 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore Human Parsing Modality for Action Recognition
Jan 04, 2024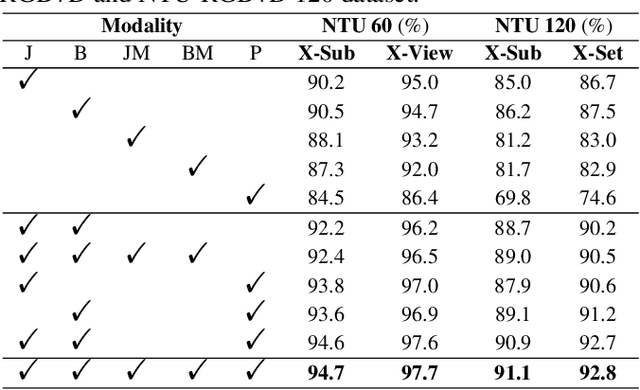

Multimodal-based action recognition methods have achieved high success using pose and RGB modality. However, skeletons sequences lack appearance depiction and RGB images suffer irrelevant noise due to modality limitations. To address this, we introduce human parsing feature map as a novel modality, since it can selectively retain effective semantic features of the body parts, while filtering out most irrelevant noise. We propose a new dual-branch framework called Ensemble Human Parsing and Pose Network (EPP-Net), which is the first to leverage both skeletons and human parsing modalities for action recognition. The first human pose branch feeds robust skeletons in graph convolutional network to model pose features, while the second human parsing branch also leverages depictive parsing feature maps to model parsing festures via convolutional backbones. The two high-level features will be effectively combined through a late fusion strategy for better action recognition. Extensive experiments on NTU RGB+D and NTU RGB+D 120 benchmarks consistently verify the effectiveness of our proposed EPP-Net, which outperforms the existing action recognition methods. Our code is available at: https://github.com/liujf69/EPP-Net-Action.
Co-Evolution of Pose and Mesh for 3D Human Body Estimation from Video
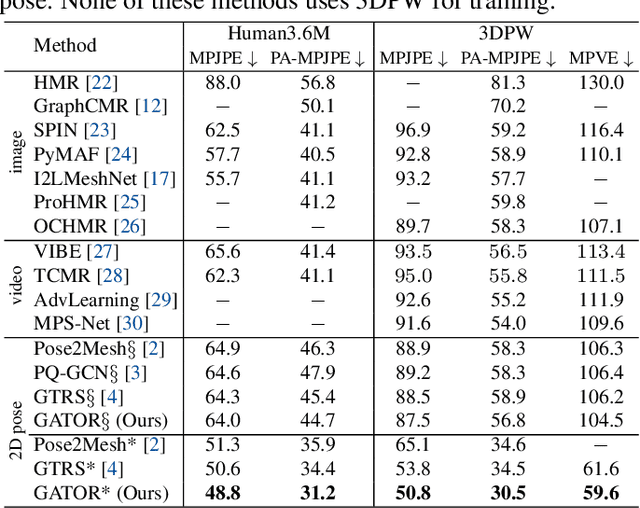
Aug 20, 2023Despite significant progress in single image-based 3D human mesh recovery, accurately and smoothly recovering 3D human motion from a video remains challenging. Existing video-based methods generally recover human mesh by estimating the complex pose and shape parameters from coupled image features, whose high complexity and low representation ability often result in inconsistent pose motion and limited shape patterns. To alleviate this issue, we introduce 3D pose as the intermediary and propose a Pose and Mesh Co-Evolution network (PMCE) that decouples this task into two parts: 1) video-based 3D human pose estimation and 2) mesh vertices regression from the estimated 3D pose and temporal image feature. Specifically, we propose a two-stream encoder that estimates mid-frame 3D pose and extracts a temporal image feature from the input image sequence. In addition, we design a co-evolution decoder that performs pose and mesh interactions with the image-guided Adaptive Layer Normalization (AdaLN) to make pose and mesh fit the human body shape. Extensive experiments demonstrate that the proposed PMCE outperforms previous state-of-the-art methods in terms of both per-frame accuracy and temporal consistency on three benchmark datasets: 3DPW, Human3.6M, and MPI-INF-3DHP. Our code is available at https://github.com/kasvii/PMCE.
