 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generative Modeling from Decentralized Data
Jun 08, 2026Learning the compositional nature of the physical world requires joint observation of interacting factors. However, because practical data is often decentralized, these factors are fragmented across isolated silos. Existing decentralized generative approaches focus only on modeling the union of siloed data, overlooking novel combinations implied by the collective whole. To bridge this gap, we introduce Decentralized Compositional Flow Matching (DCFM), a framework that enforces structural constraints across the global set of generative factors, without exchanging any raw data. DCFM enables novel combinations to emerge through peer interactions, even when no single data source can independently support the composition. Empirically, DCFM substantially outperforms federated learning and mixture-of-experts baselines across conditional image generation, robotic spatial planning, and medical attribute co-occurrence modeling.
PolyJuice Makes It Real: Black-Box, Universal Red Teaming for Synthetic Image Detectors
Sep 19, 2025Synthetic image detectors (SIDs) are a key defense against the risks posed by the growing realism of images from text-to-image (T2I) models. Red teaming improves SID's effectiveness by identifying and exploiting their failure modes via misclassified synthetic images. However, existing red-teaming solutions (i) require white-box access to SIDs, which is infeasible for proprietary state-of-the-art detectors, and (ii) generate image-specific attacks through expensive online optimization. To address these limitations, we propose PolyJuice, the first black-box, image-agnostic red-teaming method for SIDs, based on an observed distribution shift in the T2I latent space between samples correctly and incorrectly classified by the SID. PolyJuice generates attacks by (i) identifying the direction of this shift through a lightweight offline process that only requires black-box access to the SID, and (ii) exploiting this direction by universally steering all generated images towards the SID's failure modes. PolyJuice-steered T2I models are significantly more effective at deceiving SIDs (up to 84%) compared to their unsteered counterparts. We also show that the steering directions can be estimated efficiently at lower resolutions and transferred to higher resolutions using simple interpolation, reducing computational overhead. Finally, tuning SID models on PolyJuice-augmented datasets notably enhances the performance of the detectors (up to 30%).
OASIS Uncovers: High-Quality T2I Models, Same Old Stereotypes
Jan 01, 2025



Images generated by text-to-image (T2I) models often exhibit visual biases and stereotypes of concepts such as culture and profession. Existing quantitative measures of stereotypes are based on statistical parity that does not align with the sociological definition of stereotypes and, therefore, incorrectly categorizes biases as stereotypes. Instead of oversimplifying stereotypes as biases, we propose a quantitative measure of stereotypes that aligns with its sociological definition. We then propose OASIS to measure the stereotypes in a generated dataset and understand their origins within the T2I model. OASIS includes two scores to measure stereotypes from a generated image dataset: (M1) Stereotype Score to measure the distributional violation of stereotypical attributes, and (M2) WALS to measure spectral variance in the images along a stereotypical attribute. OASIS also includes two methods to understand the origins of stereotypes in T2I models: (U1) StOP to discover attributes that the T2I model internally associates with a given concept, and (U2) SPI to quantify the emergence of stereotypical attributes in the latent space of the T2I model during image generation. Despite the considerable progress in image fidelity, using OASIS, we conclude that newer T2I models such as FLUX.1 and SDv3 contain strong stereotypical predispositions about concepts and still generate images with widespread stereotypical attributes. Additionally, the quantity of stereotypes worsens for nationalities with lower Internet footprints.
