 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
Oct 24, 2024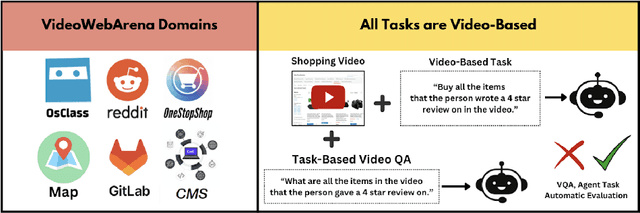
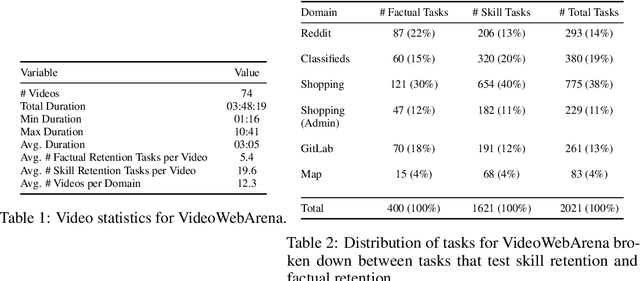
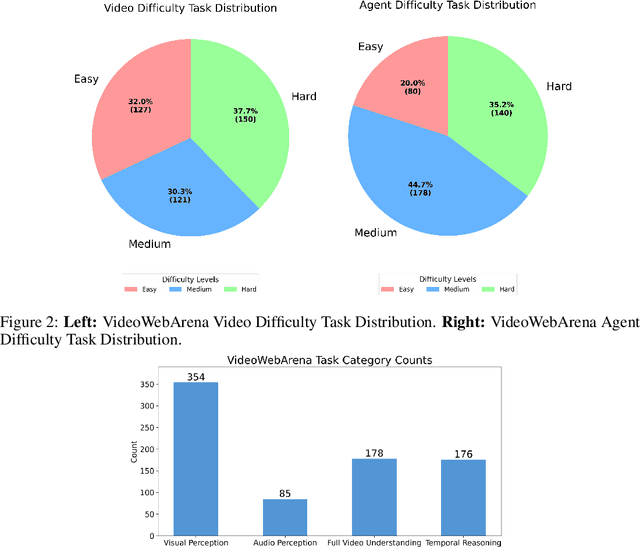
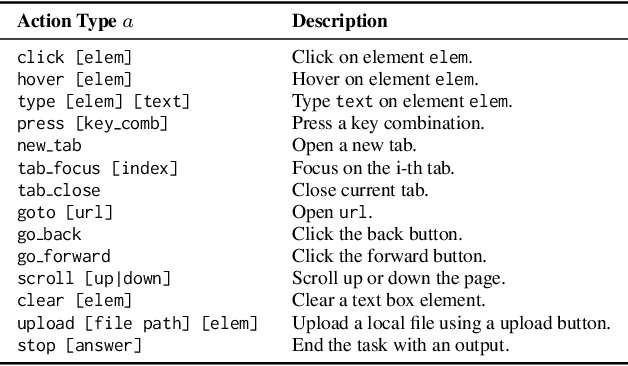
Videos are often used to learn or extract the necessary information to complete tasks in ways different than what text and static imagery alone can provide. However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs. To bridge this gap, we introduce VideoWebArena (VideoWA), a benchmark for evaluating the capabilities of long-context multimodal agents for video understanding. VideoWA consists of 2,021 web agent tasks based on manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demonstration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task. We find that the best model achieves 13.3% success on factual retention tasks and 45.8% on factual retention QA pairs, far below human performance at 73.9% and 79.3%, respectively. On skill retention tasks, long-context models perform worse with tutorials than without, exhibiting a 5% performance decrease in WebArena tasks and a 10.3% decrease in VisualWebArena tasks. Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
Sep 12, 2024
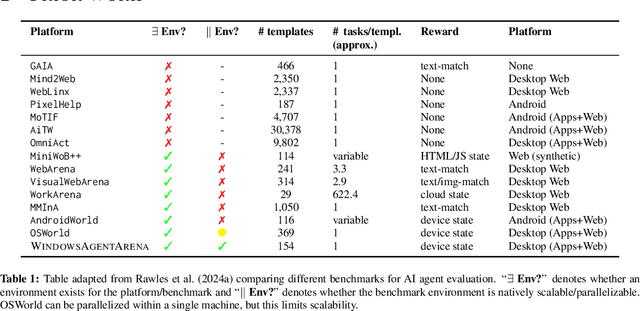

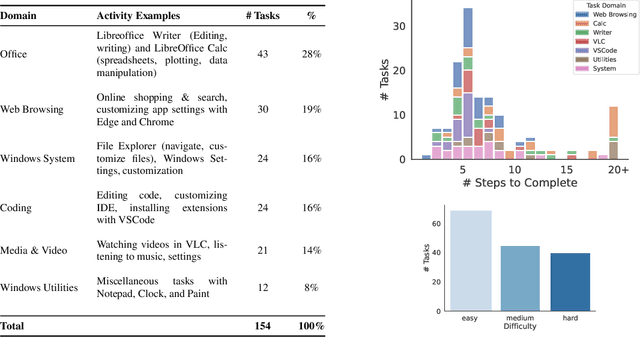
Large language models (LLMs) show remarkable potential to act as computer agents, enhancing human productivity and software accessibility in multi-modal tasks that require planning and reasoning. However, measuring agent performance in realistic environments remains a challenge since: (i) most benchmarks are limited to specific modalities or domains (e.g. text-only, web navigation, Q&A, coding) and (ii) full benchmark evaluations are slow (on order of magnitude of days) given the multi-step sequential nature of tasks. To address these challenges, we introduce the Windows Agent Arena: a reproducible, general environment focusing exclusively on the Windows operating system (OS) where agents can operate freely within a real Windows OS and use the same wide range of applications, tools, and web browsers available to human users when solving tasks. We adapt the OSWorld framework (Xie et al., 2024) to create 150+ diverse Windows tasks