 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modality Co-Learning for Efficient Skeleton-based Action Recognition
Jul 25, 2024
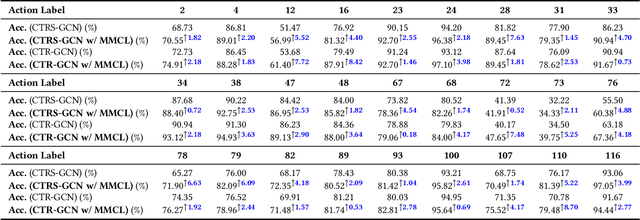
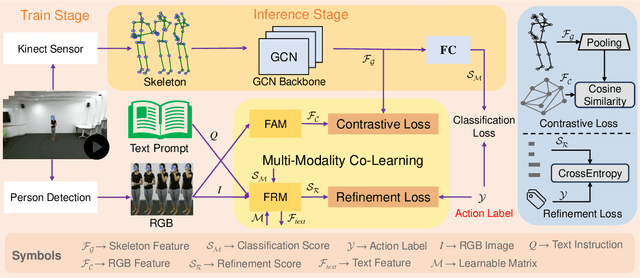

Skeleton-based action recognition has garnered significant attention due to the utilization of concise and resilient skeletons. Nevertheless, the absence of detailed body information in skeletons restricts performance, while other multimodal methods require substantial inference resources and are inefficient when using multimodal data during both training and inference stages. To address this and fully harness the complementary multimodal features, we propose a novel multi-modality co-learning (MMCL) framework by leveraging the multimodal large language models (LLMs) as auxiliary networks for efficient skeleton-based action recognition, which engages in multi-modality co-learning during the training stage and keeps efficiency by employing only concise skeletons in inference. Our MMCL framework primarily consists of two modules. First, the Feature Alignment Module (FAM) extracts rich RGB features from video frames and aligns them with global skeleton features via contrastive learning. Second, the Feature Refinement Module (FRM) uses RGB images with temporal information and text instruction to generate instructive features based on the powerful generalization of multimodal LLMs. These instructive text features will further refine the classification scores and the refined scores will enhance the model's robustness and generalization in a manner similar to soft labels. Extensive experiments on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA benchmarks consistently verify the effectiveness of our MMCL, which outperforms the existing skeleton-based action recognition methods. Meanwhile, experiments on UTD-MHAD and SYSU-Action datasets demonstrate the commendable generalization of our MMCL in zero-shot and domain-adaptive action recognition. Our code is publicly available at: https://github.com/liujf69/MMCL-Action.
SemiPL: A Semi-supervised Method for Event Sound Source Localization
Apr 30, 2024



In recent years, Event Sound Source Localization has been widely applied in various fields. Recent works typically relying on the contrastive learning framework show impressive performance. However, all work is based on large relatively simple datasets. It's also crucial to understand and analyze human behaviors (actions and interactions of people), voices, and sounds in chaotic events in many applications, e.g., crowd management, and emergency response services. In this paper, we apply the existing model to a more complex dataset, explore the influence of parameters on the model, and propose a semi-supervised improvement method SemiPL. With the increase in data quantity and the influence of label quality, self-supervised learning will be an unstoppable trend. The experiment shows that the parameter adjustment will positively affect the existing model. In particular, SSPL achieved an improvement of 12.2% cIoU and 0.56% AUC in Chaotic World compared to the results provided. The code is available at: https://github.com/ly245422/SSPL
HDBN: A Novel Hybrid Dual-branch Network for Robust Skeleton-based Action Recognition
Apr 25, 2024