PKU-GoodsAD: A Supermarket Goods Dataset for Unsupervised Anomaly Detection and Segmentation
Jul 26, 2023

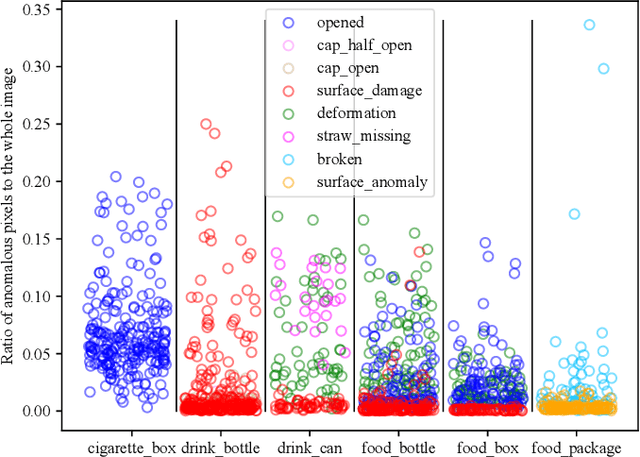
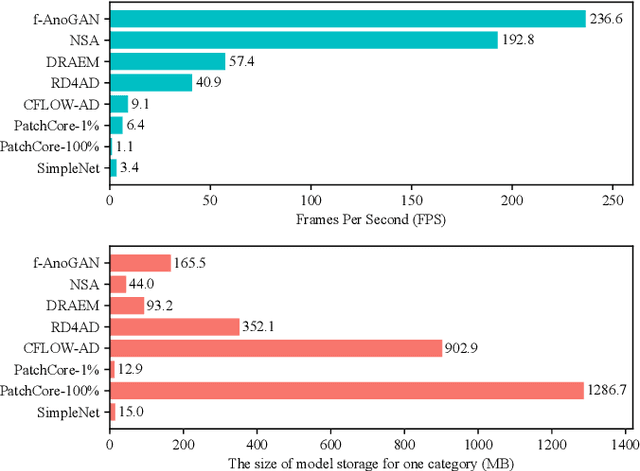
Visual anomaly detection is essential and commonly used for many tasks in the field of computer vision. Recent anomaly detection datasets mainly focus on industrial automated inspection, medical image analysis and video surveillance. In order to broaden the application and research of anomaly detection in unmanned supermarkets and smart manufacturing, we introduce the supermarket goods anomaly detection (GoodsAD) dataset. It contains 6124 high-resolution images of 484 different appearance goods divided into 6 categories. Each category contains several common different types of anomalies such as deformation, surface damage and opened. Anomalies contain both texture changes and structural changes. It follows the unsupervised setting and only normal (defect-free) images are used for training. Pixel-precise ground truth regions are provided for all anomalies. Moreover, we also conduct a thorough evaluation of current state-of-the-art unsupervised anomaly detection methods. This initial benchmark indicates that some methods which perform well on the industrial anomaly detection dataset (e.g., MVTec AD), show poor performance on our dataset. This is a comprehensive, multi-object dataset for supermarket goods anomaly detection that focuses on real-world applications.