across representative domains that require agent abilities in planning, screen understanding, and tool usage. Our benchmark is scalable and can be seamlessly parallelized in Azure for a full benchmark evaluation in as little as 20 minutes. To demonstrate Windows Agent Arena's capabilities, we also introduce a new multi-modal agent, Navi. Our agent achieves a success rate of 19.5% in the Windows domain, compared to 74.5% performance of an unassisted human. Navi also demonstrates strong performance on another popular web-based benchmark, Mind2Web. We offer extensive quantitative and qualitative analysis of Navi's performance, and provide insights into the opportunities for future research in agent development and data generation using Windows Agent Arena. Webpage: https://microsoft.github.io/WindowsAgentArena Code: https://github.com/microsoft/WindowsAgentArena
EvDNeRF: Reconstructing Event Data with Dynamic Neural Radiance Fields
Oct 03, 2023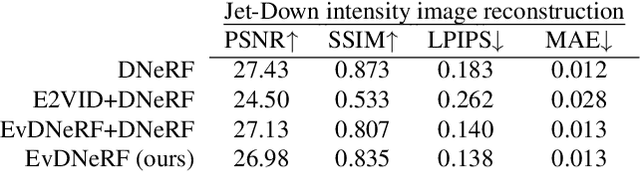


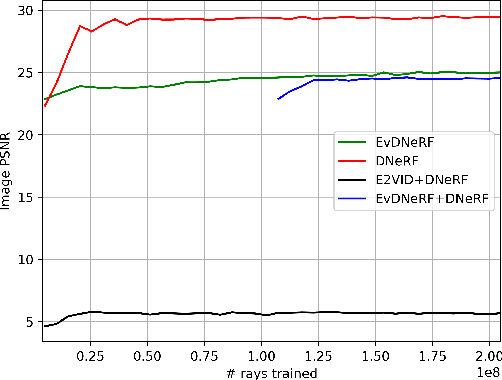
We present EvDNeRF, a pipeline for generating event data and training an event-based dynamic NeRF, for the purpose of faithfully reconstructing eventstreams on scenes with rigid and non-rigid deformations that may be too fast to capture with a standard camera. Event cameras register asynchronous per-pixel brightness changes at MHz rates with high dynamic range, making them ideal for observing fast motion with almost no motion blur. Neural radiance fields (NeRFs) offer visual-quality geometric-based learnable rendering, but prior work with events has only considered reconstruction of static scenes. Our EvDNeRF can predict eventstreams of dynamic scenes from a static or moving viewpoint between any desired timestamps, thereby allowing it to be used as an event-based simulator for a given scene. We show that by training on varied batch sizes of events, we can improve test-time predictions of events at fine time resolutions, outperforming baselines that pair standard dynamic NeRFs with event simulators. We release our simulated and real datasets, as well as code for both event-based data generation and the training of event-based dynamic NeRF models (https://github.com/anish-bhattacharya/EvDNeRF).
