 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Garment Reconstruction Using Diffusion Mapping via Pattern Coordinates
Feb 27, 2026Reconstructing 3D clothed humans from monocular images and videos is a fundamental problem with applications in virtual try-on, avatar creation, and mixed reality. Despite significant progress in human body recovery, accurately reconstructing garment geometry, particularly for loose-fitting clothing, remains an open challenge. We propose a unified framework for high-fidelity 3D garment reconstruction from both single images and video sequences. Our approach combines Implicit Sewing Patterns (ISP) with a generative diffusion model to learn expressive garment shape priors in 2D UV space. Leveraging these priors, we introduce a mapping model that establishes correspondences between image pixels, UV pattern coordinates, and 3D geometry, enabling accurate and detailed garment reconstruction from single images. We further extend this formulation to dynamic reconstruction by introducing a spatio-temporal diffusion scheme with test-time guidance to enforce long-range temporal consistency. We also develop analytic projection-based constraints that preserve image-aligned geometry in visible regions while enforcing coherent completion in occluded areas over time. Although trained exclusively on synthetically simulated cloth data, our method generalizes well to real-world imagery and consistently outperforms existing approaches on both tight- and loose-fitting garments. The reconstructed garments preserve fine geometric detail while exhibiting realistic dynamic motion, supporting downstream applications such as texture editing, garment retargeting, and animation.
Single View Garment Reconstruction Using Diffusion Mapping Via Pattern Coordinates
Apr 11, 2025Reconstructing 3D clothed humans from images is fundamental to applications like virtual try-on, avatar creation, and mixed reality. While recent advances have enhanced human body recovery, accurate reconstruction of garment geometry -- especially for loose-fitting clothing -- remains an open challenge. We present a novel method for high-fidelity 3D garment reconstruction from single images that bridges 2D and 3D representations. Our approach combines Implicit Sewing Patterns (ISP) with a generative diffusion model to learn rich garment shape priors in a 2D UV space. A key innovation is our mapping model that establishes correspondences between 2D image pixels, UV pattern coordinates, and 3D geometry, enabling joint optimization of both 3D garment meshes and the corresponding 2D patterns by aligning learned priors with image observations. Despite training exclusively on synthetically simulated cloth data, our method generalizes effectively to real-world images, outperforming existing approaches on both tight- and loose-fitting garments. The reconstructed garments maintain physical plausibility while capturing fine geometric details, enabling downstream applications including garment retargeting and texture manipulation.
Dual-Branch Graph Transformer Network for 3D Human Mesh Reconstruction from Video
Dec 02, 2024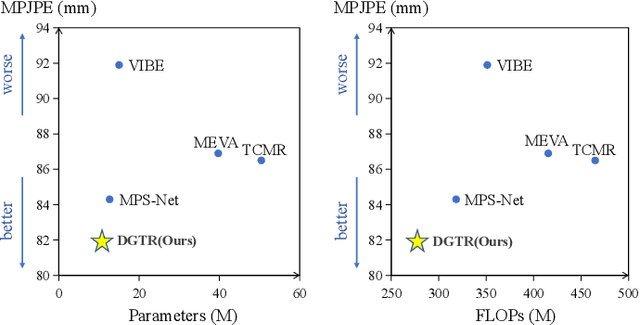
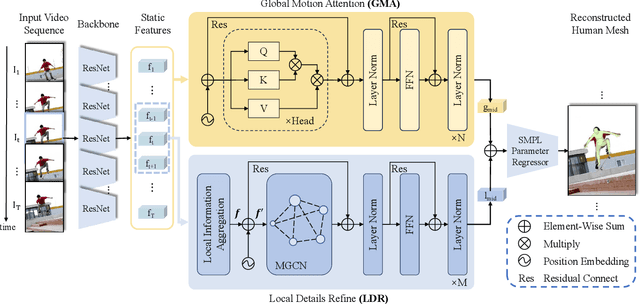
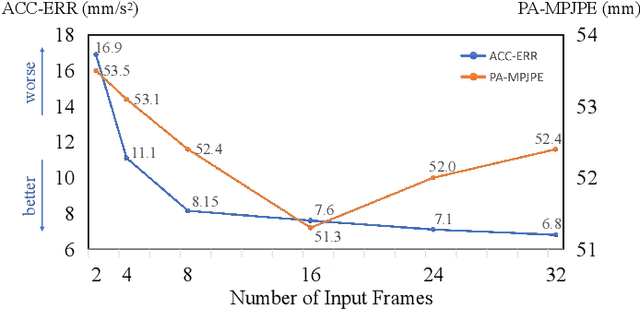

