 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSD: A User-Intent-Driven Sampling and Dual-Debiasing Framework for Large-Scale Homepage Recommendations
Jul 09, 2025

Large-scale homepage recommendations face critical challenges from pseudo-negative samples caused by exposure bias, where non-clicks may indicate inattention rather than disinterest. Existing work lacks thorough analysis of invalid exposures and typically addresses isolated aspects (e.g., sampling strategies), overlooking the critical impact of pseudo-positive samples - such as homepage clicks merely to visit marketing portals. We propose a unified framework for large-scale homepage recommendation sampling and debiasing. Our framework consists of two key components: (1) a user intent-aware negative sampling module to filter invalid exposure samples, and (2) an intent-driven dual-debiasing module that jointly corrects exposure bias and click bias. Extensive online experiments on Taobao demonstrate the efficacy of our framework, achieving significant improvements in user click-through rates (UCTR) by 35.4\% and 14.5\% in two variants of the marketing block on the Taobao homepage, Baiyibutie and Taobaomiaosha.
A Generative Re-ranking Model for List-level Multi-objective Optimization at Taobao
May 12, 2025E-commerce recommendation systems aim to generate ordered lists of items for customers, optimizing multiple business objectives, such as clicks, conversions and Gross Merchandise Volume (GMV). Traditional multi-objective optimization methods like formulas or Learning-to-rank (LTR) models take effect at item-level, neglecting dynamic user intent and contextual item interactions. List-level multi-objective optimization in the re-ranking stage can overcome this limitation, but most current re-ranking models focus more on accuracy improvement with context. In addition, re-ranking is faced with the challenges of time complexity and diversity. In light of this, we propose a novel end-to-end generative re-ranking model named Sequential Ordered Regression Transformer-Generator (SORT-Gen) for the less-studied list-level multi-objective optimization problem. Specifically, SORT-Gen is divided into two parts: 1)Sequential Ordered Regression Transformer innovatively uses Transformer and ordered regression to accurately estimate multi-objective values for variable-length sub-lists. 2)Mask-Driven Fast Generation Algorithm combines multi-objective candidate queues, efficient item selection and diversity mechanism into model inference, providing a fast online list generation method. Comprehensive online experiments demonstrate that SORT-Gen brings +4.13% CLCK and +8.10% GMV for Baiyibutie, a notable Mini-app of Taobao. Currently, SORT-Gen has been successfully deployed in multiple scenarios of Taobao App, serving for a vast number of users.
Transferable Deployment of Semantic Edge Inference Systems via Unsupervised Domain Adaption
Apr 16, 2025This paper investigates deploying semantic edge inference systems for performing a common image clarification task. In particular, each system consists of multiple Internet of Things (IoT) devices that first locally encode the sensing data into semantic features and then transmit them to an edge server for subsequent data fusion and task inference. The inference accuracy is determined by efficient training of the feature encoder/decoder using labeled data samples. Due to the difference in sensing data and communication channel distributions, deploying the system in a new environment may induce high costs in annotating data labels and re-training the encoder/decoder models. To achieve cost-effective transferable system deployment, we propose an efficient Domain Adaptation method for Semantic Edge INference systems (DASEIN) that can maintain high inference accuracy in a new environment without the need for labeled samples. Specifically, DASEIN exploits the task-relevant data correlation between different deployment scenarios by leveraging the techniques of unsupervised domain adaptation and knowledge distillation. It devises an efficient two-step adaptation procedure that sequentially aligns the data distributions and adapts to the channel variations. Numerical results show that, under a substantial change in sensing data distributions, the proposed DASEIN outperforms the best-performing benchmark method by 7.09% and 21.33% in inference accuracy when the new environment has similar or 25 dB lower channel signal to noise power ratios (SNRs), respectively. This verifies the effectiveness of the proposed method in adapting both data and channel distributions in practical transfer deployment applications.
FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models
May 23, 2024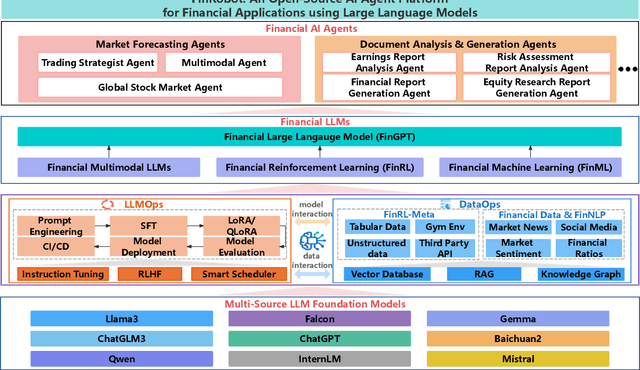
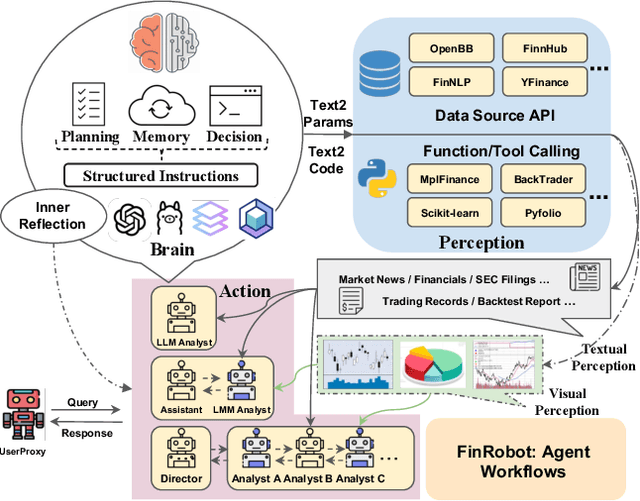
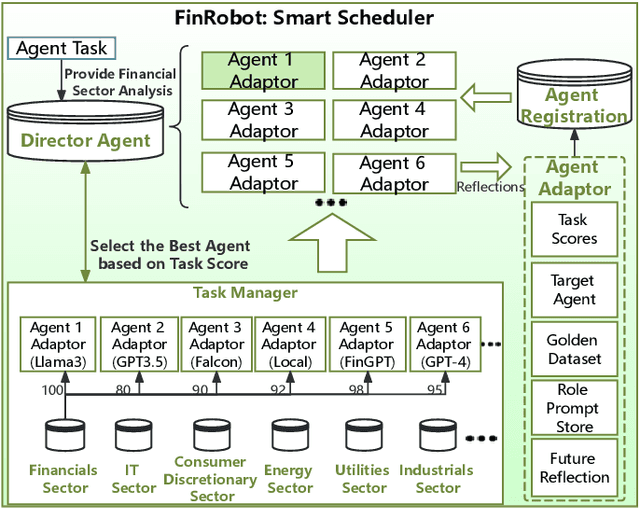

As financial institutions and professionals increasingly incorporate Large Language Models (LLMs) into their workflows, substantial barriers, including proprietary data and specialized knowledge, persist between the finance sector and the AI community. These challenges impede the AI community's ability to enhance financial tasks effectively. Acknowledging financial analysis's critical role, we aim to devise financial-specialized LLM-based toolchains and democratize access to them through open-source initiatives, promoting wider AI adoption in financial decision-making. In this paper, we introduce FinRobot, a novel open-source AI agent platform supporting multiple financially specialized AI agents, each powered by LLM. Specifically, the platform consists of four major layers: 1) the Financial AI Agents layer that formulates Financial Chain-of-Thought (CoT) by breaking sophisticated financial problems down into logical sequences; 2) the Financial LLM Algorithms layer dynamically configures appropriate model application strategies for specific tasks; 3) the LLMOps and DataOps layer produces accurate models by applying training/fine-tuning techniques and using task-relevant data; 4) the Multi-source LLM Foundation Models layer that integrates various LLMs and enables the above layers to access them directly. Finally, FinRobot provides hands-on for both professional-grade analysts and laypersons to utilize powerful AI techniques for advanced financial analysis. We open-source FinRobot at \url{https://github.com/AI4Finance-Foundation/FinRobot}.
