 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFFNet: Synergistic Feature Fusion Network With Dual-Domain Edge Enhancement for UAV Image Object Detection
Apr 03, 2026Object detection in unmanned aerial vehicle (UAV) images remains a highly challenging task, primarily caused by the complexity of background noise and the imbalance of target scales. Traditional methods easily struggle to effectively separate objects from intricate backgrounds and fail to fully leverage the rich multi-scale information contained within images. To address these issues, we have developed a synergistic feature fusion network (SFFNet) with dual-domain edge enhancement specifically tailored for object detection in UAV images. Firstly, the multi-scale dynamic dual-domain coupling (MDDC) module is designed. This component introduces a dual-driven edge extraction architecture that operates in both the frequency and spatial domains, enabling effective decoupling of multi-scale object edges from background noise. Secondly, to further enhance the representation capability of the model's neck in terms of both geometric and semantic information, a synergistic feature pyramid network (SFPN) is proposed. SFPN leverages linear deformable convolutions to adaptively capture irregular object shapes and establishes long-range contextual associations around targets through the designed wide-area perception module (WPM). Moreover, to adapt to the various applications or resource-constrained scenarios, six detectors of different scales (N/S/M/B/L/X) are designed. Experiments on two challenging aerial datasets (VisDrone and UAVDT) demonstrate the outstanding performance of SFFNet-X, achieving 36.8 AP and 20.6 AP, respectively. The lightweight models (N/S) also maintain a balance between detection accuracy and parameter efficiency. The code will be available at https://github.com/CQNU-ZhangLab/SFFNet.
A Generative Re-ranking Model for List-level Multi-objective Optimization at Taobao
May 12, 2025E-commerce recommendation systems aim to generate ordered lists of items for customers, optimizing multiple business objectives, such as clicks, conversions and Gross Merchandise Volume (GMV). Traditional multi-objective optimization methods like formulas or Learning-to-rank (LTR) models take effect at item-level, neglecting dynamic user intent and contextual item interactions. List-level multi-objective optimization in the re-ranking stage can overcome this limitation, but most current re-ranking models focus more on accuracy improvement with context. In addition, re-ranking is faced with the challenges of time complexity and diversity. In light of this, we propose a novel end-to-end generative re-ranking model named Sequential Ordered Regression Transformer-Generator (SORT-Gen) for the less-studied list-level multi-objective optimization problem. Specifically, SORT-Gen is divided into two parts: 1)Sequential Ordered Regression Transformer innovatively uses Transformer and ordered regression to accurately estimate multi-objective values for variable-length sub-lists. 2)Mask-Driven Fast Generation Algorithm combines multi-objective candidate queues, efficient item selection and diversity mechanism into model inference, providing a fast online list generation method. Comprehensive online experiments demonstrate that SORT-Gen brings +4.13% CLCK and +8.10% GMV for Baiyibutie, a notable Mini-app of Taobao. Currently, SORT-Gen has been successfully deployed in multiple scenarios of Taobao App, serving for a vast number of users.