Is Imitation All You Need? Generalized Decision-Making with Dual-Phase Training
Jul 18, 2023



We introduce DualMind, a generalist agent designed to tackle various decision-making tasks that addresses challenges posed by current methods, such as overfitting behaviors and dependence on task-specific fine-tuning. DualMind uses a novel "Dual-phase" training strategy that emulates how humans learn to act in the world. The model first learns fundamental common knowledge through a self-supervised objective tailored for control tasks and then learns how to make decisions based on different contexts through imitating behaviors conditioned on given prompts. DualMind can handle tasks across domains, scenes, and embodiments using just a single set of model weights and can execute zero-shot prompting without requiring task-specific fine-tuning. We evaluate DualMind on MetaWorld and Habitat through extensive experiments and demonstrate its superior generalizability compared to previous techniques, outperforming other generalist agents by over 50$\%$ and 70$\%$ on Habitat and MetaWorld, respectively. On the 45 tasks in MetaWorld, DualMind achieves over 30 tasks at a 90$\%$ success rate.
ConBaT: Control Barrier Transformer for Safe Policy Learning
Mar 07, 2023Large-scale self-supervised models have recently revolutionized our ability to perform a variety of tasks within the vision and language domains. However, using such models for autonomous systems is challenging because of safety requirements: besides executing correct actions, an autonomous agent must also avoid the high cost and potentially fatal critical mistakes. Traditionally, self-supervised training mainly focuses on imitating previously observed behaviors, and the training demonstrations carry no notion of which behaviors should be explicitly avoided. In this work, we propose Control Barrier Transformer (ConBaT), an approach that learns safe behaviors from demonstrations in a self-supervised fashion. ConBaT is inspired by the concept of control barrier functions in control theory and uses a causal transformer that learns to predict safe robot actions autoregressively using a critic that requires minimal safety data labeling. During deployment, we employ a lightweight online optimization to find actions that ensure future states lie within the learned safe set. We apply our approach to different simulated control tasks and show that our method results in safer control policies compared to other classical and learning-based methods such as imitation learning, reinforcement learning, and model predictive control.
SMART: Self-supervised Multi-task pretrAining with contRol Transformers
Jan 24, 2023



Self-supervised pretraining has been extensively studied in language and vision domains, where a unified model can be easily adapted to various downstream tasks by pretraining representations without explicit labels. When it comes to sequential decision-making tasks, however, it is difficult to properly design such a pretraining approach that can cope with both high-dimensional perceptual information and the complexity of sequential control over long interaction horizons. The challenge becomes combinatorially more complex if we want to pretrain representations amenable to a large variety of tasks. To tackle this problem, in this work, we formulate a general pretraining-finetuning pipeline for sequential decision making, under which we propose a generic pretraining framework \textit{Self-supervised Multi-task pretrAining with contRol Transformer (SMART)}. By systematically investigating pretraining regimes, we carefully design a Control Transformer (CT) coupled with a novel control-centric pretraining objective in a self-supervised manner. SMART encourages the representation to capture the common essential information relevant to short-term control and long-term control, which is transferrable across tasks. We show by extensive experiments in DeepMind Control Suite that SMART significantly improves the learning efficiency among seen and unseen downstream tasks and domains under different learning scenarios including Imitation Learning (IL) and Reinforcement Learning (RL). Benefiting from the proposed control-centric objective, SMART is resilient to distribution shift between pretraining and finetuning, and even works well with low-quality pretraining datasets that are randomly collected.