Redistributing the Precision and Content in 3D-LUT-based Inverse Tone-mapping for HDR/WCG Display
Oct 15, 2023ITM(inverse tone-mapping) converts SDR (standard dynamic range) footage to HDR/WCG (high dynamic range /wide color gamut) for media production. It happens not only when remastering legacy SDR footage in front-end content provider, but also adapting on-theair SDR service on user-end HDR display. The latter requires more efficiency, thus the pre-calculated LUT (look-up table) has become a popular solution. Yet, conventional fixed LUT lacks adaptability, so we learn from research community and combine it with AI. Meanwhile, higher-bit-depth HDR/WCG requires larger LUT than SDR, so we consult traditional ITM for an efficiency-performance trade-off: We use 3 smaller LUTs, each has a non-uniform packing (precision) respectively denser in dark, middle and bright luma range. In this case, their results will have less error only in their own range, so we use a contribution map to combine their best parts to final result. With the guidance of this map, the elements (content) of 3 LUTs will also be redistributed during training. We conduct ablation studies to verify method's effectiveness, and subjective and objective experiments to show its practicability. Code is available at: https://github.com/AndreGuo/ITMLUT.
Edge Cloud Collaborative Stream Computing for Real-Time Structural Health Monitoring
Oct 11, 2023Structural Health Monitoring (SHM) is crucial for the safety and maintenance of various infrastructures. Due to the large amount of data generated by numerous sensors and the high real-time requirements of many applications, SHM poses significant challenges. Although the cloud-centric stream computing paradigm opens new opportunities for real-time data processing, it consumes too much network bandwidth. In this paper, we propose ECStream, an Edge Cloud collaborative fine-grained stream operator scheduling framework for SHM. We collectively consider atomic and composite operators together with their iterative computability to model and formalize the problem of minimizing bandwidth usage and end-to-end operator processing latency. Preliminary evaluation results show that ECStream can effectively balance bandwidth usage and end-to-end operator computation latency, reducing bandwidth usage by 73.01% and latency by 34.08% on average compared to the cloud-centric approach.
Machine Learning-Based Automatic Cardiovascular Disease Diagnosis Using Two ECG Leads
May 25, 2023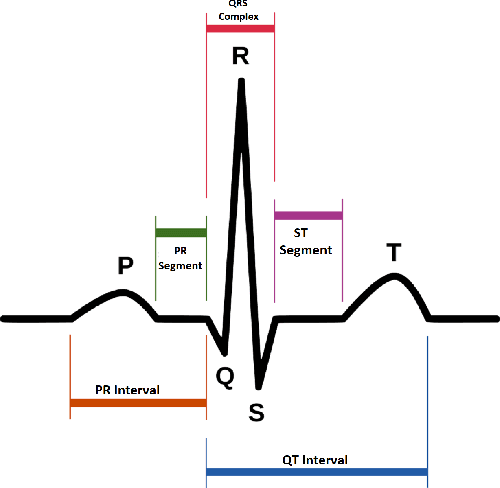

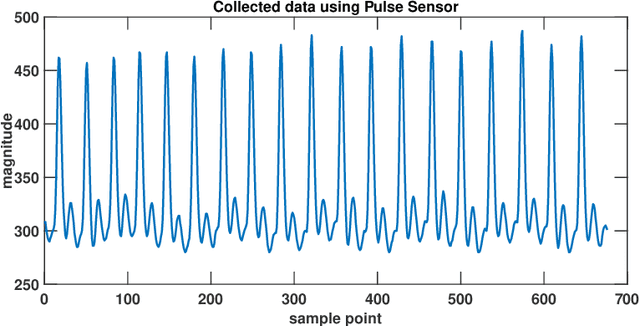
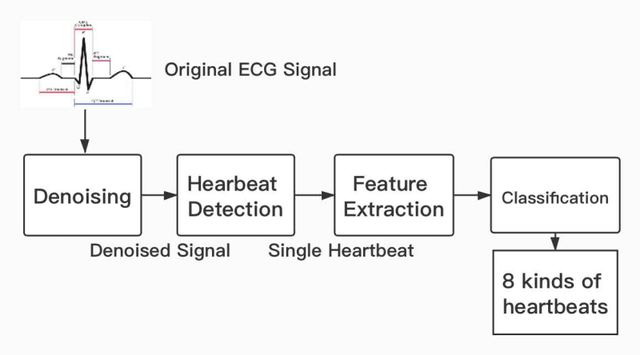
The state-of-the-art cardiovascular disease diagnosis techniques use machine-learning algorithms based on feature extraction and classification. In this work, in contrast to a conventional single Electrocardiogram (ECG) lead, two leads are used, and autoregressive (AR) coefficients and statistical parameters are extracted to be used as features. Four machine-learning classifiers support-vector-machine (SVM), K-nearest neighbors (KNN), multi-layer perceptron (MLP), and Naive Bayes are applied on these features to test the accuracy of each classifier. For simulation, data is collected from the MIT-BIH and Shaoxing Peoples Hospital China (SPHC) database. To test the generalization ability of our proposed methodology machine-learning model is built on the SPHC database and tested on the MIT-BIH database and self-collected datasets. In the single-database simulation, the MLP performs better than the other three classifiers. While in the cross-database simulation, the SVM-based model trained by the SPHC database shows superiority. For normal and LBBB heartbeats, the predicted recall respectively reaches 100% and 98.4%. Simulation results show that the performance of our proposed methodology is better than the state-of-the-art techniques for the same database. While for cross-database simulation, the results are promising too. Finally, in the demonstration of our realized system, all heartbeats collected from healthy people are classified as normal beats.