Skeleton-based action recognition has gained considerable traction thanks to its utilization of succinct and robust skeletal representations. Nonetheless, current methodologies often lean towards utilizing a solitary backbone to model skeleton modality, which can be limited by inherent flaws in the network backbone. To address this and fully leverage the complementary characteristics of various network architectures, we propose a novel Hybrid Dual-Branch Network (HDBN) for robust skeleton-based action recognition, which benefits from the graph convolutional network's proficiency in handling graph-structured data and the powerful modeling capabilities of Transformers for global information. In detail, our proposed HDBN is divided into two trunk branches: MixGCN and MixFormer. The two branches utilize GCNs and Transformers to model both 2D and 3D skeletal modalities respectively. Our proposed HDBN emerged as one of the top solutions in the Multi-Modal Video Reasoning and Analyzing Competition (MMVRAC) of 2024 ICME Grand Challenge, achieving accuracies of 47.95% and 75.36% on two benchmarks of the UAV-Human dataset by outperforming most existing methods. Our code will be publicly available at: https://github.com/liujf69/ICMEW2024-Track10.
SFMViT: SlowFast Meet ViT in Chaotic World
Apr 25, 2024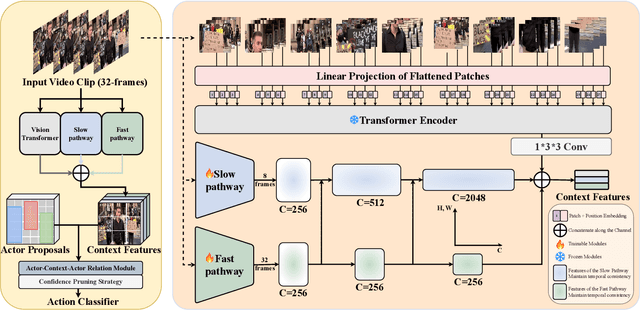
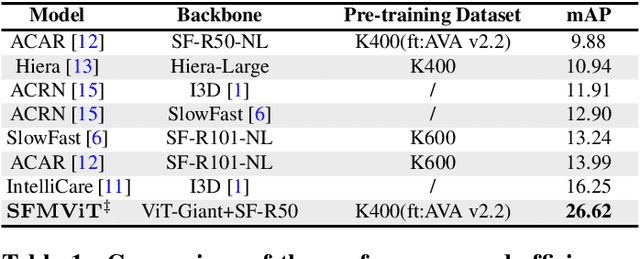
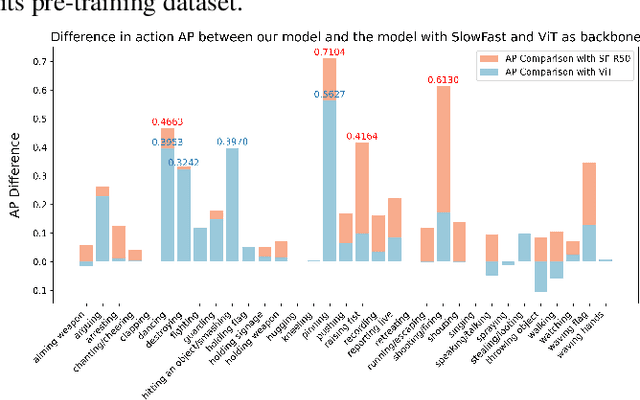

The task of spatiotemporal action localization in chaotic scenes is a challenging task toward advanced video understanding. Paving the way with high-quality video feature extraction and enhancing the precision of detector-predicted anchors can effectively improve model performance. To this end, we propose a high-performance dual-stream spatiotemporal feature extraction network SFMViT with an anchor pruning strategy. The backbone of our SFMViT is composed of ViT and SlowFast with prior knowledge of spatiotemporal action localization, which fully utilizes ViT's excellent global feature extraction capabilities and SlowFast's spatiotemporal sequence modeling capabilities. Secondly, we introduce the confidence maximum heap to prune the anchors detected in each frame of the picture to filter out the effective anchors. These designs enable our SFMViT to achieve a mAP of 26.62% in the Chaotic World dataset, far exceeding existing models. Code is available at https://github.com/jfightyr/SlowFast-Meet-ViT.
Explore Human Parsing Modality for Action Recognition
Jan 04, 2024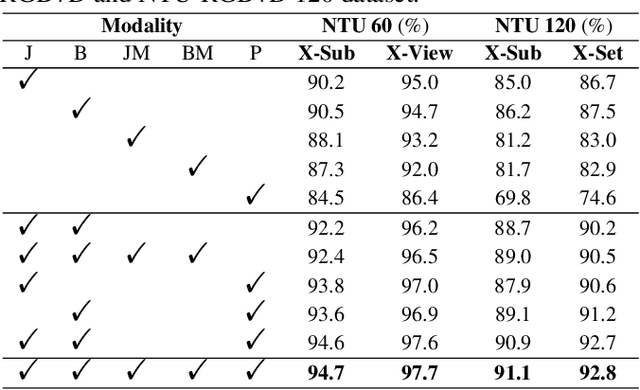

