 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntityBench: Towards Entity-Consistent Long-Range Multi-Shot Video Generation
May 14, 2026Multi-shot video generation extends single-shot generation to coherent visual narratives, yet maintaining consistent characters, objects, and locations across shots remains a challenge over long sequences. Existing evaluations typically use independently generated prompt sets with limited entity coverage and simple consistency metrics, making standardized comparison difficult. We introduce EntityBench, a benchmark of 140 episodes (2,491 shots) derived from real narrative media, with explicit per-shot entity schedules tracking characters, objects, and locations simultaneously across easy / medium / hard tiers of up to 50 shots, 13 cross-shot characters, 8 cross-shot locations, 22 cross-shot objects, and recurrence gaps spanning up to 48 shots. It is paired with a three-pillar evaluation suite that disentangles intra-shot quality, prompt-following alignment, and cross-shot consistency, with a fidelity gate that admits only accurate entity appearances into cross-shot scoring. As a baseline, we propose EntityMem, a memory-augmented generation system that stores verified per-entity visual references in a persistent memory bank before generation begins. Experiments show that cross-shot entity consistency degrades sharply with recurrence distance in existing methods, and that explicit per-entity memory yields the highest character fidelity (Cohen's d = +2.33) and presence among methods evaluated. Code and data are available at https://github.com/Catherine-R-He/EntityBench/.
Hierarchical Visual Agent: Managing Contexts in Joint Image-Text Space for Advanced Chart Reasoning
May 05, 2026Advanced chart question answering requires both precise perception of small visual elements and multi-step reasoning across several subplots. While existing MLLMs are strong at understanding single plots, they often struggle with multi-step reasoning across multiple subplots. We propose HierVA, a hierarchical visual agent framework for chart reasoning that iteratively constructs and updates a working context in a joint image--text space. A high-level manager generates plans and maintains a compact context containing only key information, while specialized workers perform reasoning, gather evidence, and return results. In particular, the agent maintains separate visual and textual contexts, using a zoom-in tool to restrict the visual context. Experiments on the CharXiv reasoning subset demonstrate consistent improvements over strong multimodal baselines, and ablation studies verify that hierarchical architecture, scoped visual context, and distilled context contribute complementary gains.
Agentic Discovery with Active Hypothesis Exploration for Visual Recognition
Apr 14, 2026We introduce HypoExplore, an agentic framework that formulates neural architecture discovery for visual recognition as a hypothesis-driven scientific inquiry. Given a human-specified high-level research direction, HypoExplore ideates, implements, evaluates, and improves neural architectures through evolutionary branching. New hypotheses are created using a large language model by selecting a parent hypothesis to build upon, guided by a dual strategy that balances exploiting validated principles with resolving uncertain ones. Our proposed framework maintains a Trajectory Tree that records the lineage of all proposed architectures, and a Hypothesis Memory Bank that actively tracks confidence scores acquired through experimental evidence. After each experiment, multiple feedback agents analyze the results from different perspectives and consolidate their findings into hypothesis confidence updates. Our framework is tested on discovering lightweight vision architectures on CIFAR-10, with the best achieving 94.11% accuracy evolved from a root node baseline that starts at 18.91%, and generalizes to CIFAR-100 and Tiny-ImageNet. We further demonstrate applicability to a specialized domain by conducting independent architecture discovery runs on MedMNIST, which yield a state-of-the-art performance. We show that hypothesis confidence scores grow increasingly predictive as evidence accumulates, and that the learned principles transfer across independent evolutionary lineages, suggesting that HypoExplore not only discovers stronger architectures, but can help build a genuine understanding of the design space.
Beyond Referring Expressions: Scenario Comprehension Visual Grounding
Apr 02, 2026Existing visual grounding benchmarks primarily evaluate alignment between image regions and literal referring expressions, where models can often succeed by matching a prominent named category. We explore a complementary and more challenging setting of scenario-based visual grounding, where the target must be inferred from roles, intentions, and relational context rather than explicit naming. We introduce Referring Scenario Comprehension (RSC), a benchmark designed for this setting. The queries in this benchmark are paragraph-length texts that describe object roles, user goals, and contextual cues, including deliberate references to distractor objects that often require deep understanding to resolve. Each instance is annotated with interpretable difficulty tags for uniqueness, clutter, size, overlap, and position which expose distinct failure modes and support fine-grained analysis. RSC contains approximately 31k training examples, 4k in-domain test examples, and a 3k out-of-distribution split with unseen object categories. We further propose ScenGround, a curriculum reasoning method serving as a reference point for this setting, combining supervised warm-starting with difficulty-aware reinforcement learning. Experiments show that scenario-based queries expose systematic failures in current models that standard benchmarks do not reveal, and that curriculum training improves performance on challenging slices and transfers to standard benchmarks.
