 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirrorMamba: Towards Scalable and Robust Mirror Detection in Videos
Nov 10, 2025Video mirror detection has received significant research attention, yet existing methods suffer from limited performance and robustness. These approaches often over-rely on single, unreliable dynamic features, and are typically built on CNNs with limited receptive fields or Transformers with quadratic computational complexity. To address these limitations, we propose a new effective and scalable video mirror detection method, called MirrorMamba. Our approach leverages multiple cues to adapt to diverse conditions, incorporating perceived depth, correspondence and optical. We also introduce an innovative Mamba-based Multidirection Correspondence Extractor, which benefits from the global receptive field and linear complexity of the emerging Mamba spatial state model to effectively capture correspondence properties. Additionally, we design a Mamba-based layer-wise boundary enforcement decoder to resolve the unclear boundary caused by the blurred depth map. Notably, this work marks the first successful application of the Mamba-based architecture in the field of mirror detection. Extensive experiments demonstrate that our method outperforms existing state-of-the-art approaches for video mirror detection on the benchmark datasets. Furthermore, on the most challenging and representative image-based mirror detection dataset, our approach achieves state-of-the-art performance, proving its robustness and generalizability.
Hierarchical Cross-Modal Alignment for Open-Vocabulary 3D Object Detection
Mar 10, 2025



Open-vocabulary 3D object detection (OV-3DOD) aims at localizing and classifying novel objects beyond closed sets. The recent success of vision-language models (VLMs) has demonstrated their remarkable capabilities to understand open vocabularies. Existing works that leverage VLMs for 3D object detection (3DOD) generally resort to representations that lose the rich scene context required for 3D perception. To address this problem, we propose in this paper a hierarchical framework, named HCMA, to simultaneously learn local object and global scene information for OV-3DOD. Specifically, we first design a Hierarchical Data Integration (HDI) approach to obtain coarse-to-fine 3D-image-text data, which is fed into a VLM to extract object-centric knowledge. To facilitate the association of feature hierarchies, we then propose an Interactive Cross-Modal Alignment (ICMA) strategy to establish effective intra-level and inter-level feature connections. To better align features across different levels, we further propose an Object-Focusing Context Adjustment (OFCA) module to refine multi-level features by emphasizing object-related features. Extensive experiments demonstrate that the proposed method outperforms SOTA methods on the existing OV-3DOD benchmarks. It also achieves promising OV-3DOD results even without any 3D annotations.
Do Multimodal Large Language Models See Like Humans?
Dec 12, 2024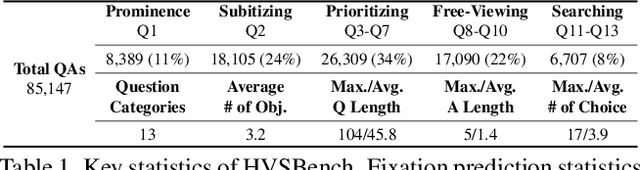

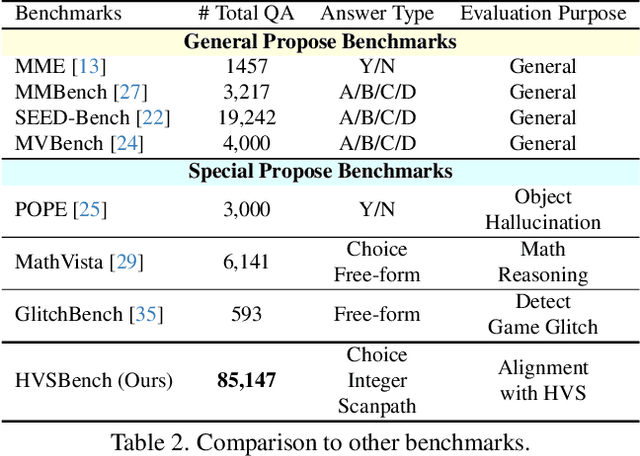

Multimodal Large Language Models (MLLMs) have achieved impressive results on various vision tasks, leveraging recent advancements in large language models. However, a critical question remains unaddressed: do MLLMs perceive visual information similarly to humans? Current benchmarks lack the ability to evaluate MLLMs from this perspective. To address this challenge, we introduce HVSBench, a large-scale benchmark designed to assess the alignment between MLLMs and the human visual system (HVS) on fundamental vision tasks that mirror human vision. HVSBench curated over 85K multimodal samples, spanning 13 categories and 5 fields in HVS, including Prominence, Subitizing, Prioritizing, Free-Viewing, and Searching. Extensive experiments demonstrate the effectiveness of our benchmark in providing a comprehensive evaluation of MLLMs. Specifically, we evaluate 13 MLLMs, revealing that even the best models show significant room for improvement, with most achieving only moderate results. Our experiments reveal that HVSBench presents a new and significant challenge for cutting-edge MLLMs. We believe that HVSBench will facilitate research on human-aligned and explainable MLLMs, marking a key step in understanding how MLLMs perceive and process visual information.
