 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyJuice Makes It Real: Black-Box, Universal Red Teaming for Synthetic Image Detectors
Sep 19, 2025Synthetic image detectors (SIDs) are a key defense against the risks posed by the growing realism of images from text-to-image (T2I) models. Red teaming improves SID's effectiveness by identifying and exploiting their failure modes via misclassified synthetic images. However, existing red-teaming solutions (i) require white-box access to SIDs, which is infeasible for proprietary state-of-the-art detectors, and (ii) generate image-specific attacks through expensive online optimization. To address these limitations, we propose PolyJuice, the first black-box, image-agnostic red-teaming method for SIDs, based on an observed distribution shift in the T2I latent space between samples correctly and incorrectly classified by the SID. PolyJuice generates attacks by (i) identifying the direction of this shift through a lightweight offline process that only requires black-box access to the SID, and (ii) exploiting this direction by universally steering all generated images towards the SID's failure modes. PolyJuice-steered T2I models are significantly more effective at deceiving SIDs (up to 84%) compared to their unsteered counterparts. We also show that the steering directions can be estimated efficiently at lower resolutions and transferred to higher resolutions using simple interpolation, reducing computational overhead. Finally, tuning SID models on PolyJuice-augmented datasets notably enhances the performance of the detectors (up to 30%).
OASIS Uncovers: High-Quality T2I Models, Same Old Stereotypes
Jan 01, 2025



Images generated by text-to-image (T2I) models often exhibit visual biases and stereotypes of concepts such as culture and profession. Existing quantitative measures of stereotypes are based on statistical parity that does not align with the sociological definition of stereotypes and, therefore, incorrectly categorizes biases as stereotypes. Instead of oversimplifying stereotypes as biases, we propose a quantitative measure of stereotypes that aligns with its sociological definition. We then propose OASIS to measure the stereotypes in a generated dataset and understand their origins within the T2I model. OASIS includes two scores to measure stereotypes from a generated image dataset: (M1) Stereotype Score to measure the distributional