TeLoGraF: Temporal Logic Planning via Graph-encoded Flow Matching
May 01, 2025Learning to solve complex tasks with signal temporal logic (STL) specifications is crucial to many real-world applications. However, most previous works only consider fixed or parametrized STL specifications due to the lack of a diverse STL dataset and encoders to effectively extract temporal logic information for downstream tasks. In this paper, we propose TeLoGraF, Temporal Logic Graph-encoded Flow, which utilizes Graph Neural Networks (GNN) encoder and flow-matching to learn solutions for general STL specifications. We identify four commonly used STL templates and collect a total of 200K specifications with paired demonstrations. We conduct extensive experiments in five simulation environments ranging from simple dynamical models in the 2D space to high-dimensional 7DoF Franka Panda robot arm and Ant quadruped navigation. Results show that our method outperforms other baselines in the STL satisfaction rate. Compared to classical STL planning algorithms, our approach is 10-100X faster in inference and can work on any system dynamics. Besides, we show our graph-encoding method's capability to solve complex STLs and robustness to out-distribution STL specifications. Code is available at https://github.com/mengyuest/TeLoGraF
Reliable and Efficient Multi-Agent Coordination via Graph Neural Network Variational Autoencoders
Mar 04, 2025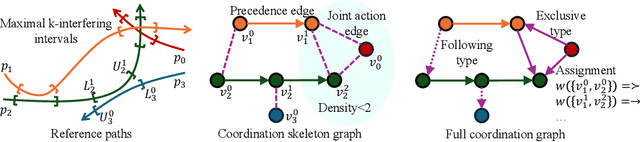
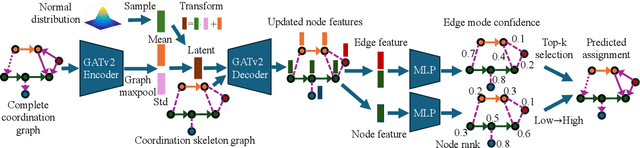
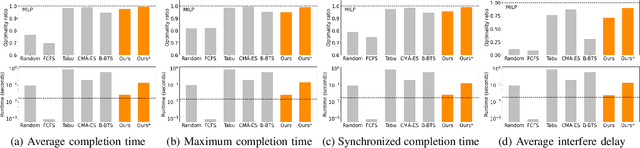
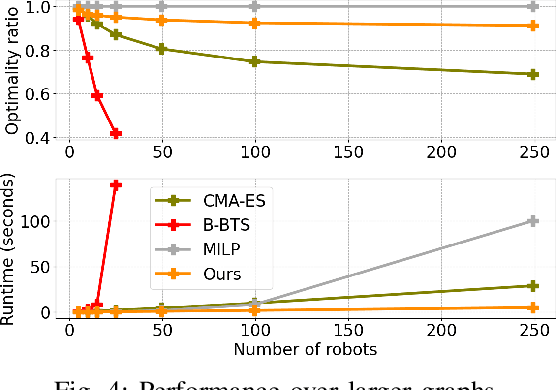
Multi-agent coordination is crucial for reliable multi-robot navigation in shared spaces such as automated warehouses. In regions of dense robot traffic, local coordination methods may fail to find a deadlock-free solution. In these scenarios, it is appropriate to let a central unit generate a global schedule that decides the passing order of robots. However, the runtime of such centralized coordination methods increases significantly with the problem scale. In this paper, we propose to leverage Graph Neural Network Variational Autoencoders (GNN-VAE) to solve the multi-agent coordination problem at scale faster than through centralized optimization. We formulate the coordination problem as a graph problem and collect ground truth data using a Mixed-Integer Linear Program (MILP) solver. During training, our learning framework encodes good quality solutions of the graph problem into a latent space. At inference time, solution samples are decoded from the sampled latent variables, and the lowest-cost sample is selected for coordination. Finally, the feasible proposal with the highest performance index is selected for the deployment. By construction, our GNN-VAE framework returns solutions that always respect the constraints of the considered coordination problem. Numerical results show that our approach trained on small-scale problems can achieve high-quality solutions even for large-scale problems with 250 robots, being much faster than other baselines. Project page: https://mengyuest.github.io/gnn-vae-coord
Diverse Controllable Diffusion Policy with Signal Temporal Logic
Mar 04, 2025Generating realistic simulations is critical for autonomous system applications such as self-driving and human-robot interactions. However, driving simulators nowadays still have difficulty in generating controllable, diverse, and rule-compliant behaviors for road participants: Rule-based models cannot produce diverse behaviors and require careful tuning, whereas learning-based methods imitate the policy from data but are not designed to follow the rules explicitly. Besides, the real-world datasets are by nature "single-outcome", making the learning method hard to generate diverse behaviors. In this paper, we leverage Signal Temporal Logic (STL) and Diffusion Models to learn controllable, diverse, and rule-aware policy. We first calibrate the STL on the real-world data, then generate diverse synthetic data using trajectory optimization, and finally learn the rectified diffusion policy on the augmented dataset. We test on the NuScenes dataset and our approach can achieve the most diverse rule-compliant trajectories compared to other baselines, with a runtime 1/17X to the second-best approach. In the closed-loop testing, our approach reaches the highest diversity, rule satisfaction rate, and the least collision rate. Our method can generate varied characteristics conditional on different STL parameters in testing. A case study on human-robot encounter scenarios shows our approach can generate diverse and closed-to-oracle trajectories. The annotation tool, augmented dataset, and code are available at https://github.com/mengyuest/pSTL-diffusion-policy.