Boosting Weakly-Supervised Referring Image Segmentation via Progressive Comprehension
Oct 02, 2024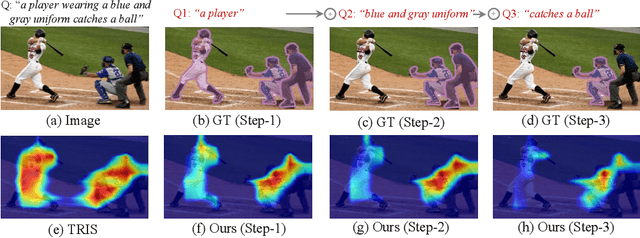
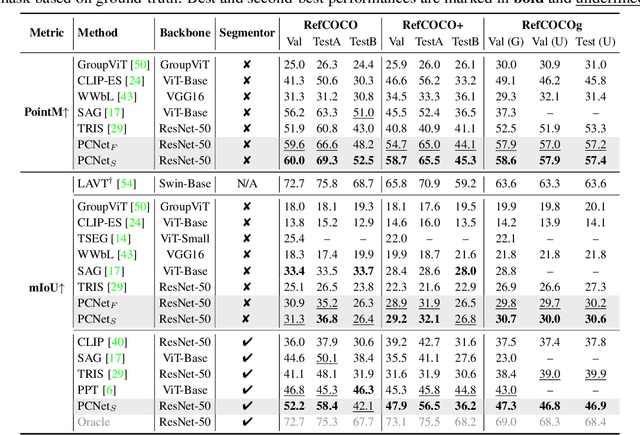
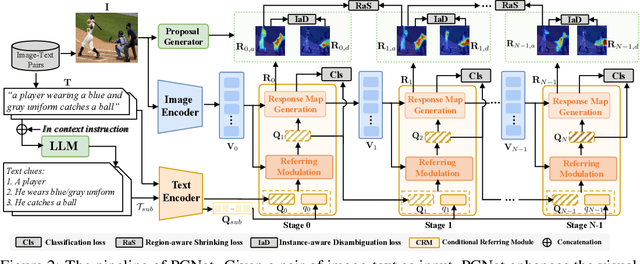
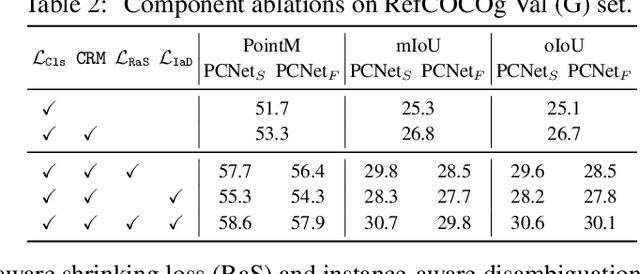
This paper explores the weakly-supervised referring image segmentation (WRIS) problem, and focuses on a challenging setup where target localization is learned directly from image-text pairs. We note that the input text description typically already contains detailed information on how to localize the target object, and we also observe that humans often follow a step-by-step comprehension process (\ie, progressively utilizing target-related attributes and relations as cues) to identify the target object. Hence, we propose a novel Progressive Comprehension Network (PCNet) to leverage target-related textual cues from the input description for progressively localizing the target object. Specifically, we first use a Large Language Model (LLM) to decompose the input text description into short phrases. These short phrases are taken as target-related cues and fed into a Conditional Referring Module (CRM) in multiple stages, to allow updating the referring text embedding and enhance the response map for target localization in a multi-stage manner. Based on the CRM, we then propose a Region-aware Shrinking (RaS) loss to constrain the visual localization to be conducted progressively in a coarse-to-fine manner across different stages. Finally, we introduce an Instance-aware Disambiguation (IaD) loss to suppress instance localization ambiguity by differentiating overlapping response maps generated by different referring texts on the same image. Extensive experiments show that our method outperforms SOTA methods on three common benchmarks.