violation of stereotypical attributes, and (M2) WALS to measure spectral variance in the images along a stereotypical attribute. OASIS also includes two methods to understand the origins of stereotypes in T2I models: (U1) StOP to discover attributes that the T2I model internally associates with a given concept, and (U2) SPI to quantify the emergence of stereotypical attributes in the latent space of the T2I model during image generation. Despite the considerable progress in image fidelity, using OASIS, we conclude that newer T2I models such as FLUX.1 and SDv3 contain strong stereotypical predispositions about concepts and still generate images with widespread stereotypical attributes. Additionally, the quantity of stereotypes worsens for nationalities with lower Internet footprints.
Fairness and Bias Mitigation in Computer Vision: A Survey
Aug 05, 2024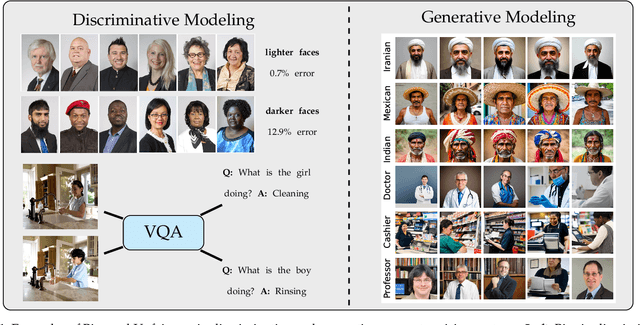
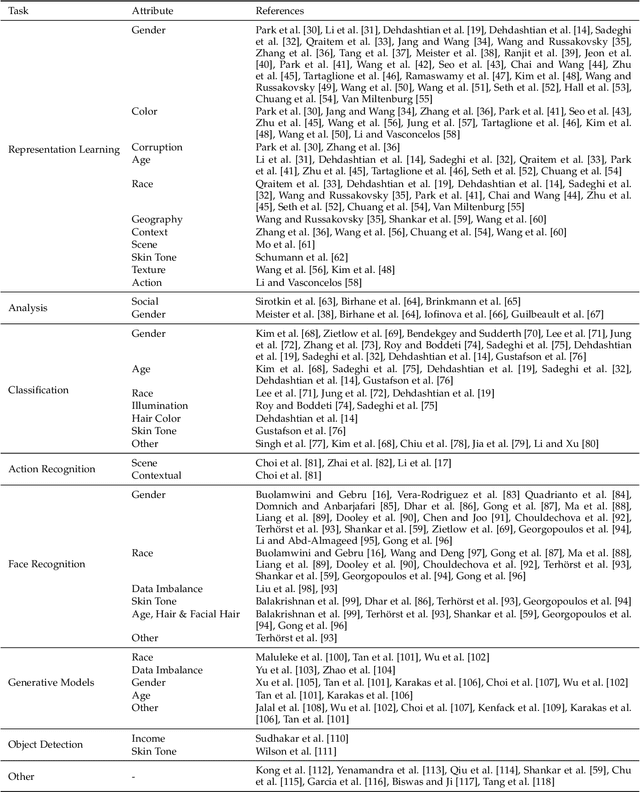
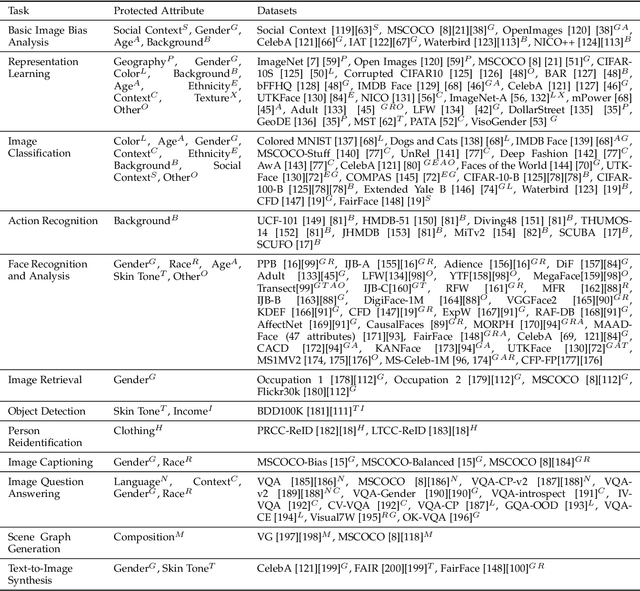
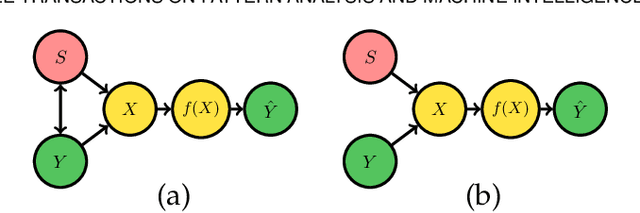
Computer vision systems have witnessed rapid progress over the past two decades due to multiple advances in the field. As these systems are increasingly being deployed in high-stakes real-world applications, there is a dire need to ensure that they do not propagate or amplify any discriminatory tendencies in historical or human-curated data or inadvertently learn biases from spurious correlations. This paper presents a comprehensive survey on fairness that summarizes and sheds light on ongoing trends and successes in the context of computer vision. The topics we discuss include 1) The origin and technical definitions of fairness drawn from the wider fair machine learning literature and adjacent disciplines. 2) Work that sought to discover and analyze biases in computer vision systems. 3) A summary of methods proposed to mitigate bias in computer vision systems in recent years. 4) A comprehensive summary of resources and datasets produced by researchers to measure, analyze, and mitigate bias and enhance fairness. 5) Discussion of the field's success, continuing trends in the context of multimodal foundation and generative models, and gaps that still need to be addressed. The presented characterization should help researchers understand the importance of identifying and mitigating bias in computer vision and the state of the field and identify potential directions for future research.