Integrating Human Parsing and Pose Network for Human Action Recognition
Jul 16, 2023



Human skeletons and RGB sequences are both widely-adopted input modalities for human action recognition. However, skeletons lack appearance features and color data suffer large amount of irrelevant depiction. To address this, we introduce human parsing feature map as a novel modality, since it can selectively retain spatiotemporal features of the body parts, while filtering out noises regarding outfits, backgrounds, etc. We propose an Integrating Human Parsing and Pose Network (IPP-Net) for action recognition, which is the first to leverage both skeletons and human parsing feature maps in dual-branch approach. The human pose branch feeds compact skeletal representations of different modalities in graph convolutional network to model pose features. In human parsing branch, multi-frame body-part parsing features are extracted with human detector and parser, which is later learnt using a convolutional backbone. A late ensemble of two branches is adopted to get final predictions, considering both robust keypoints and rich semantic body-part features. Extensive experiments on NTU RGB+D and NTU RGB+D 120 benchmarks consistently verify the effectiveness of the proposed IPP-Net, which outperforms the existing action recognition methods. Our code is publicly available at https://github.com/liujf69/IPP-Net-Parsing .
Edge-guided Representation Learning for Underwater Object Detection
Jun 01, 2023



Underwater object detection (UOD) is crucial for marine economic development, environmental protection, and the planet's sustainable development. The main challenges of this task arise from low-contrast, small objects, and mimicry of aquatic organisms. The key to addressing these challenges is to focus the model on obtaining more discriminative information. We observe that the edges of underwater objects are highly unique and can be distinguished from low-contrast or mimicry environments based on their edges. Motivated by this observation, we propose an Edge-guided Representation Learning Network, termed ERL-Net, that aims to achieve discriminative representation learning and aggregation under the guidance of edge cues. Firstly, we introduce an edge-guided attention module to model the explicit boundary information, which generates more discriminative features. Secondly, a feature aggregation module is proposed to aggregate the multi-scale discriminative features by regrouping them into three levels, effectively aggregating global and local information for locating and recognizing underwater objects. Finally, we propose a wide and asymmetric receptive field block to enable features to have a wider receptive field, allowing the model to focus on more small object information. Comprehensive experiments on three challenging underwater datasets show that our method achieves superior performance on the UOD task.
Interweaved Graph and Attention Network for 3D Human Pose Estimation
Apr 27, 2023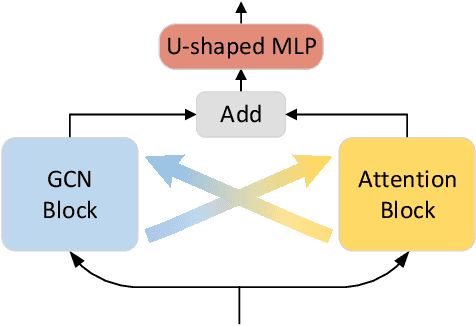
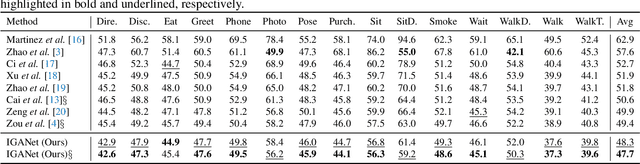
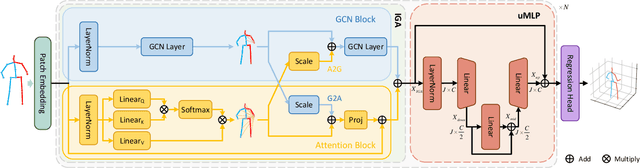

Despite substantial progress in 3D human pose estimation from a single-view image, prior works rarely explore global and local correlations, leading to insufficient learning of human skeleton representations. To address this issue, we propose a novel Interweaved Graph and Attention Network (IGANet) that allows bidirectional communications between graph convolutional networks (GCNs) and attentions. Specifically, we introduce an IGA module, where attentions are provided with local information from GCNs and GCNs are injected with global information from attentions. Additionally, we design a simple yet effective U-shaped multi-layer perceptron (uMLP), which can capture multi-granularity information for body joints. Extensive experiments on two popular benchmark datasets (i.e. Human3.6M and MPI-INF-3DHP) are conducted to evaluate our proposed method.The results show that IGANet achieves state-of-the-art performance on both datasets. Code is available at https://github.com/xiu-cs/IGANet.
