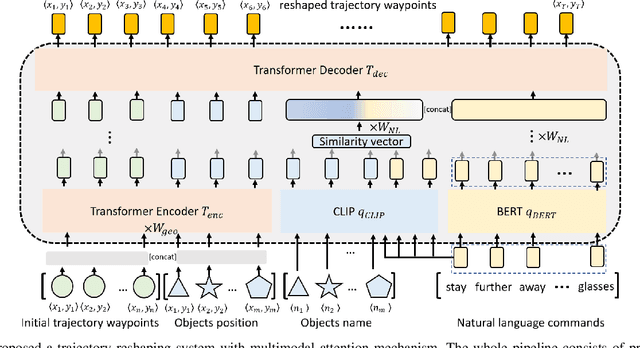
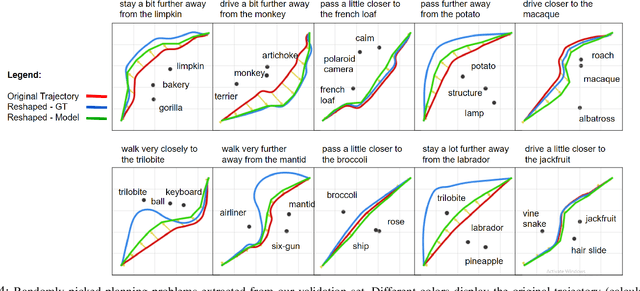
Natural language is the most intuitive medium for us to interact with other people when expressing commands and instructions. However, using language is seldom an easy task when humans need to express their intent towards robots, since most of the current language interfaces require rigid templates with a static set of action targets and commands. In this work, we provide a flexible language-based interface for human-robot collaboration, which allows a user to reshape existing trajectories for an autonomous agent. We take advantage of recent advancements in the field of large language models (BERT and CLIP) to encode the user command, and then combine these features with trajectory information using multi-modal attention transformers. We train the model using imitation learning over a dataset containing robot trajectories modified by language commands, and treat the trajectory generation process as a sequence prediction problem, analogously to how language generation architectures operate. We evaluate the system in multiple simulated trajectory scenarios, and show a significant performance increase of our model over baseline approaches. In addition, our real-world experiments with a robot arm show that users significantly prefer our natural language interface over traditional methods such as kinesthetic teaching or cost-function programming. Our study shows how the field of robotics can take advantage of large pre-trained language models towards creating more intuitive interfaces between robots and machines. Project webpage: https://arthurfenderbucker.github.io/NL_trajectory_reshaper/
Batteries, camera, action! Learning a semantic control space for expressive robot cinematography
Nov 19, 2020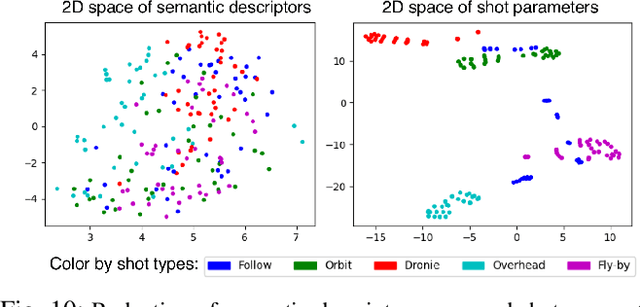

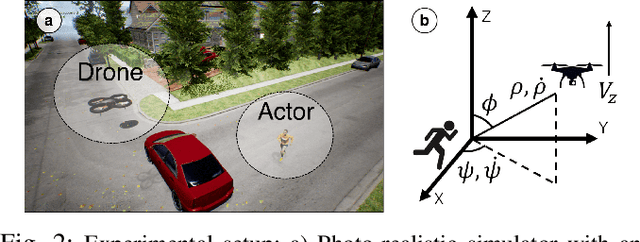
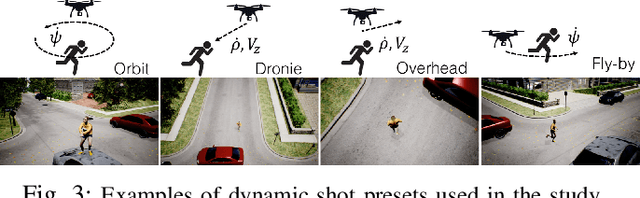
Aerial vehicles are revolutionizing the way film-makers can capture shots of actors by composing novel aerial and dynamic viewpoints. However, despite great advancements in autonomous flight technology, generating expressive camera behaviors is still a challenge and requires non-technical users to edit a large number of unintuitive control parameters. In this work we develop a data-driven framework that enables editing of these complex camera positioning parameters in a semantic space (e.g. calm, enjoyable, establishing). First, we generate a database of video clips with a diverse range of shots in a photo-realistic simulator, and use hundreds of participants in a crowd-sourcing framework to obtain scores for a set of semantic descriptors for each clip. Next, we analyze correlations between descriptors and build a semantic control space based on cinematography guidelines and human perception studies. Finally, we learn a generative model that can map a set of desired semantic video descriptors into low-level camera trajectory parameters. We evaluate our system by demonstrating that our model successfully generates shots that are rated by participants as having the expected degrees of expression for each descriptor. We also show that our models generalize to different scenes in both simulation and real-world experiments. Supplementary video: https://youtu.be/6WX2yEUE9_k
Do You See What I See? Coordinating Multiple Aerial Cameras for Robot Cinematography
Nov 10, 2020
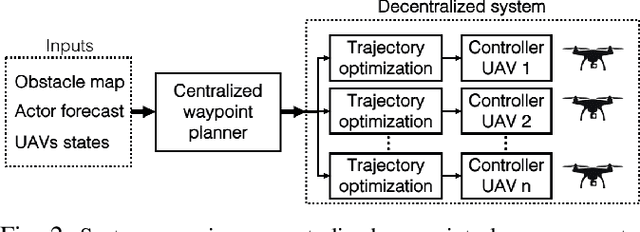
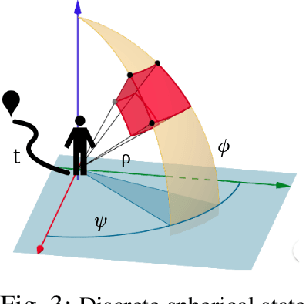

Aerial cinematography is significantly expanding the capabilities of film-makers. Recent progress in autonomous unmanned aerial vehicles (UAVs) has further increased the potential impact of aerial cameras, with systems that can safely track actors in unstructured cluttered environments. Professional productions, however, require the use of multiple cameras simultaneously to record different viewpoints of the same scene, which are edited into the final footage either in real time or in post-production. Such extreme motion coordination is particularly hard for unscripted action scenes, which are a common use case of aerial cameras. In this work we develop a real-time multi-UAV coordination system that is capable of recording dynamic targets while maximizing shot diversity and avoiding collisions and mutual visibility between cameras. We validate our approach in multiple cluttered environments of a photo-realistic simulator, and deploy the system using two UAVs in real-world experiments. We show that our coordination scheme has low computational cost and takes only 1.17 ms on average to plan for a team of 3 UAVs over a 10 s time horizon. Supplementary video: https://youtu.be/m2R3anv2ADE