OpenScan: A Benchmark for Generalized Open-Vocabulary 3D Scene Understanding
Aug 20, 2024



Open-vocabulary 3D scene understanding (OV-3D) aims to localize and classify novel objects beyond the closed object classes. However, existing approaches and benchmarks primarily focus on the open vocabulary problem within the context of object classes, which is insufficient to provide a holistic evaluation to what extent a model understands the 3D scene. In this paper, we introduce a more challenging task called Generalized Open-Vocabulary 3D Scene Understanding (GOV-3D) to explore the open vocabulary problem beyond object classes. It encompasses an open and diverse set of generalized knowledge, expressed as linguistic queries of fine-grained and object-specific attributes. To this end, we contribute a new benchmark named OpenScan, which consists of 3D object attributes across eight representative linguistic aspects, including affordance, property, material, and more. We further evaluate state-of-the-art OV-3D methods on our OpenScan benchmark, and discover that these methods struggle to comprehend the abstract vocabularies of the GOV-3D task, a challenge that cannot be addressed by simply scaling up object classes during training. We highlight the limitations of existing methodologies and explore a promising direction to overcome the identified shortcomings. Data and code are available at https://github.com/YoujunZhao/OpenScan
SemiPL: A Semi-supervised Method for Event Sound Source Localization
Apr 30, 2024



In recent years, Event Sound Source Localization has been widely applied in various fields. Recent works typically relying on the contrastive learning framework show impressive performance. However, all work is based on large relatively simple datasets. It's also crucial to understand and analyze human behaviors (actions and interactions of people), voices, and sounds in chaotic events in many applications, e.g., crowd management, and emergency response services. In this paper, we apply the existing model to a more complex dataset, explore the influence of parameters on the model, and propose a semi-supervised improvement method SemiPL. With the increase in data quantity and the influence of label quality, self-supervised learning will be an unstoppable trend. The experiment shows that the parameter adjustment will positively affect the existing model. In particular, SSPL achieved an improvement of 12.2% cIoU and 0.56% AUC in Chaotic World compared to the results provided. The code is available at: https://github.com/ly245422/SSPL
HDBN: A Novel Hybrid Dual-branch Network for Robust Skeleton-based Action Recognition
Apr 25, 2024



Skeleton-based action recognition has gained considerable traction thanks to its utilization of succinct and robust skeletal representations. Nonetheless, current methodologies often lean towards utilizing a solitary backbone to model skeleton modality, which can be limited by inherent flaws in the network backbone. To address this and fully leverage the complementary characteristics of various network architectures, we propose a novel Hybrid Dual-Branch Network (HDBN) for robust skeleton-based action recognition, which benefits from the graph convolutional network's proficiency in handling graph-structured data and the powerful modeling capabilities of Transformers