NoiseShift: Resolution-Aware Noise Recalibration for Better Low-Resolution Image Generation
Oct 02, 2025Text-to-image diffusion models trained on a fixed set of resolutions often fail to generalize, even when asked to generate images at lower resolutions than those seen during training. High-resolution text-to-image generators are currently unable to easily offer an out-of-the-box budget-efficient alternative to their users who might not need high-resolution images. We identify a key technical insight in diffusion models that when addressed can help tackle this limitation: Noise schedulers have unequal perceptual effects across resolutions. The same level of noise removes disproportionately more signal from lower-resolution images than from high-resolution images, leading to a train-test mismatch. We propose NoiseShift, a training-free method that recalibrates the noise level of the denoiser conditioned on resolution size. NoiseShift requires no changes to model architecture or sampling schedule and is compatible with existing models. When applied to Stable Diffusion 3, Stable Diffusion 3.5, and Flux-Dev, quality at low resolutions is significantly improved. On LAION-COCO, NoiseShift improves SD3.5 by 15.89%, SD3 by 8.56%, and Flux-Dev by 2.44% in FID on average. On CelebA, NoiseShift improves SD3.5 by 10.36%, SD3 by 5.19%, and Flux-Dev by 3.02% in FID on average. These results demonstrate the effectiveness of NoiseShift in mitigating resolution-dependent artifacts and enhancing the quality of low-resolution image generation.
Fairness and Bias Mitigation in Computer Vision: A Survey
Aug 05, 2024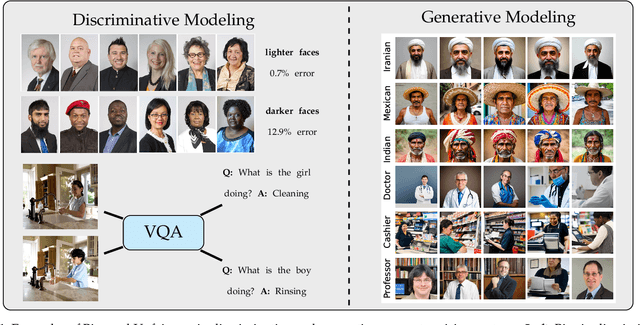
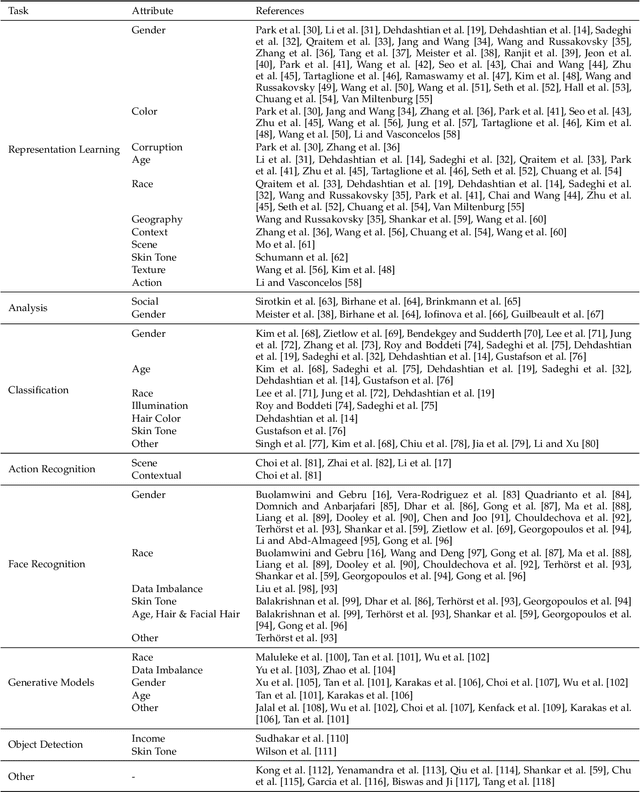
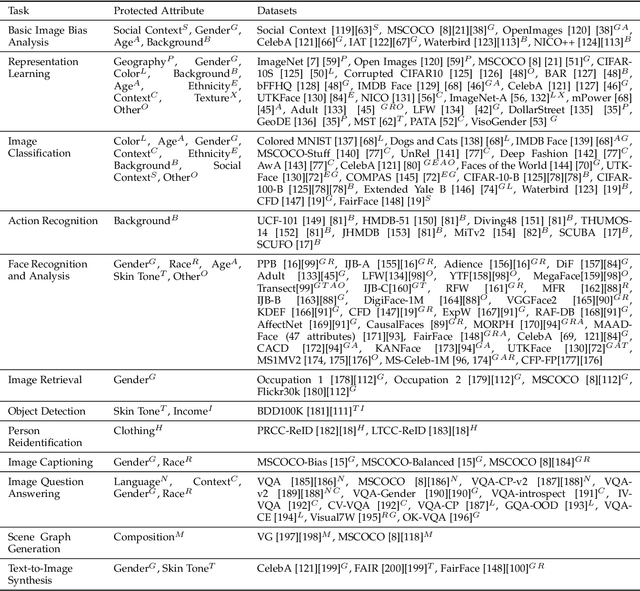
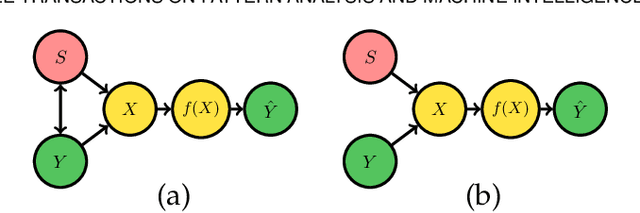
Computer vision systems have witnessed rapid progress over the past two decades due to multiple advances in the field. As these systems are increasingly being deployed in high-stakes real-world applications, there is a dire need to ensure that they do not propagate or amplify any discriminatory tendencies in historical or human-curated data or inadvertently learn biases from spurious correlations. This paper presents a comprehensive survey on fairness that summarizes and sheds light on ongoing trends and successes in the context of computer vision. The topics we discuss include 1) The origin and technical definitions of fairness drawn from the wider fair machine learning literature and adjacent disciplines. 