GATOR: Graph-Aware Transformer with Motion-Disentangled Regression for Human Mesh Recovery from a 2D Pose
Mar 10, 2023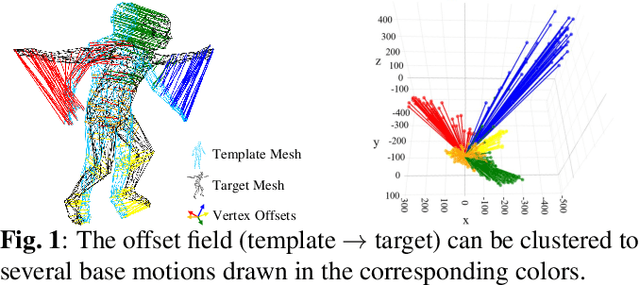
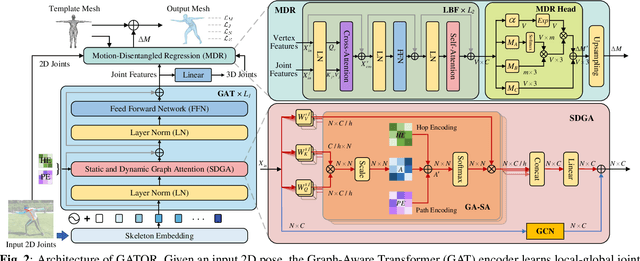

3D human mesh recovery from a 2D pose plays an important role in various applications. However, it is hard for existing methods to simultaneously capture the multiple relations during the evolution from skeleton to mesh, including joint-joint, joint-vertex and vertex-vertex relations, which often leads to implausible results. To address this issue, we propose a novel solution, called GATOR, that contains an encoder of Graph-Aware Transformer (GAT) and a decoder with Motion-Disentangled Regression (MDR) to explore these multiple relations. Specifically, GAT combines a GCN and a graph-aware self-attention in parallel to capture physical and hidden joint-joint relations. Furthermore, MDR models joint-vertex and vertex-vertex interactions to explore joint and vertex relations. Based on the clustering characteristics of vertex offset fields, MDR regresses the vertices by composing the predicted base motions. Extensive experiments show that GATOR achieves state-of-the-art performance on two challenging benchmarks.
HTNet: Human Topology Aware Network for 3D Human Pose Estimation
Feb 20, 2023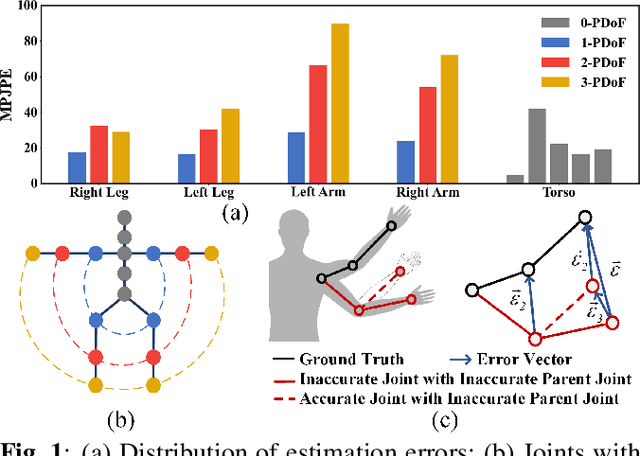
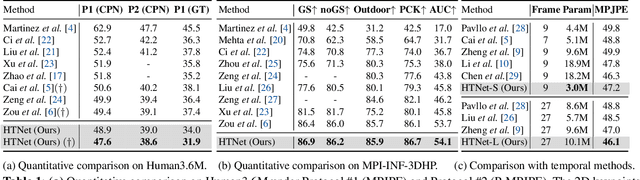
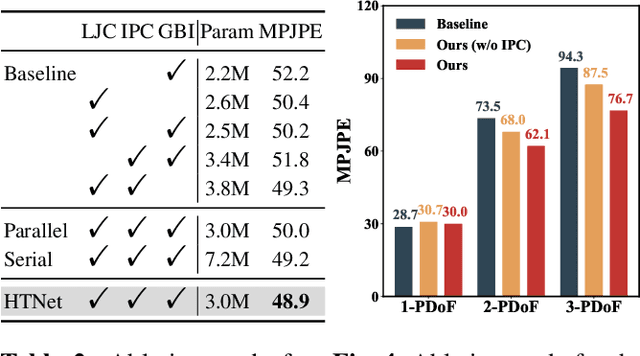
3D human pose estimation errors would propagate along the human body topology and accumulate at the end joints of limbs. Inspired by the backtracking mechanism in automatic control systems, we design an Intra-Part Constraint module that utilizes the parent nodes as the reference to build topological constraints for end joints at the part level. Further considering the hierarchy of the human topology, joint-level