for global information. In detail, our proposed HDBN is divided into two trunk branches: MixGCN and MixFormer. The two branches utilize GCNs and Transformers to model both 2D and 3D skeletal modalities respectively. Our proposed HDBN emerged as one of the top solutions in the Multi-Modal Video Reasoning and Analyzing Competition (MMVRAC) of 2024 ICME Grand Challenge, achieving accuracies of 47.95% and 75.36% on two benchmarks of the UAV-Human dataset by outperforming most existing methods. Our code will be publicly available at: https://github.com/liujf69/ICMEW2024-Track10.
SFMViT: SlowFast Meet ViT in Chaotic World
Apr 25, 2024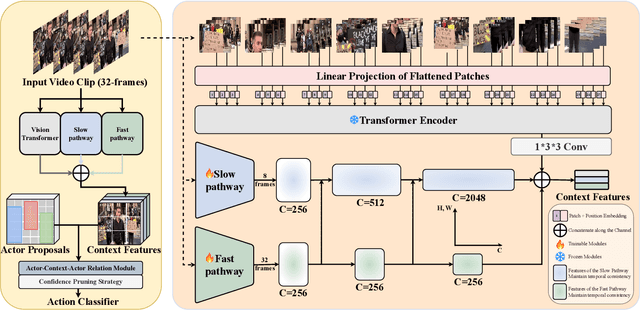
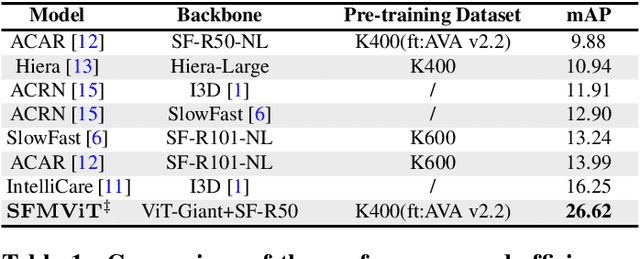
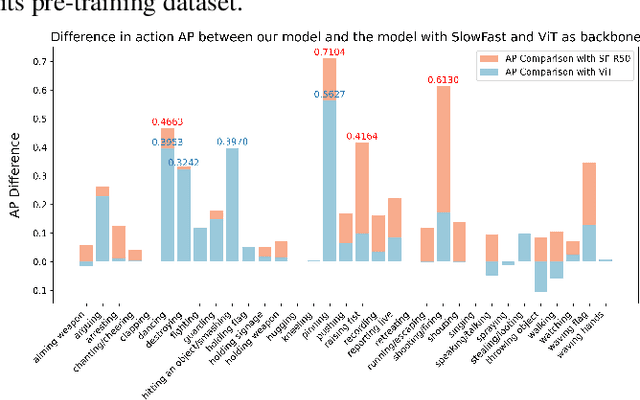

The task of spatiotemporal action localization in chaotic scenes is a challenging task toward advanced video understanding. Paving the way with high-quality video feature extraction and enhancing the precision of detector-predicted anchors can effectively improve model performance. To this end, we propose a high-performance dual-stream spatiotemporal feature extraction network SFMViT with an anchor pruning strategy. The backbone of our SFMViT is composed of ViT and SlowFast with prior knowledge of spatiotemporal action localization, which fully utilizes ViT's excellent global feature extraction capabilities and SlowFast's spatiotemporal sequence modeling capabilities. Secondly, we introduce the confidence maximum heap to prune the anchors detected in each frame of the picture to filter out the effective anchors. These designs enable our SFMViT to achieve a mAP of 26.62% in the Chaotic World dataset, far exceeding existing models. Code is available at https://github.com/jfightyr/SlowFast-Meet-ViT.
Efficient Mirror Detection via Multi-level Heterogeneous Learning
Nov 28, 2022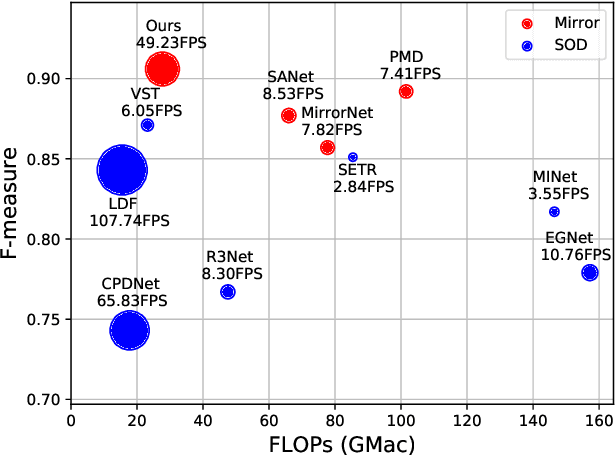
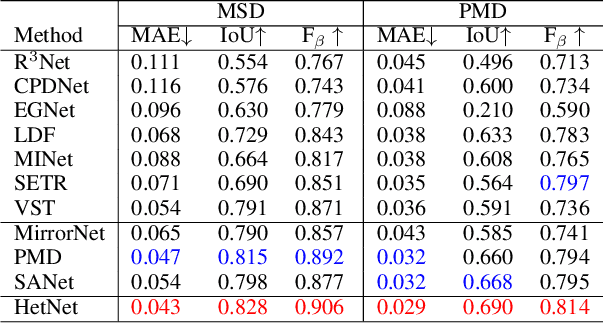
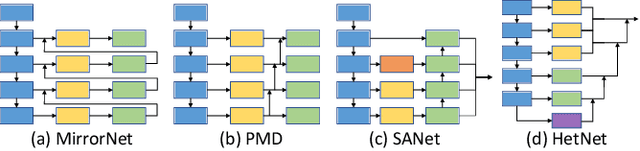
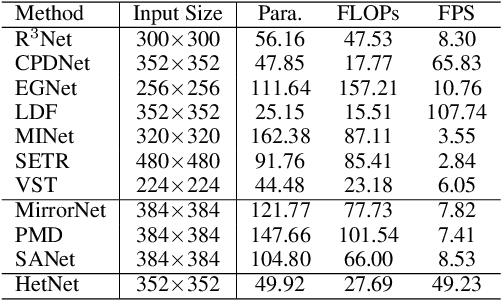
We present HetNet (Multi-level \textbf{Het}erogeneous \textbf{Net}work), a highly efficient mirror detection network. Current mirror detection methods focus more on performance than efficiency, limiting the real-time applications (such as drones). Their lack of efficiency is aroused by the common design of adopting homogeneous modules at different levels, which ignores the difference between different levels of features. In contrast, HetNet detects potential mirror regions initially through low-level understandings (\textit{e.g.}, intensity contrasts) and then combines with high-level understandings (contextual discontinuity for instance) to finalize the predictions. To perform accurate yet efficient mirror detection, HetNet follows an effective architecture that obtains specific information at different stages to detect mirrors. We further propose a multi-orientation intensity-based contrasted module (MIC) and a reflection semantic logical module (RSL), equipped on HetNet, to predict potential mirror regions by low-level understandings and analyze semantic logic in scenarios by high-level understandings, respectively. Compared to the state-of-the-art method, HetNet runs 664$\%$ faster and draws an average performance gain of 8.9$\%$ on MAE, 3.1$\%$ on IoU, and 2.0$\%$ on F-measure on two mirror detection benchmarks.
Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
Jul 28, 2022
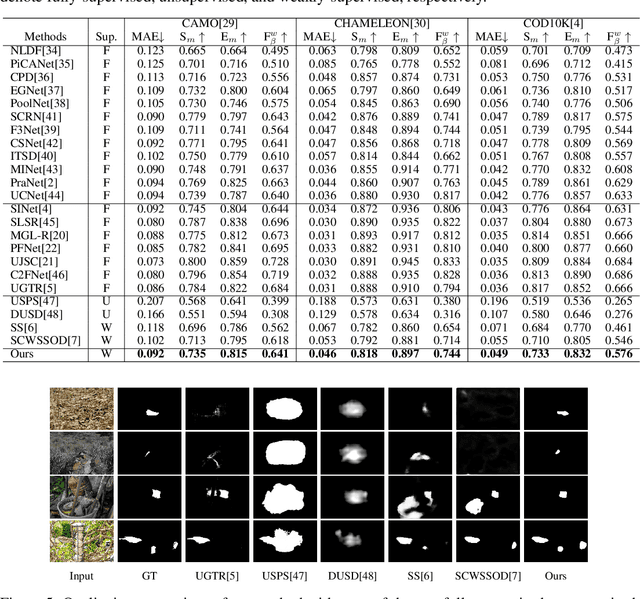
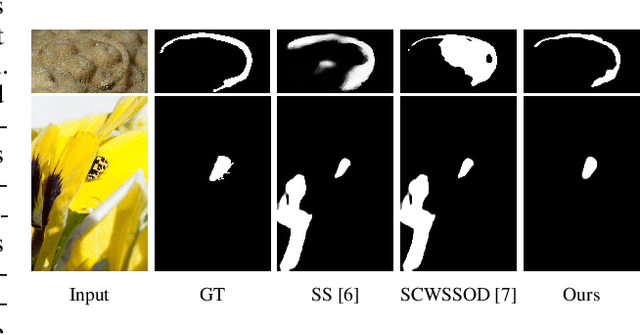
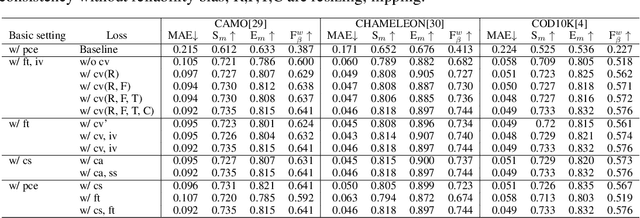
Existing camouflaged object detection (COD) methods rely heavily on large-scale datasets with pixel-wise annotations. However, due to the ambiguous boundary, it is very time-consuming and labor-intensive to annotate camouflage objects pixel-wisely (which takes ~ 60 minutes per image). In this paper, we propose the first weakly-supervised camouflaged object detection (COD) method, using scribble annotations as supervision. To achieve this, we first construct a scribble-based camouflaged object dataset with 4,040 images and corresponding scribble annotations. It is worth noting that annotating the scribbles used in our dataset takes only ~ 10 seconds per image, which is 360 times faster than per-pixel annotations. However, the network directly using scribble annotations for supervision will fail to localize the boundary of camouflaged objects and tend to have inconsistent predictions since scribble annotations only describe the primary structure of objects without details. To tackle this problem, we propose a novel consistency loss composed of two parts: a reliable cross-view loss to attain reliable consistency over different images, and a soft inside-view loss to maintain consistency inside a single prediction map. Besides, we observe that humans use semantic information to segment regions near boundaries of camouflaged objects. Therefore, we design a feature-guided loss, which includes visual features directly extracted from images and semantically significant features captured by models. Moreover, we propose a novel network that detects camouflaged objects by scribble learning on structural information and semantic relations. Experimental results show that our model outperforms relevant state-of-the-art methods on three COD benchmarks with an average improvement of 11.0% on MAE, 3.2% on S-measure, 2.5% on E-measure and 4.4% on weighted F-measure.