* Accepted by IEEE Robotics and Automation Letters (RA-L), October 2024
Signal Temporal Logic Neural Predictive Control
Sep 10, 2023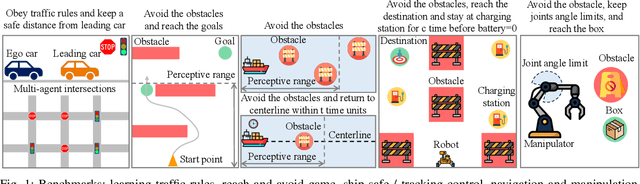
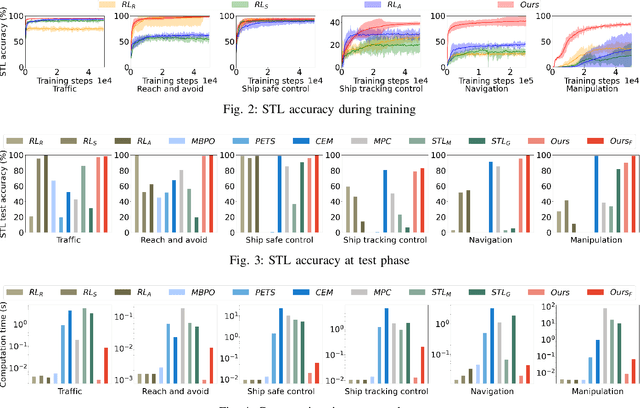
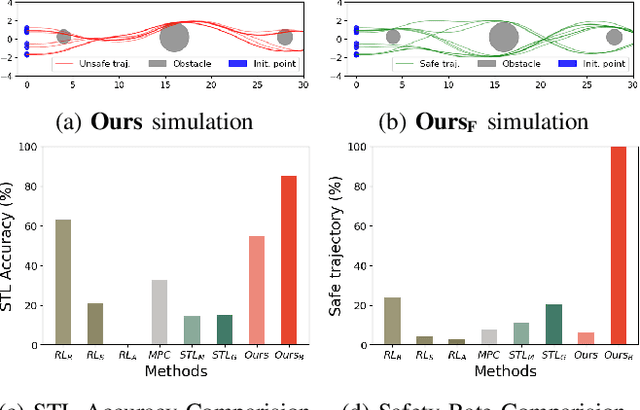
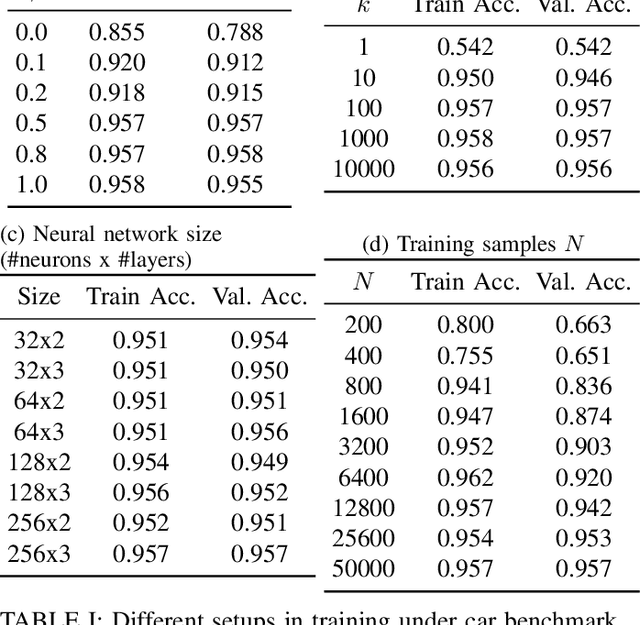
Ensuring safety and meeting temporal specifications are critical challenges for long-term robotic tasks. Signal temporal logic (STL) has been widely used to systematically and rigorously specify these requirements. However, traditional methods of finding the control policy under those STL requirements are computationally complex and not scalable to high-dimensional or systems with complex nonlinear dynamics. Reinforcement learning (RL) methods can learn the policy to satisfy the STL specifications via hand-crafted or STL-inspired rewards, but might encounter unexpected behaviors due to ambiguity and sparsity in the reward. In this paper, we propose a method to directly learn a neural network controller to satisfy the requirements specified in STL. Our controller learns to roll out trajectories to maximize the STL robustness score in training. In testing, similar to Model Predictive Control (MPC), the learned controller predicts a trajectory within a planning horizon to ensure the satisfaction of the STL requirement in deployment. A backup policy is designed to ensure safety when our controller fails. Our approach can adapt to various initial conditions and environmental parameters. We conduct experiments on six tasks, where our method with the backup policy outperforms the classical methods (MPC, STL-solver), model-free and model-based RL methods in STL satisfaction rate, especially on tasks with complex STL specifications while being 10X-100X faster than the classical methods.