PACT: Perception-Action Causal Transformer for Autoregressive Robotics Pre-Training
Sep 23, 2022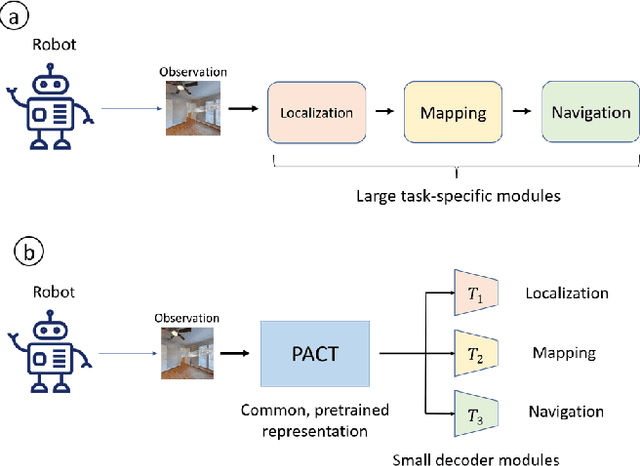
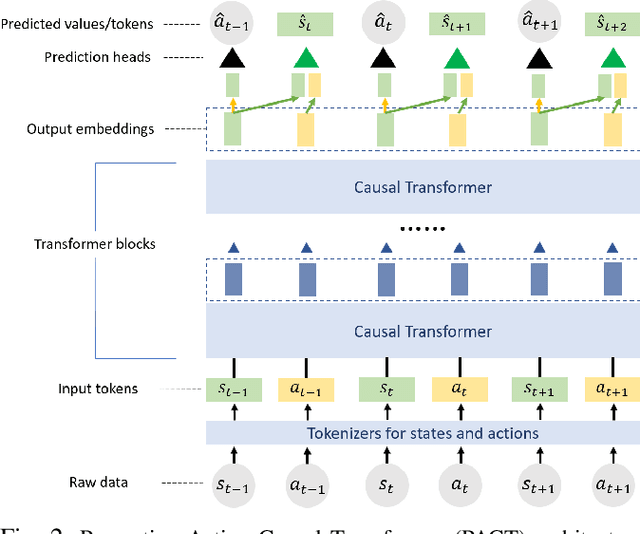
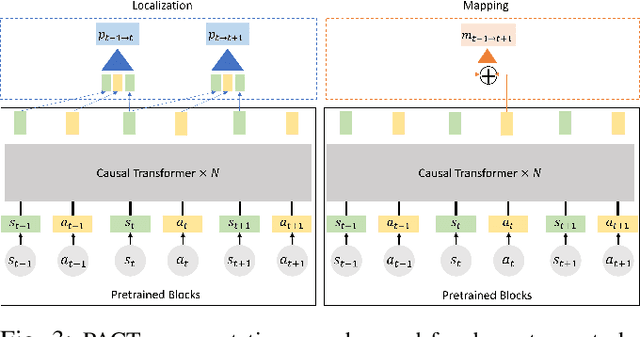

Robotics has long been a field riddled with complex systems architectures whose modules and connections, whether traditional or learning-based, require significant human expertise and prior knowledge. Inspired by large pre-trained language models, this work introduces a paradigm for pre-training a general purpose representation that can serve as a starting point for multiple tasks on a given robot. We present the Perception-Action Causal Transformer (PACT), a generative transformer-based architecture that aims to build representations directly from robot data in a self-supervised fashion. Through autoregressive prediction of states and actions over time, our model implicitly encodes dynamics and behaviors for a particular robot. Our experimental evaluation focuses on the domain of mobile agents, where we show that this robot-specific representation can function as a single starting point to achieve distinct tasks such as safe navigation, localization and mapping. We evaluate two form factors: a wheeled robot that uses a LiDAR sensor as perception input (MuSHR), and a simulated agent that uses first-person RGB images (Habitat). We show that finetuning small task-specific networks on top of the larger pretrained model results in significantly better performance compared to training a single model from scratch for all tasks simultaneously, and comparable performance to training a separate large model for each task independently. By sharing a common good-quality representation across tasks we can lower overall model capacity and speed up the real-time deployment of such systems.