Fairness and Bias Mitigation in Computer Vision: A Survey
Aug 05, 2024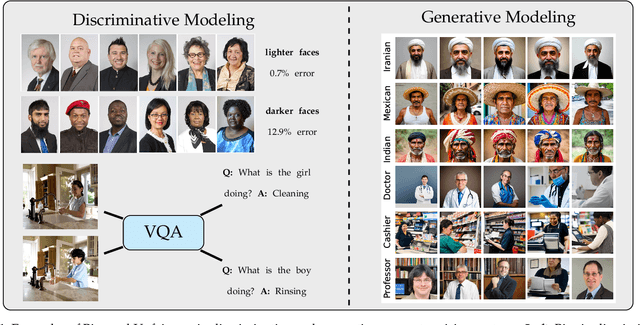
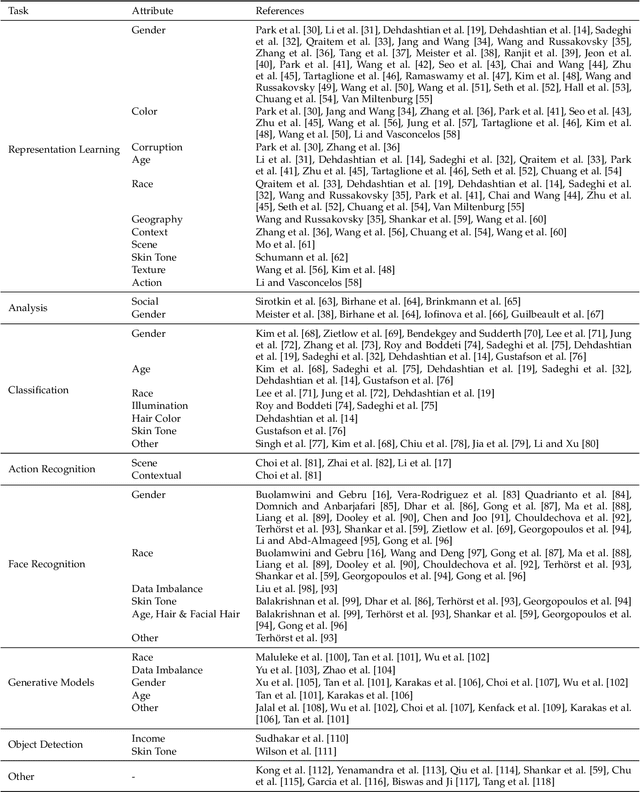
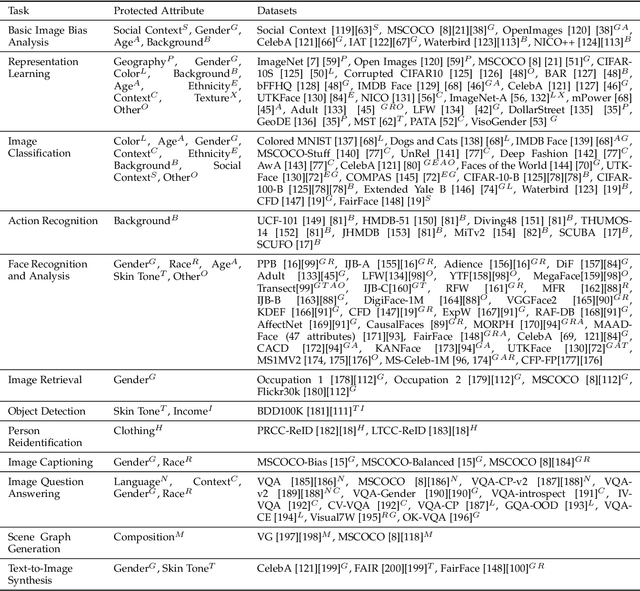
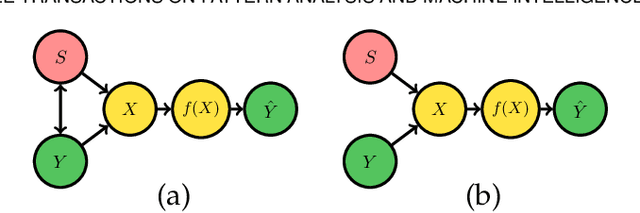
Computer vision systems have witnessed rapid progress over the past two decades due to multiple advances in the field. As these systems are increasingly being deployed in high-stakes real-world applications, there is a dire need to ensure that they do not propagate or amplify any discriminatory tendencies in historical or human-curated data or inadvertently learn biases from spurious correlations. This paper presents a comprehensive survey on fairness that summarizes and sheds light on ongoing trends and successes in the context of computer vision. The topics we discuss include 1) The origin and technical definitions of fairness drawn from the wider fair machine learning literature and adjacent disciplines. 2) Work that sought to discover and analyze biases in computer vision systems. 3) A summary of methods proposed to mitigate bias in computer vision systems in recent years. 4) A comprehensive summary of resources and datasets produced by researchers to measure, analyze, and mitigate bias and enhance fairness. 5) Discussion of the field's success, continuing trends in the context of multimodal foundation and generative models, and gaps that still need to be addressed. The presented characterization should help researchers understand the importance of identifying and mitigating bias in computer vision and the state of the field and identify potential directions for future research.