Hybrid Systems Neural Control with Region-of-Attraction Planner
Mar 18, 2023Hybrid systems are prevalent in robotics. However, ensuring the stability of hybrid systems is challenging due to sophisticated continuous and discrete dynamics. A system with all its system modes stable can still be unstable. Hence special treatments are required at mode switchings to stabilize the system. In this work, we propose a hierarchical, neural network (NN)-based method to control general hybrid systems. For each system mode, we first learn an NN Lyapunov function and an NN controller to ensure the states within the region of attraction (RoA) can be stabilized. Then an RoA NN estimator is learned across different modes. Upon mode switching, we propose a differentiable planner to ensure the states after switching can land in next mode's RoA, hence stabilizing the hybrid system. We provide novel theoretical stability guarantees and conduct experiments in car tracking control, pogobot navigation, and bipedal walker locomotion. Our method only requires 0.25X of the training time as needed by other learning-based methods. With low running time (10-50X faster than model predictive control (MPC)), our controller achieves a higher stability/success rate over other baselines such as MPC, reinforcement learning (RL), common Lyapunov methods (CLF), linear quadratic regulator (LQR), quadratic programming (QP) and Hamilton-Jacobian-based methods (HJB). The project page is on https://mit-realm.github.io/hybrid-clf.
ConBaT: Control Barrier Transformer for Safe Policy Learning
Mar 07, 2023Large-scale self-supervised models have recently revolutionized our ability to perform a variety of tasks within the vision and language domains. However, using such models for autonomous systems is challenging because of safety requirements: besides executing correct actions, an autonomous agent must also avoid the high cost and potentially fatal critical mistakes. Traditionally, self-supervised training mainly focuses on imitating previously observed behaviors, and the training demonstrations carry no notion of which behaviors should be explicitly avoided. In this work, we propose Control Barrier Transformer (ConBaT), an approach that learns safe behaviors from demonstrations in a self-supervised fashion. ConBaT is inspired by the concept of control barrier functions in control theory and uses a causal transformer that learns to predict safe robot actions autoregressively using a critic that requires minimal safety data labeling. During deployment, we employ a lightweight online optimization to find actions that ensure future states lie within the learned safe set. We apply our approach to different simulated control tasks and show that our method results in safer control policies compared to other classical and learning-based methods such as imitation learning, reinforcement learning, and model predictive control.