Multimodal-based action recognition methods have achieved high success using pose and RGB modality. However, skeletons sequences lack appearance depiction and RGB images suffer irrelevant noise due to modality limitations. To address this, we introduce human parsing feature map as a novel modality, since it can selectively retain effective semantic features of the body parts, while filtering out most irrelevant noise. We propose a new dual-branch framework called Ensemble Human Parsing and Pose Network (EPP-Net), which is the first to leverage both skeletons and human parsing modalities for action recognition. The first human pose branch feeds robust skeletons in graph convolutional network to model pose features, while the second human parsing branch also leverages depictive parsing feature maps to model parsing festures via convolutional backbones. The two high-level features will be effectively combined through a late fusion strategy for better action recognition. Extensive experiments on NTU RGB+D and NTU RGB+D 120 benchmarks consistently verify the effectiveness of our proposed EPP-Net, which outperforms the existing action recognition methods. Our code is available at: https://github.com/liujf69/EPP-Net-Action.
HouYi: An open-source large language model specially designed for renewable energy and carbon neutrality field
Jul 31, 2023Renewable energy is important for achieving carbon neutrality goal. With the great success of Large Language Models (LLMs) like ChatGPT in automatic content generation, LLMs are playing an increasingly important role. However, there has not been a specially designed LLM for renewable energy. Meanwhile, there has not been any dataset of renewable energy for training LLMs. Therefore, this paper published the first open-source Renewable Energy Academic Paper (REAP) dataset for non-commercial LLM research of renewable energy. REAP dataset is collected through searching the title and abstract of 1,168,970 academic literatures from Web of Science. Based on REAP dataset, HouYi model, the first LLM for renewable energy, is developed through finetuning general LLMs. HouYi demonstrated powerful academic paper paragraph generation ability in renewable energy field. Experiments show that its ability to generate academic papers on renewable energy is comparable to ChatGPT, slightly outperforms Claude, ERNIE Bot and SparkDesk, and significantly outperforms open-source LLaMA-13B model.
Integrating Human Parsing and Pose Network for Human Action Recognition
Jul 16, 2023



Human skeletons and RGB sequences are both widely-adopted input modalities for human action recognition. However, skeletons lack appearance features and color data suffer large amount of irrelevant depiction. To address this, we introduce human parsing feature map as a novel modality, since it can selectively retain spatiotemporal features of the body parts, while filtering out noises regarding outfits, backgrounds, etc. We propose an Integrating Human Parsing and Pose Network (IPP-Net) for action recognition, which is the first to leverage both skeletons and human parsing feature maps in dual-branch approach. The human pose branch feeds compact skeletal representations of different modalities in graph convolutional network to model pose features. In human parsing branch, multi-frame body-part parsing features are extracted with human detector and parser, which is later learnt using a convolutional backbone. A late ensemble of two branches is adopted to get final predictions, considering both robust keypoints and rich semantic body-part features. Extensive experiments on NTU RGB+D and NTU RGB+D 120 benchmarks consistently verify the effectiveness of the proposed IPP-Net, which outperforms the existing action recognition methods. Our code is publicly available at https://github.com/liujf69/IPP-Net-Parsing .
Short-term probabilistic photovoltaic power forecast based on deep convolutional long short-term memory network and kernel density estimation
Jul 03, 2021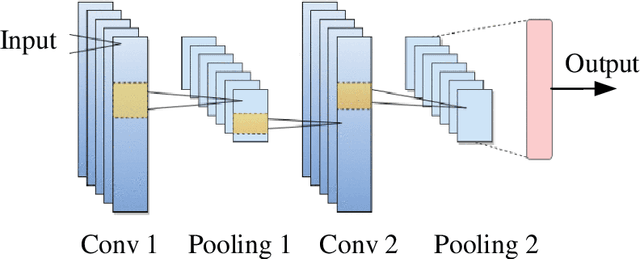
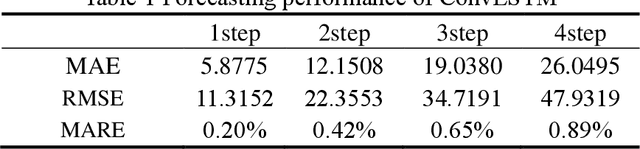
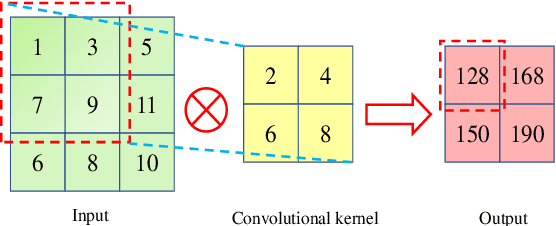

Solar energy is a clean and renewable energy. Photovoltaic (PV) power is an important way to utilize solar energy. Accurate PV power forecast is crucial to the large-scale application of PV power and the stability of electricity grid. This paper proposes a novel method for short-term photovoltaic power forecast using deep convolutional long short-term memory (ConvLSTM) network and kernel density estimation (KDE). In the proposed method, ConvLSTM is used to forecast the future photovoltaic power and KDE is used for estimating the joint probabilistic density function and giving the probabilistic confidence interval. Experiments in an actual photovoltaic power station verify the effectiveness of the proposed method. Comparison experiments with convolutional neural network (CNN) and long short-term memory network (LSTM)shows that ConvLSTM can combine the advantages of both CNN and LSTM and significantly outperform CNN and LSTM in terms of forecast accuracy. Through further comparison with other five conventional methods including multilayer perceptron (MLP), support vector regression (SVR), extreme learning machine (ELM), classification and regression tree (CART) and gradient boosting decision tree (GBDT), ConvLSTM can significantly improve the forecast accuracy by more than 20% for most of the five methods and the superiorities of ConvLSTM are further verified.