Human Mesh Reconstruction (HMR) from monocular video plays an important role in human-robot interaction and collaboration. However, existing video-based human mesh reconstruction methods face a trade-off between accurate reconstruction and smooth motion. These methods design networks based on either RNNs or attention mechanisms to extract local temporal correlations or global temporal dependencies, but the lack of complementary long-term information and local details limits their performance. To address this problem, we propose a \textbf{D}ual-branch \textbf{G}raph \textbf{T}ransformer network for 3D human mesh \textbf{R}econstruction from video, named DGTR. DGTR employs a dual-branch network including a Global Motion Attention (GMA) branch and a Local Details Refine (LDR) branch to parallelly extract long-term dependencies and local crucial information, helping model global human motion and local human details (e.g., local motion, tiny movement). Specifically, GMA utilizes a global transformer to model long-term human motion. LDR combines modulated graph convolutional networks and the transformer framework to aggregate local information in adjacent frames and extract crucial information of human details. Experiments demonstrate that our DGTR outperforms state-of-the-art video-based methods in reconstruction accuracy and maintains competitive motion smoothness. Moreover, DGTR utilizes fewer parameters and FLOPs, which validate the effectiveness and efficiency of the proposed DGTR. Code is publicly available at \href{https://github.com/TangTao-PKU/DGTR}{\textcolor{myBlue}{https://github.com/TangTao-PKU/DGTR}}.
ARTS: Semi-Analytical Regressor using Disentangled Skeletal Representations for Human Mesh Recovery from Videos
Oct 21, 2024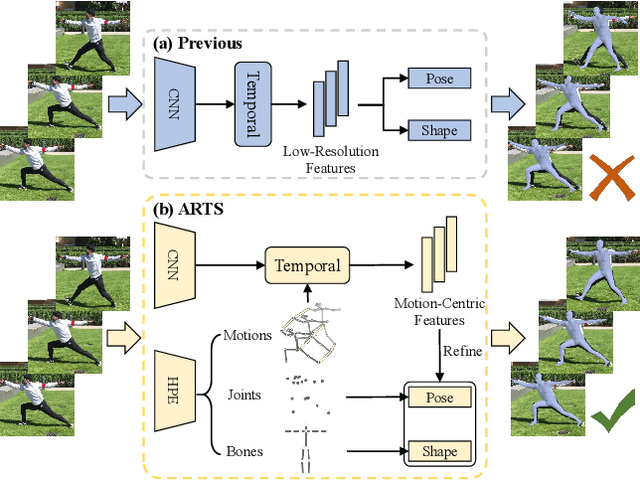
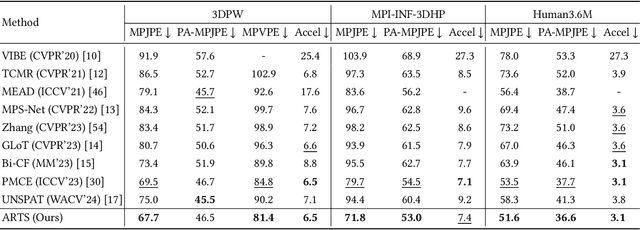
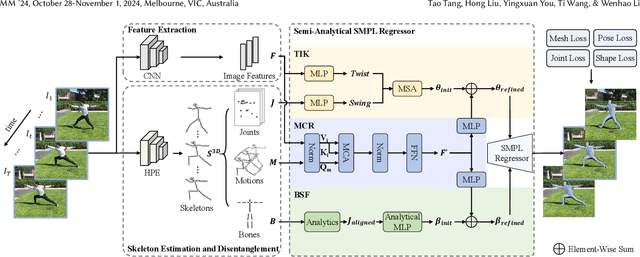

Although existing video-based 3D human mesh recovery methods have made significant progress, simultaneously estimating human pose and shape from low-resolution image features limits their performance. These image features lack sufficient spatial information about the human body and contain various noises (e.g., background, lighting, and clothing), which often results in inaccurate pose and inconsistent motion. Inspired by the rapid advance in human pose estimation, we discover that compared to image features, skeletons inherently contain accurate human pose and motion. Therefore, we propose a novel semiAnalytical Regressor using disenTangled Skeletal representations for human mesh recovery from videos, called ARTS. Specifically, a skeleton estimation and disentanglement module is proposed to estimate the 3D skeletons from a video and decouple them into disentangled skeletal representations (i.e., joint position, bone length, and human motion). Then, to fully utilize these representations, we introduce a semi-analytical regressor to estimate the parameters of the human mesh model. The regressor consists of three modules: Temporal Inverse Kinematics (TIK), Bone-guided Shape Fitting (BSF), and Motion-Centric Refinement (MCR). TIK utilizes joint position to estimate initial pose parameters and BSF leverages bone length to regress bone-aligned shape parameters. Finally, MCR combines human motion representation with image features to refine the initial human model parameters. Extensive experiments demonstrate that our ARTS surpasses existing state-of-the-art video-based methods in both per-frame accuracy and temporal consistency on popular benchmarks: 3DPW, MPI-INF-3DHP, and Human3.6M. Code is available at https://github.com/TangTao-PKU/ARTS.