Learning a Practical SDR-to-HDRTV Up-conversion using New Dataset and Degradation Models
Mar 23, 2023

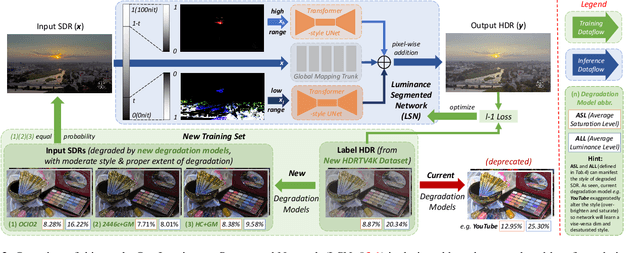

In media industry, the demand of SDR-to-HDRTV up-conversion arises when users possess HDR-WCG (high dynamic range-wide color gamut) TVs while most off-the-shelf footage is still in SDR (standard dynamic range). The research community has started tackling this low-level vision task by learning-based approaches. When applied to real SDR, yet, current methods tend to produce dim and desaturated result, making nearly no improvement on viewing experience. Different from other network-oriented methods, we attribute such deficiency to training set (HDR-SDR pair). Consequently, we propose new HDRTV dataset (dubbed HDRTV4K) and new HDR-to-SDR degradation models. Then, it's used to train a luminance-segmented network (LSN) consisting of a global mapping trunk, and two Transformer branches on bright and dark luminance range. We also update assessment criteria by tailored metrics and subjective experiment. Finally, ablation studies are conducted to prove the effectiveness. Our work is available at: https://github.com/AndreGuo/HDRTVDM.
Concealed Object Detection for Passive Millimeter-Wave Security Imaging Based on Task-Aligned Detection Transformer
Dec 01, 2022Passive millimeter-wave (PMMW) is a significant potential technique for human security screening. Several popular object detection networks have been used for PMMW images. However, restricted by the low resolution and high noise of PMMW images, PMMW hidden object detection based on deep learning usually suffers from low accuracy and low classification confidence. To tackle the above problems, this paper proposes a Task-Aligned Detection Transformer network, named PMMW-DETR. In the first stage, a Denoising Coarse-to-Fine Transformer (DCFT) backbone is designed to extract long- and short-range features in the different scales. In the second stage, we propose the Query Selection module to introduce learned spatial features into the network as prior knowledge, which enhances the semantic perception capability of the network. In the third stage, aiming to improve the classification performance, we perform a Task-Aligned Dual-Head block to decouple the classification and regression tasks. Based on our self-developed PMMW security screening dataset, experimental results including comparison with State-Of-The-Art (SOTA) methods and ablation study demonstrate that the PMMW-DETR obtains higher accuracy and classification confidence than previous works, and exhibits robustness to the PMMW images of low quality.
LHDR: HDR Reconstruction for Legacy Content using a Lightweight DNN
Nov 21, 2022High dynamic range (HDR) image is widely-used in graphics and photography due to the rich information it contains. Recently the community has started using deep neural network (DNN) to reconstruct standard dynamic range (SDR) images into HDR. Albeit the superiority of current DNN-based methods, their application scenario is still limited: (1) heavy model impedes real-time processing, and (2) inapplicable to legacy SDR content with more degradation types. Therefore, we propose a lightweight DNN-based method trained to tackle legacy SDR. For better design, we reform the problem modeling and emphasize degradation model. Experiments show that our method reached appealing performance with minimal computational cost compared with others.