and body-level dependencies are captured via graph convolutional networks and self-attentions, respectively. Based on these designs, we propose a novel Human Topology aware Network (HTNet), which adopts a channel-split progressive strategy to sequentially learn the structural priors of the human topology from multiple semantic levels: joint, part, and body. Extensive experiments show that the proposed method improves the estimation accuracy by 18.7% on the end joints of limbs and achieves state-of-the-art results on Human3.6M and MPI-INF-3DHP datasets. Code is available at https://github.com/vefalun/HTNet.
GraphMLP: A Graph MLP-Like Architecture for 3D Human Pose Estimation
Jun 13, 2022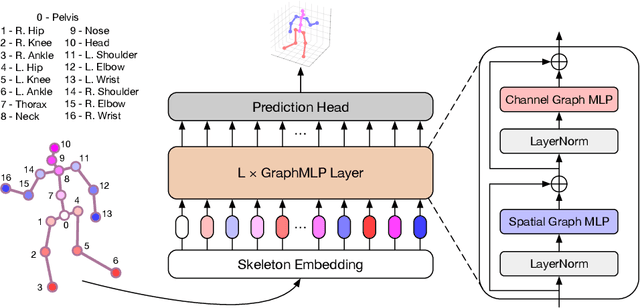
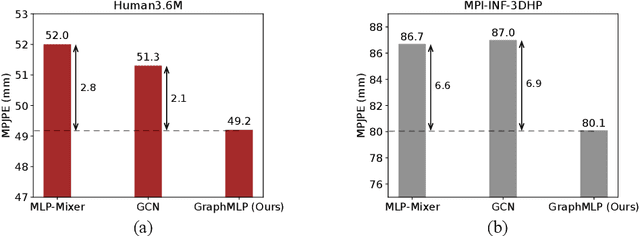
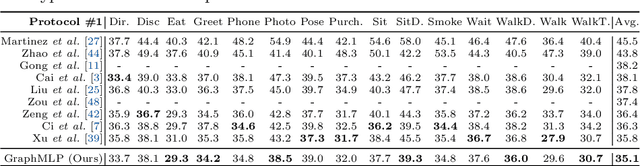
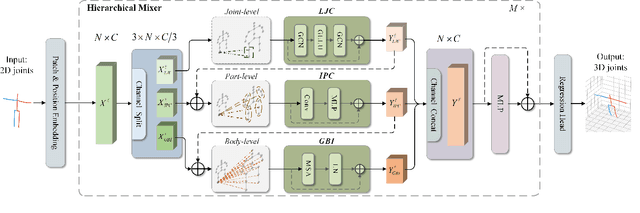
Modern multi-layer perceptron (MLP) models have shown competitive results in learning visual representations without self-attention. However, existing MLP models are not good at capturing local details and lack prior knowledge of human configurations, which limits their modeling power for skeletal representation learning. To address these issues, we propose a simple yet effective graph-reinforced MLP-Like architecture, named GraphMLP, that combines MLPs and graph convolutional networks (GCNs) in a global-local-graphical unified architecture for 3D human pose estimation. GraphMLP incorporates the graph structure of human bodies into an MLP model to meet the domain-specific demand while also allowing for both local and global spatial interactions. Extensive experiments show that the proposed GraphMLP achieves state-of-the-art performance on two datasets, i.e., Human3.6M and MPI-INF-3DHP. Our source code and pretrained models will be publicly available.