Uncertainty-Aware Testing-Time Optimization for 3D Human Pose Estimation
Feb 04, 2024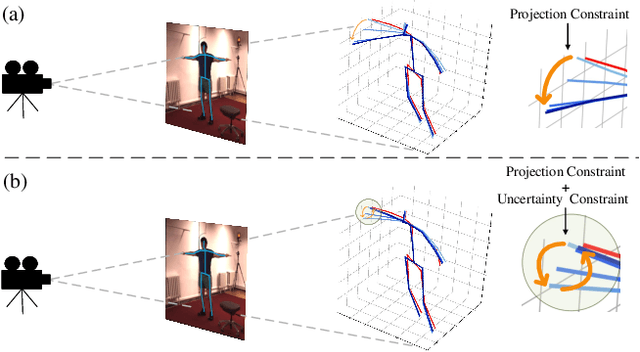

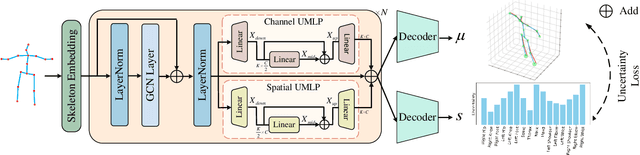

Although data-driven methods have achieved success in 3D human pose estimation, they often suffer from domain gaps and exhibit limited generalization. In contrast, optimization-based methods excel in fine-tuning for specific cases but are generally inferior to data-driven methods in overall performance. We observe that previous optimization-based methods commonly rely on projection constraint, which only ensures alignment in 2D space, potentially leading to the overfitting problem. To address this, we propose an Uncertainty-Aware testing-time Optimization (UAO) framework, which keeps the prior information of pre-trained model and alleviates the overfitting problem using the uncertainty of joints. Specifically, during the training phase, we design an effective 2D-to-3D network for estimating the corresponding 3D pose while quantifying the uncertainty of each 3D joint. For optimization during testing, the proposed optimization framework freezes the pre-trained model and optimizes only a latent state. Projection loss is then employed to ensure the generated poses are well aligned in 2D space for high-quality optimization. Furthermore, we utilize the uncertainty of each joint to determine how much each joint is allowed for optimization. The effectiveness and superiority of the proposed framework are validated through extensive experiments on two challenging datasets: Human3.6M and MPI-INF-3DHP. Notably, our approach outperforms the previous best result by a large margin of 4.5% on Human3.6M. Our source code will be open-sourced.
Co-Evolution of Pose and Mesh for 3D Human Body Estimation from Video
Aug 20, 2023Despite significant progress in single image-based 3D human mesh recovery, accurately and smoothly recovering 3D human motion from a video remains challenging. Existing video-based methods generally recover human mesh by estimating the complex pose and shape parameters from coupled image features, whose high complexity and low representation ability often result in inconsistent pose motion and limited shape patterns. To alleviate this issue, we introduce 3D pose as the intermediary and propose a Pose and Mesh Co-Evolution network (PMCE) that decouples this task into two parts: 1) video-based 3D human pose estimation and 2) mesh vertices regression from the estimated 3D pose and temporal image feature. Specifically, we propose a two-stream encoder that estimates mid-frame 3D pose and extracts a temporal image feature from the input image sequence. In addition, we design a co-evolution decoder that performs pose and mesh interactions with the image-guided Adaptive Layer Normalization (AdaLN) to make pose and mesh fit the human body shape. Extensive experiments demonstrate that the proposed PMCE outperforms previous state-of-the-art methods in terms of both per-frame accuracy and temporal consistency on three benchmark datasets: 3DPW, Human3.6M, and MPI-INF-3DHP. Our code is available at https://github.com/kasvii/PMCE.