2) Work that sought to discover and analyze biases in computer vision systems. 3) A summary of methods proposed to mitigate bias in computer vision systems in recent years. 4) A comprehensive summary of resources and datasets produced by researchers to measure, analyze, and mitigate bias and enhance fairness. 5) Discussion of the field's success, continuing trends in the context of multimodal foundation and generative models, and gaps that still need to be addressed. The presented characterization should help researchers understand the importance of identifying and mitigating bias in computer vision and the state of the field and identify potential directions for future research.
Learning from Models and Data for Visual Grounding
Mar 20, 2024



We introduce SynGround, a novel framework that combines data-driven learning and knowledge transfer from various large-scale pretrained models to enhance the visual grounding capabilities of a pretrained vision-and-language model. The knowledge transfer from the models initiates the generation of image descriptions through an image description generator. These descriptions serve dual purposes: they act as prompts for synthesizing images through a text-to-image generator, and as queries for synthesizing text, from which phrases are extracted using a large language model. Finally, we leverage an open-vocabulary object detector to generate synthetic bounding boxes for the synthetic images and texts. We finetune a pretrained vision-and-language model on this dataset by optimizing a mask-attention consistency objective that aligns region annotations with gradient-based model explanations. The resulting model improves the grounding capabilities of an off-the-shelf vision-and-language model. Particularly, SynGround improves the pointing game accuracy of ALBEF on the Flickr30k dataset from 79.38% to 87.26%, and on RefCOCO+ Test A from 69.35% to 79.06% and on RefCOCO+ Test B from 53.77% to 63.67%.