Contrastive Learning from Extremely Augmented Skeleton Sequences for Self-supervised Action Recognition
Dec 07, 2021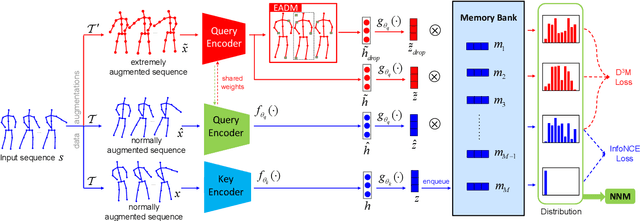
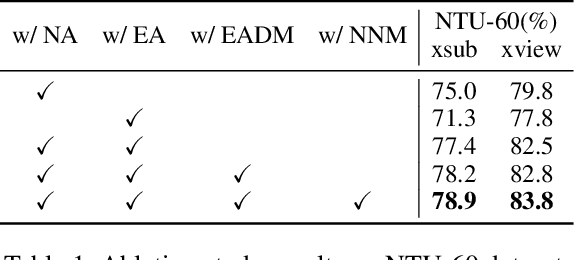
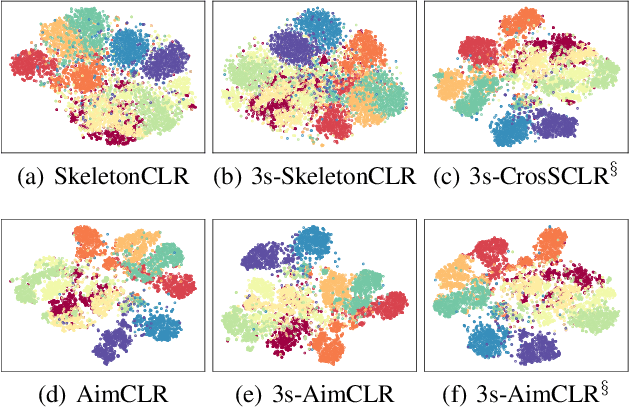
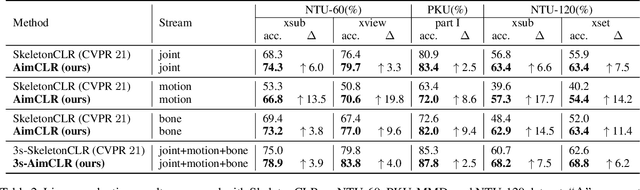
In recent years, self-supervised representation learning for skeleton-based action recognition has been developed with the advance of contrastive learning methods. The existing contrastive learning methods use normal augmentations to construct similar positive samples, which limits the ability to explore novel movement patterns. In this paper, to make better use of the movement patterns introduced by extreme augmentations, a Contrastive Learning framework utilizing Abundant Information Mining for self-supervised action Representation (AimCLR) is proposed. First, the extreme augmentations and the Energy-based Attention-guided Drop Module (EADM) are proposed to obtain diverse positive samples, which bring novel movement patterns to improve the universality of the learned representations. Second, since directly using extreme augmentations may not be able to boost the performance due to the drastic changes in original identity, the Dual Distributional Divergence Minimization Loss (D$^3$M Loss) is proposed to minimize the distribution divergence in a more gentle way. Third, the Nearest Neighbors Mining (NNM) is proposed to further expand positive samples to make the abundant information mining process more reasonable. Exhaustive experiments on NTU RGB+D 60, PKU-MMD, NTU RGB+D 120 datasets have verified that our AimCLR can significantly perform favorably against state-of-the-art methods under a variety of evaluation protocols with observed higher quality action representations. Our code is available at https://github.com/Levigty/AimCLR.