Utility-Fairness Trade-Offs and How to Find Them
Apr 15, 2024When building classification systems with demographic fairness considerations, there are two objectives to satisfy: 1) maximizing utility for the specific task and 2) ensuring fairness w.r.t. a known demographic attribute. These objectives often compete, so optimizing both can lead to a trade-off between utility and fairness. While existing works acknowledge the trade-offs and study their limits, two questions remain unanswered: 1) What are the optimal trade-offs between utility and fairness? and 2) How can we numerically quantify these trade-offs from data for a desired prediction task and demographic attribute of interest? This paper addresses these questions. We introduce two utility-fairness trade-offs: the Data-Space and Label-Space Trade-off. The trade-offs reveal three regions within the utility-fairness plane, delineating what is fully and partially possible and impossible. We propose U-FaTE, a method to numerically quantify the trade-offs for a given prediction task and group fairness definition from data samples. Based on the trade-offs, we introduce a new scheme for evaluating representations. An extensive evaluation of fair representation learning methods and representations from over 1000 pre-trained models revealed that most current approaches are far from the estimated and achievable fairness-utility trade-offs across multiple datasets and prediction tasks.
FairerCLIP: Debiasing CLIP's Zero-Shot Predictions using Functions in RKHSs
Mar 22, 2024Large pre-trained vision-language models such as CLIP provide compact and general-purpose representations of text and images that are demonstrably effective across multiple downstream zero-shot prediction tasks. However, owing to the nature of their training process, these models have the potential to 1) propagate or amplify societal biases in the training data and 2) learn to rely on spurious features. This paper proposes FairerCLIP, a general approach for making zero-shot predictions of CLIP more fair and robust to spurious correlations. We formulate the problem of jointly debiasing CLIP's image and text representations in reproducing kernel Hilbert spaces (RKHSs), which affords multiple benefits: 1) Flexibility: Unlike existing approaches, which are specialized to either learn with or without ground-truth labels, FairerCLIP is adaptable to learning in both scenarios. 2) Ease of Optimization: FairerCLIP lends itself to an iterative optimization involving closed-form solvers, which leads to $4\times$-$10\times$ faster training than the existing methods. 3) Sample Efficiency: Under sample-limited conditions, FairerCLIP significantly outperforms baselines when they fail entirely. And, 4) Performance: Empirically, FairerCLIP achieves appreciable accuracy gains on benchmark fairness and spurious correlation datasets over their respective baselines.
Mechanics-Informed Autoencoder Enables Automated Detection and Localization of Unforeseen Structural Damage
Feb 23, 2024Structural health monitoring (SHM) is vital for ensuring the safety and longevity of structures like buildings and bridges. As the volume and scale of structures and the impact of their failure continue to grow, there is a dire need for SHM techniques that are scalable, inexpensive, operate passively without human intervention, and customized for each mechanical structure without the need for complex baseline models. We present a novel "deploy-and-forget" approach for automated detection and localization of damages in structures. It is based on a synergistic combination of fully passive measurements from inexpensive sensors and a mechanics-informed autoencoder. Once deployed, our solution continuously learns and adapts a bespoke baseline model for each structure, learning from its undamaged state's response characteristics. After learning from just 3 hours of data, it can autonomously detect and localize different types of unforeseen damage. Results from numerical simulations and experiments indicate that incorporating the mechanical characteristics into the variational autoencoder allows for up to 35\% earlier detection and localization of damage over a standard autoencoder. Our approach holds substantial promise for a significant reduction in human intervention and inspection costs and enables proactive and preventive maintenance strategies, thus extending the lifespan, reliability, and sustainability of civil infrastructures.