Improved Visual Grounding through Self-Consistent Explanations
Dec 07, 2023Vision-and-language models trained to match images with text can be combined with visual explanation methods to point to the locations of specific objects in an image. Our work shows that the localization --"grounding"-- abilities of these models can be further improved by finetuning for self-consistent visual explanations. We propose a strategy for augmenting existing text-image datasets with paraphrases using a large language model, and SelfEQ, a weakly-supervised strategy on visual explanation maps for paraphrases that encourages self-consistency. Specifically, for an input textual phrase, we attempt to generate a paraphrase and finetune the model so that the phrase and paraphrase map to the same region in the image. We posit that this both expands the vocabulary that the model is able to handle, and improves the quality of the object locations highlighted by gradient-based visual explanation methods (e.g. GradCAM). We demonstrate that SelfEQ improves performance on Flickr30k, ReferIt, and RefCOCO+ over a strong baseline method and several prior works. Particularly, comparing to other methods that do not use any type of box annotations, we obtain 84.07% on Flickr30k (an absolute improvement of 4.69%), 67.40% on ReferIt (an absolute improvement of 7.68%), and 75.10%, 55.49% on RefCOCO+ test sets A and B respectively (an absolute improvement of 3.74% on average).
Efficient Mirror Detection via Multi-level Heterogeneous Learning
Nov 28, 2022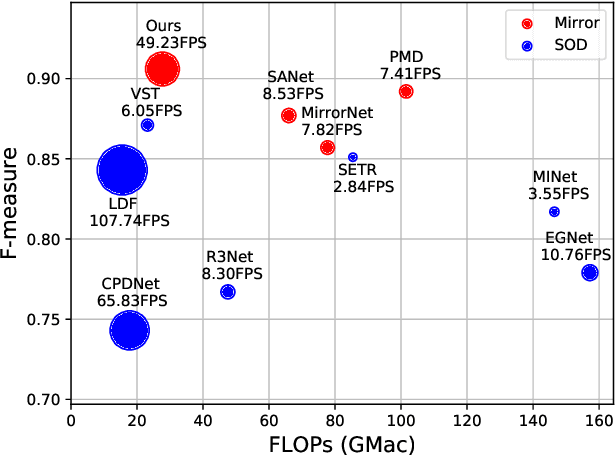
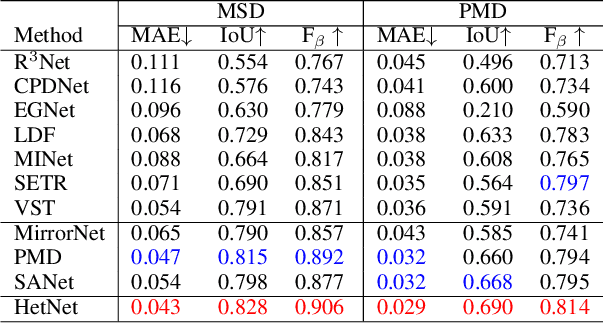
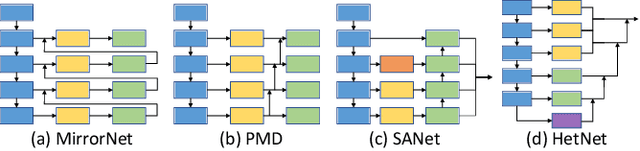
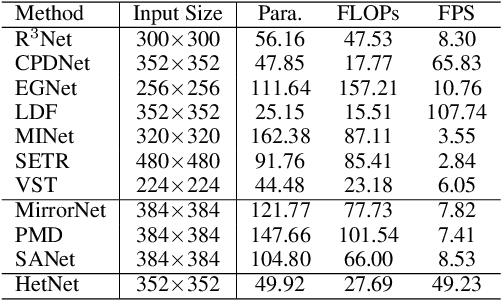
We present HetNet (Multi-level \textbf{Het}erogeneous \textbf{Net}work), a highly efficient mirror detection network. Current mirror detection methods focus more on performance than efficiency, limiting the real-time applications (such as drones). Their lack of efficiency is aroused by the common design of adopting homogeneous modules at different levels, which ignores the difference between different levels of features. In contrast, HetNet detects potential mirror regions initially through low-level understandings (\textit{e.g.}, intensity contrasts) and then combines with high-level understandings (contextual discontinuity for instance) to finalize the predictions. To perform accurate yet efficient mirror detection, HetNet follows an effective architecture that obtains specific information at different stages to detect mirrors. We further propose a multi-orientation intensity-based contrasted module (MIC) and a reflection semantic logical module (RSL), equipped on HetNet, to predict potential mirror regions by low-level understandings and analyze semantic logic in scenarios by high-level understandings, respectively. Compared to the state-of-the-art method, HetNet runs 664$\%$ faster and draws an average performance gain of 8.9$\%$ on MAE, 3.1$\%$ on IoU, and 2.0$\%$ on F-measure on two mirror detection benchmarks.
Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
Jul 28, 2022
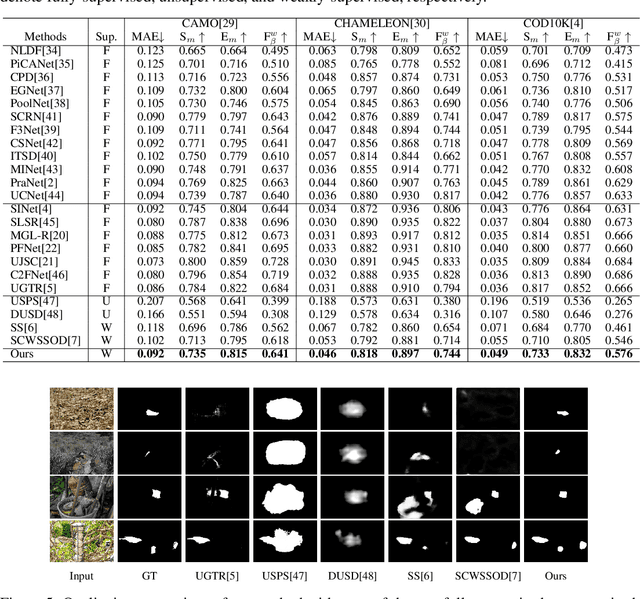
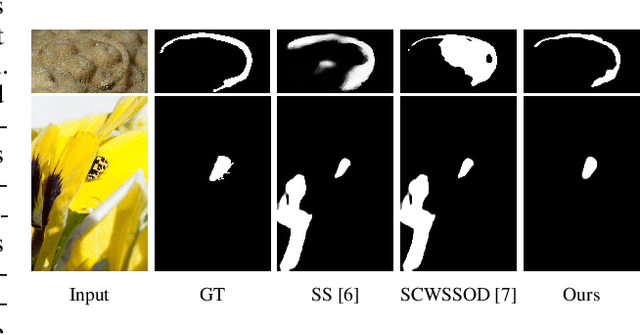
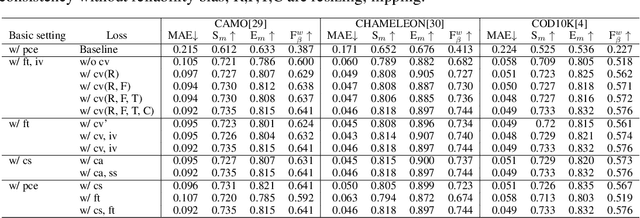
Existing camouflaged object detection (COD) methods rely heavily on large-scale datasets with pixel-wise annotations. However, due to the ambiguous boundary, it is very time-consuming and labor-intensive to annotate camouflage objects pixel-wisely (which takes ~ 60 minutes per image). In this paper, we propose the first weakly-supervised camouflaged object detection (COD) method, using scribble annotations as supervision. To achieve this, we first construct a scribble-based camouflaged object dataset with 4,040 images and corresponding scribble annotations. It is worth noting that annotating the scribbles used in our dataset takes only ~ 10 seconds per image, which is 360 times faster than per-pixel annotations. However, the network directly using scribble annotations for supervision will fail to localize the boundary of camouflaged objects and tend to have inconsistent predictions since scribble annotations only describe the primary structure of objects without details. To tackle this problem, we propose a novel consistency loss composed of two parts: a reliable cross-view loss to attain reliable consistency over different images, and a soft inside-view loss to maintain consistency inside a single prediction map. Besides, we observe that humans use semantic information to segment regions near boundaries of camouflaged objects. Therefore, we design a feature-guided loss, which includes visual features directly extracted from images and semantically significant features captured by models. Moreover, we propose a novel network that detects camouflaged objects by scribble learning on structural information and semantic relations. Experimental results show that our model outperforms relevant state-of-the-art methods on three COD benchmarks with an average improvement of 11.0% on MAE, 3.2% on S-measure, 2.5% on E-measure and 4.4% on weighted F-measure.