Density Planner: Minimizing Collision Risk in Motion Planning with Dynamic Obstacles using Density-based Reachability
Oct 05, 2022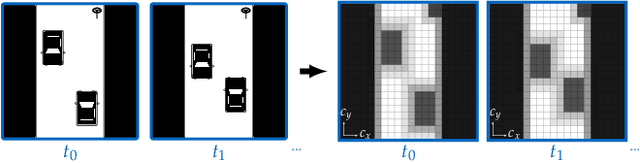
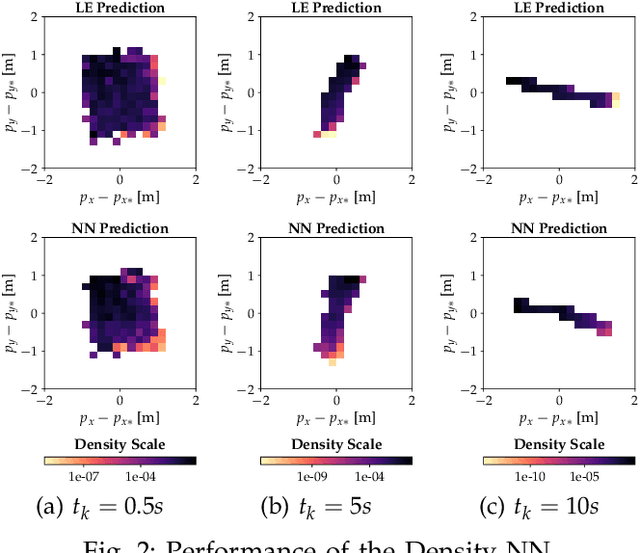
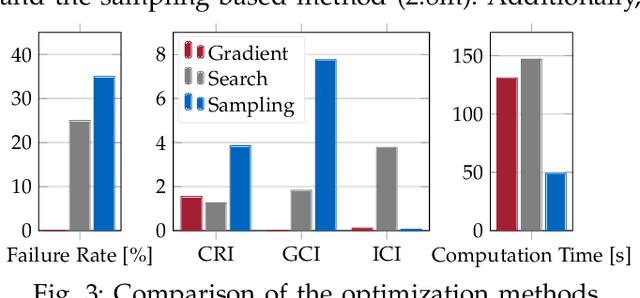
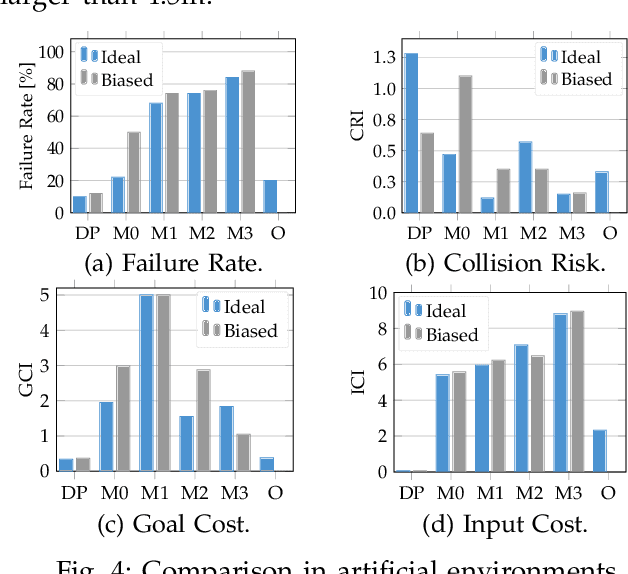
Autonomous systems with uncertainties are prevalent in robotics. However, ensuring the safety of those systems is challenging due to sophisticated dynamics and the hardness to predict future states. Usually, a classical motion planning method considering all possible states will not find a feasible path in crowded environments. To overcome this conservativeness, we propose a density-based method. The proposed method uses a neural network and the Liouville equation to learn the density evolution, and by applying a gradient-based optimization procedure, we can plan for feasible and probably safe trajectories to minimize the collision risk. We conduct experiments on simulated environments and environments generated from real-world data and outperform baseline methods such as model predictive control (MPC) and nonlinear programming (NLP). While our method requires planning time in advance, the online computational complexity is very low when compared to other methods.
Case Studies for Computing Density of Reachable States for Safe Autonomous Motion Planning
Sep 16, 2022Density of the reachable states can help understand the risk of safety-critical systems, especially in situations when worst-case reachability is too conservative. Recent work provides a data-driven approach to compute the density distribution of autonomous systems' forward reachable states online. In this paper, we study the use of such approach in combination with model predictive control for verifiable safe path planning under uncertainties. We first use the learned density distribution to compute the risk of collision online. If such risk exceeds the acceptable threshold, our method will plan for a new path around the previous trajectory, with the risk of collision below the threshold. Our method is well-suited to handle systems with uncertainties and complicated dynamics as our data-driven approach does not need an analytical form of the systems' dynamics and can estimate forward state density with an arbitrary initial distribution of uncertainties. We design two challenging scenarios (autonomous driving and hovercraft control) for safe motion planning in environments with obstacles under system uncertainties. We first show that our density estimation approach can reach a similar accuracy as the Monte-Carlo-based method while using only 0.01X training samples. By leveraging the estimated risk, our algorithm achieves the highest success rate in goal reaching when enforcing the safety rate above 0.99.