Interweaved Graph and Attention Network for 3D Human Pose Estimation
Apr 27, 2023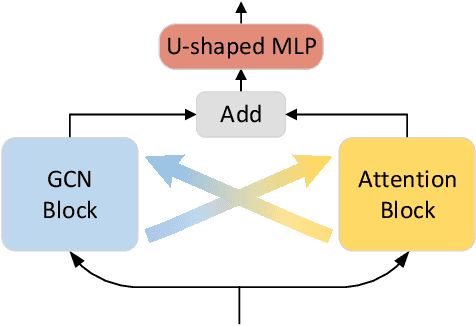
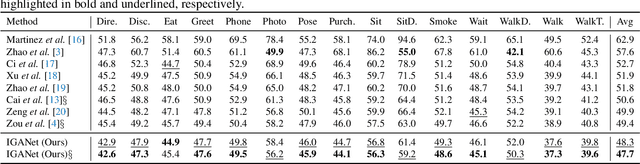
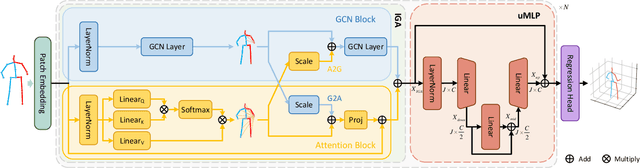

Despite substantial progress in 3D human pose estimation from a single-view image, prior works rarely explore global and local correlations, leading to insufficient learning of human skeleton representations. To address this issue, we propose a novel Interweaved Graph and Attention Network (IGANet) that allows bidirectional communications between graph convolutional networks (GCNs) and attentions. Specifically, we introduce an IGA module, where attentions are provided with local information from GCNs and GCNs are injected with global information from attentions. Additionally, we design a simple yet effective U-shaped multi-layer perceptron (uMLP), which can capture multi-granularity information for body joints. Extensive experiments on two popular benchmark datasets (i.e. Human3.6M and MPI-INF-3DHP) are conducted to evaluate our proposed method.The results show that IGANet achieves state-of-the-art performance on both datasets. Code is available at https://github.com/xiu-cs/IGANet.
GATOR: Graph-Aware Transformer with Motion-Disentangled Regression for Human Mesh Recovery from a 2D Pose
Mar 10, 2023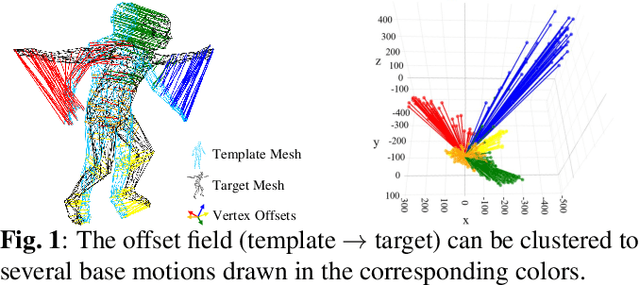
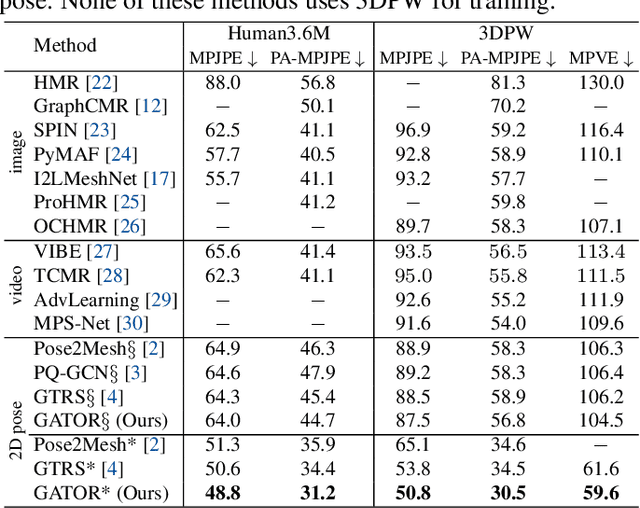
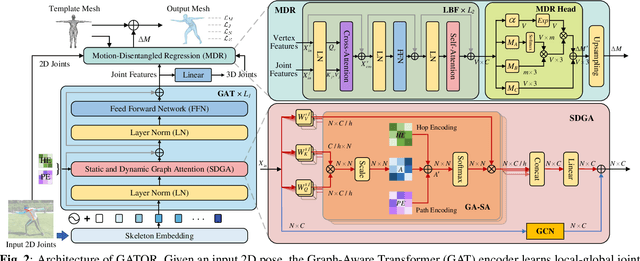

3D human mesh recovery from a 2D pose plays an important role in various applications. However, it is hard for existing methods to simultaneously capture the multiple relations during the evolution from skeleton to mesh, including joint-joint, joint-vertex and vertex-vertex relations, which often leads to implausible results. To address this issue, we propose