LaTTe: Language Trajectory TransformEr
Aug 09, 2022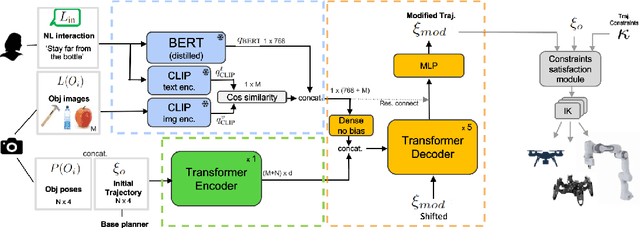
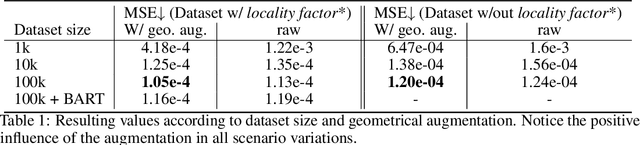
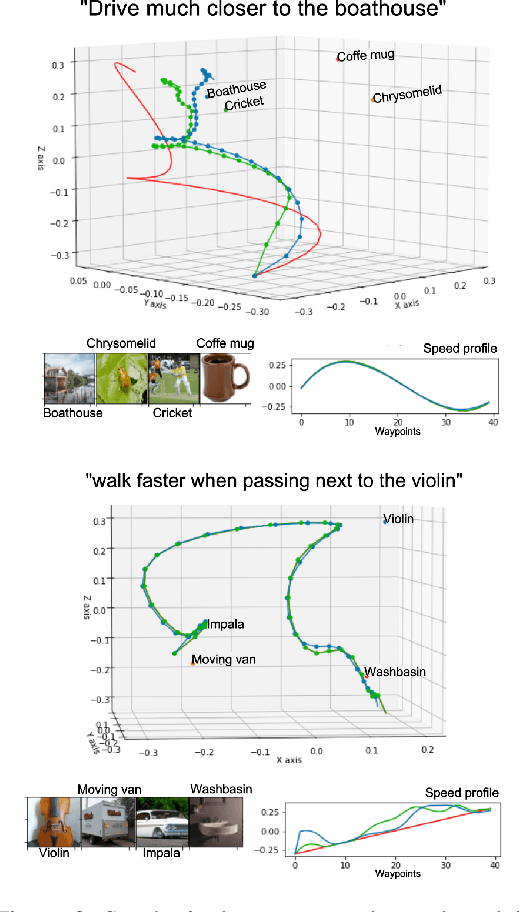

Natural language is one of the most intuitive ways to express human intent. However, translating instructions and commands towards robotic motion generation, and deployment in the real world, is far from being an easy task. Indeed, combining robotic's inherent low-level geometric and kinodynamic constraints with human's high-level semantic information reinvigorates and raises new challenges to the task-design problem -- typically leading to task or hardware specific solutions with a static set of action targets and commands. This work instead proposes a flexible language-based framework that allows to modify generic 3D robotic trajectories using language commands with reduced constraints about prior task or robot information. By taking advantage of pre-trained language models, we employ an auto-regressive transformer to map natural language inputs and contextual images into changes in 3D trajectories. We show through simulations and real-life experiments that the model can successfully follow human intent, modifying the shape and speed of trajectories for multiple robotic platforms and contexts. This study takes a step into building large pre-trained foundational models for robotics and shows how such models can create more intuitive and flexible interactions between human and machines. Codebase available at: https://github.com/arthurfenderbucker/NL_trajectory_reshaper.