AutoFHE: Automated Adaption of CNNs for Efficient Evaluation over FHE
Oct 12, 2023

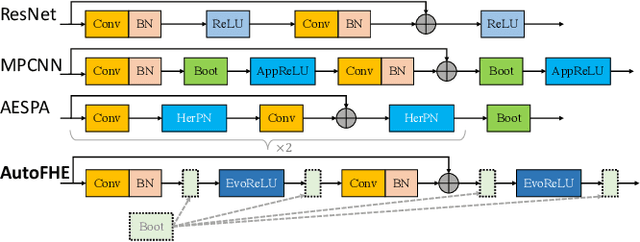
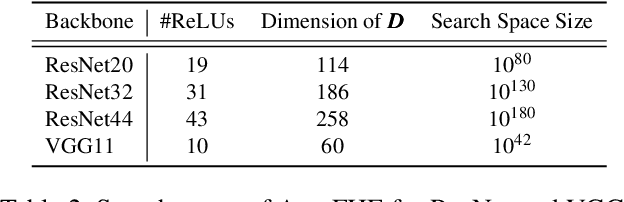
Secure inference of deep convolutional neural networks (CNNs) under RNS-CKKS involves polynomial approximation of unsupported non-linear activation functions. However, existing approaches have three main limitations: 1) Inflexibility: The polynomial approximation and associated homomorphic evaluation architecture are customized manually for each CNN architecture and do not generalize to other networks. 2) Suboptimal Approximation: Each activation function is approximated instead of the function represented by the CNN. 3) Restricted Design: Either high-degree or low-degree polynomial approximations are used. The former retains high accuracy but slows down inference due to bootstrapping operations, while the latter accelerates ciphertext inference but compromises accuracy. To address these limitations, we present AutoFHE, which automatically adapts standard CNNs for secure inference under RNS-CKKS. The key idea is to adopt layerwise mixed-degree polynomial activation functions, which are optimized jointly with the homomorphic evaluation architecture in terms of the placement of bootstrapping operations. The problem is modeled within a multi-objective optimization framework to maximize accuracy and minimize the number of bootstrapping operations. AutoFHE can be applied flexibly on any CNN architecture, and it provides diverse solutions that span the trade-off between accuracy and latency. Experimental evaluation over RNS-CKKS encrypted CIFAR datasets shows that AutoFHE accelerates secure inference by $1.32\times$ to $1.8\times$ compared to methods employing high-degree polynomials. It also improves accuracy by up to 2.56% compared to methods using low-degree polynomials. Lastly, AutoFHE accelerates inference and improves accuracy by $103\times$ and 3.46%, respectively, compared to CNNs under TFHE.
Spurious Correlations and Where to Find Them
Aug 21, 2023



Spurious correlations occur when a model learns unreliable features from the data and are a well-known drawback of data-driven learning. Although there are several algorithms proposed to mitigate it, we are yet to jointly derive the indicators of spurious correlations. As a result, the solutions built upon standalone hypotheses fail to beat simple ERM baselines. We collect some of the commonly studied hypotheses behind the occurrence of spurious correlations and investigate their influence on standard ERM baselines using synthetic datasets generated from causal graphs. Subsequently, we observe patterns connecting these hypotheses and model design choices.
Seed Feature Maps-based CNN Models for LEO Satellite Remote Sensing Services
Aug 12, 2023Deploying high-performance convolutional neural network (CNN) models on low-earth orbit (LEO) satellites for rapid remote sensing image processing has attracted significant interest from industry and academia. However, the limited resources available on LEO satellites contrast with the demands of resource-intensive CNN models, necessitating the adoption of ground-station server assistance for training and updating these models. Existing approaches often require large floating-point operations (FLOPs) and substantial model parameter transmissions, presenting considerable challenges. To address these issues, this paper introduces a ground-station server-assisted framework. With the proposed framework, each layer of the CNN model contains only one learnable feature map (called the seed feature map) from which other feature maps are generated based on specific rules. The hyperparameters of these rules are randomly generated instead of being trained, thus enabling the generation of multiple feature maps from the seed feature map and significantly reducing FLOPs. Furthermore, since the random hyperparameters can be saved using a few random seeds, the ground station server assistance can be facilitated in updating the CNN model deployed on the LEO satellite. Experimental results on the ISPRS Vaihingen, ISPRS Potsdam, UAVid, and LoveDA datasets for semantic segmentation services demonstrate that the proposed framework outperforms existing state-of-the-art approaches. In particular, the SineFM-based model achieves a higher mIoU than the UNetFormer on the UAVid dataset, with 3.3x fewer parameters and 2.2x fewer FLOPs.