 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Dense Reconstruction with Consistent Scene Segments
Sep 30, 2021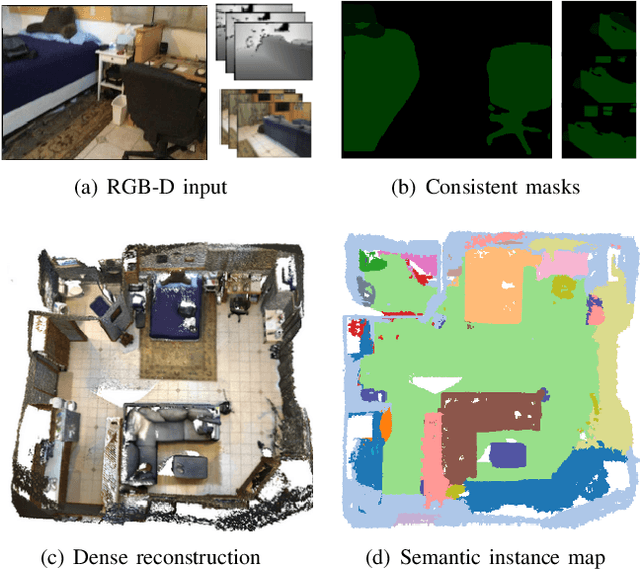
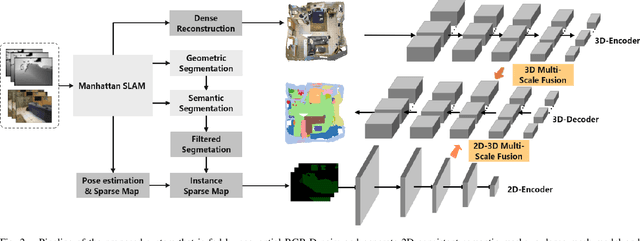


In this paper, a method for dense semantic 3D scene reconstruction from an RGB-D sequence is proposed to solve high-level scene understanding tasks. First, each RGB-D pair is consistently segmented into 2D semantic maps based on a camera tracking backbone that propagates objects' labels with high probabilities from full scans to corresponding ones of partial views. Then a dense 3D mesh model of an unknown environment is incrementally generated from the input RGB-D sequence. Benefiting from 2D consistent semantic segments and the 3D model, a novel semantic projection block (SP-Block) is proposed to extract deep feature volumes from 2D segments of different views. Moreover, the semantic volumes are fused into deep volumes from a point cloud encoder to make the final semantic segmentation. Extensive experimental evaluations on public datasets show that our system achieves accurate 3D dense reconstruction and state-of-the-art semantic prediction performances simultaneously.