a novel solution, called GATOR, that contains an encoder of Graph-Aware Transformer (GAT) and a decoder with Motion-Disentangled Regression (MDR) to explore these multiple relations. Specifically, GAT combines a GCN and a graph-aware self-attention in parallel to capture physical and hidden joint-joint relations. Furthermore, MDR models joint-vertex and vertex-vertex interactions to explore joint and vertex relations. Based on the clustering characteristics of vertex offset fields, MDR regresses the vertices by composing the predicted base motions. Extensive experiments show that GATOR achieves state-of-the-art performance on two challenging benchmarks.
Semantic Dense Reconstruction with Consistent Scene Segments
Sep 30, 2021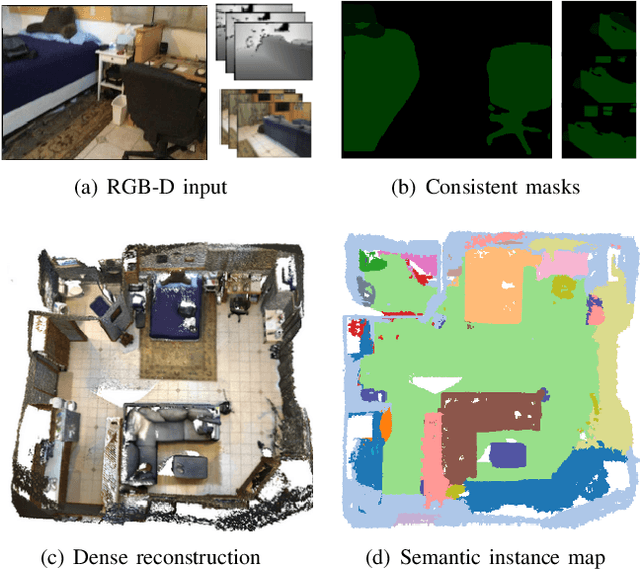
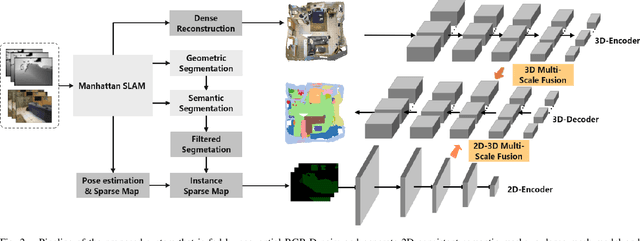


In this paper, a method for dense semantic 3D scene reconstruction from an RGB-D sequence is proposed to solve high-level scene understanding tasks. First, each RGB-D pair is consistently segmented into 2D semantic maps based on a camera tracking backbone that propagates objects' labels with high probabilities from full scans to corresponding ones of partial views. Then a dense 3D mesh model of an unknown environment is incrementally generated from the input RGB-D sequence. Benefiting from 2D consistent semantic segments and the 3D model, a novel semantic projection block (SP-Block) is proposed to extract deep feature volumes from 2D segments of different views. Moreover, the semantic volumes are fused into deep volumes from a point cloud encoder to make the final semantic segmentation. Extensive experimental evaluations on public datasets show that our system achieves accurate 3D dense reconstruction and state-of-the-art semantic prediction performances simultaneously.