Reshaping Robot Trajectories Using Natural Language Commands: A Study of Multi-Modal Data Alignment Using Transformers
Mar 25, 2022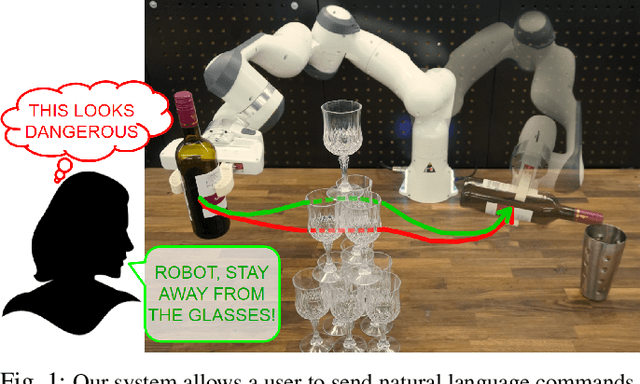
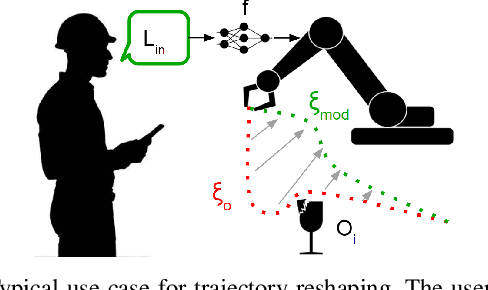
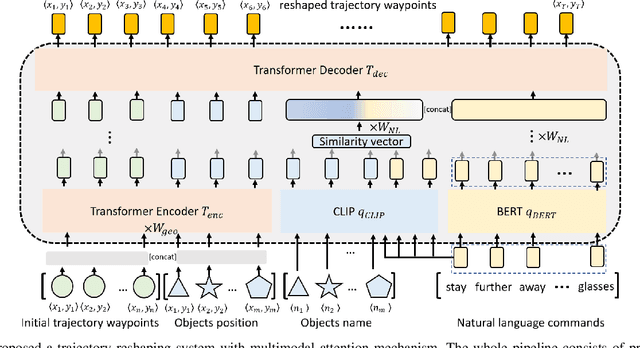
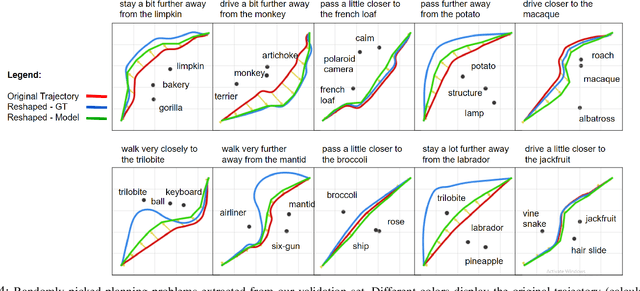
Natural language is the most intuitive medium for us to interact with other people when expressing commands and instructions. However, using language is seldom an easy task when humans need to express their intent towards robots, since most of the current language interfaces require rigid templates with a static set of action targets and commands. In this work, we provide a flexible language-based interface for human-robot collaboration, which allows a user to reshape existing trajectories for an autonomous agent. We take advantage of recent advancements in the field of large language models (BERT and CLIP) to encode the user command, and then combine these features with trajectory information using multi-modal attention transformers. We train the model using imitation learning over a dataset containing robot trajectories modified by language commands, and treat the trajectory generation process as a sequence prediction problem, analogously to how language generation architectures operate. We evaluate the system in multiple simulated trajectory scenarios, and show a significant performance increase of our model over baseline approaches. In addition, our real-world experiments with a robot arm show that users significantly prefer our natural language interface over traditional methods such as kinesthetic teaching or cost-function programming. Our study shows how the field of robotics can take advantage of large pre-trained language models towards creating more intuitive interfaces between robots and machines. Project webpage: https://arthurfenderbucker.github.io/NL_trajectory_reshaper/
Adaptive Safety Margin Estimation for Safe Real-Time Replanning under Time-Varying Disturbance
Oct 07, 2021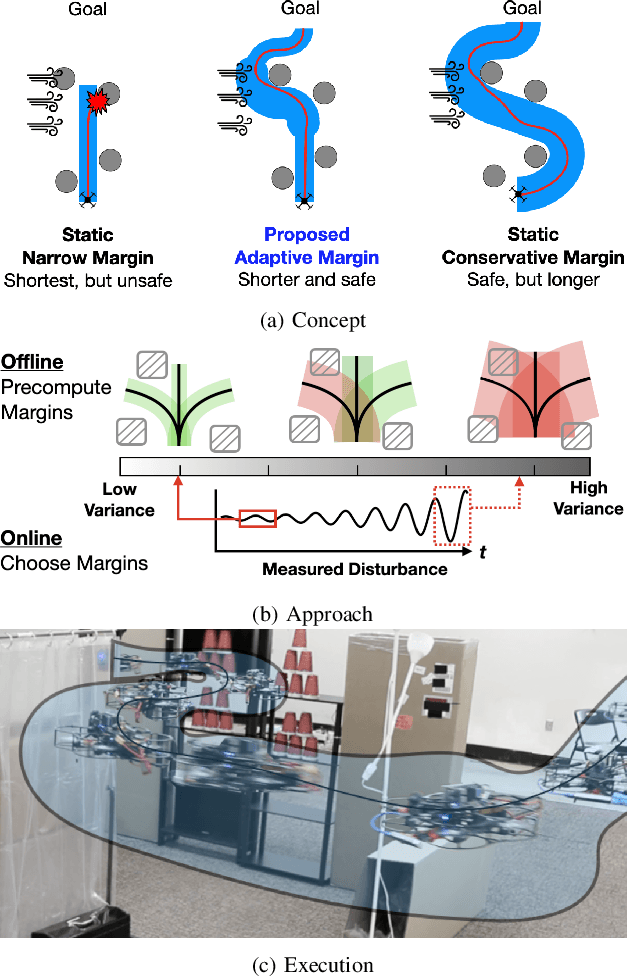
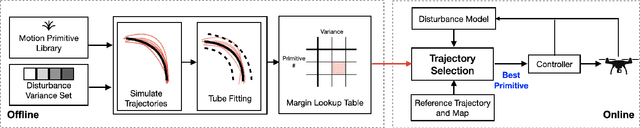
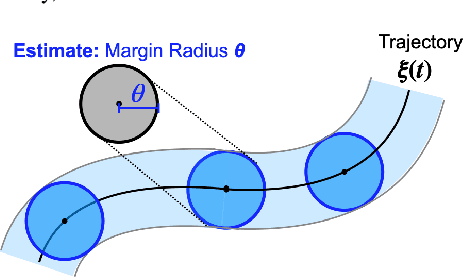
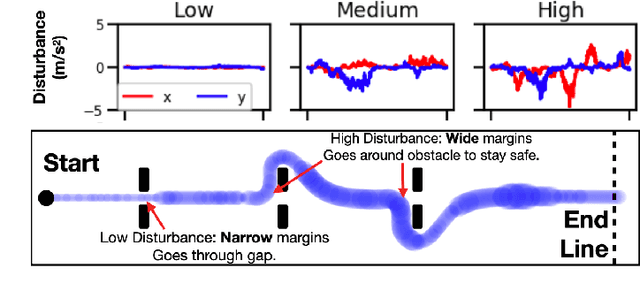
Safe navigation in real-time is challenging because engineers need to work with uncertain vehicle dynamics, variable external disturbances, and imperfect controllers. A common safety strategy is to inflate obstacles by hand-defined margins. However, arbitrary static margins often fail in more dynamic scenarios, and using worst-case assumptions is overly conservative for most settings where disturbances over time. In this work, we propose a middle ground: safety margins that adapt on-the-fly. In an offline phase, we use Monte Carlo simulations to pre-compute a library of safety margins for multiple levels of disturbance uncertainties. Then, at runtime, our system estimates the current disturbance level to query the associated safety margins that best trades off safety and performance. We validate our approach with extensive simulated and real-world flight tests. We show that our adaptive method significantly outperforms static margins, allowing the vehicle to operate up to 1.5 times faster than worst-case static margins while maintaining safety. Video: https://youtu.be/SHzKHSUjdUU