Utility-Fairness Trade-Offs and How to Find Them
Apr 15, 2024When building classification systems with demographic fairness considerations, there are two objectives to satisfy: 1) maximizing utility for the specific task and 2) ensuring fairness w.r.t. a known demographic attribute. These objectives often compete, so optimizing both can lead to a trade-off between utility and fairness. While existing works acknowledge the trade-offs and study their limits, two questions remain unanswered: 1) What are the optimal trade-offs between utility and fairness? and 2) How can we numerically quantify these trade-offs from data for a desired prediction task and demographic attribute of interest? This paper addresses these questions. We introduce two utility-fairness trade-offs: the Data-Space and Label-Space Trade-off. The trade-offs reveal three regions within the utility-fairness plane, delineating what is fully and partially possible and impossible. We propose U-FaTE, a method to numerically quantify the trade-offs for a given prediction task and group fairness definition from data samples. Based on the trade-offs, we introduce a new scheme for evaluating representations. An extensive evaluation of fair representation learning methods and representations from over 1000 pre-trained models revealed that most current approaches are far from the estimated and achievable fairness-utility trade-offs across multiple datasets and prediction tasks.
FairerCLIP: Debiasing CLIP's Zero-Shot Predictions using Functions in RKHSs
Mar 22, 2024Large pre-trained vision-language models such as CLIP provide compact and general-purpose representations of text and images that are demonstrably effective across multiple downstream zero-shot prediction tasks. However, owing to the nature of their training process, these models have the potential to 1) propagate or amplify societal biases in the training data and 2) learn to rely on spurious features. This paper proposes FairerCLIP, a general approach for making zero-shot predictions of CLIP more fair and robust to spurious correlations. We formulate the problem of jointly debiasing CLIP's image and text representations in reproducing kernel Hilbert spaces (RKHSs), which affords multiple benefits: 1) Flexibility: Unlike existing approaches, which are specialized to either learn with or without ground-truth labels, FairerCLIP is adaptable to learning in both scenarios. 2) Ease of Optimization: FairerCLIP lends itself to an iterative optimization involving closed-form solvers, which leads to $4\times$-$10\times$ faster training than the existing methods. 3) Sample Efficiency: Under sample-limited conditions, FairerCLIP significantly outperforms baselines when they fail entirely. And, 4) Performance: Empirically, FairerCLIP achieves appreciable accuracy gains on benchmark fairness and spurious correlation datasets over their respective baselines.
Deep-Learning Based Blind Recognition of Channel Code Parameters over Candidate Sets under AWGN and Multi-Path Fading Conditions
Sep 16, 2020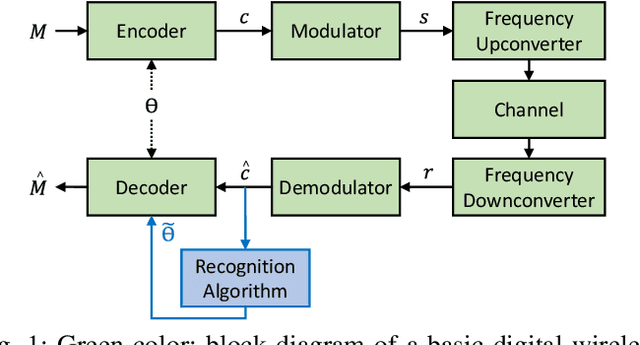
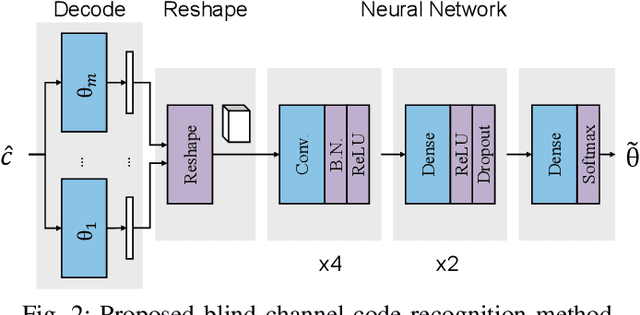
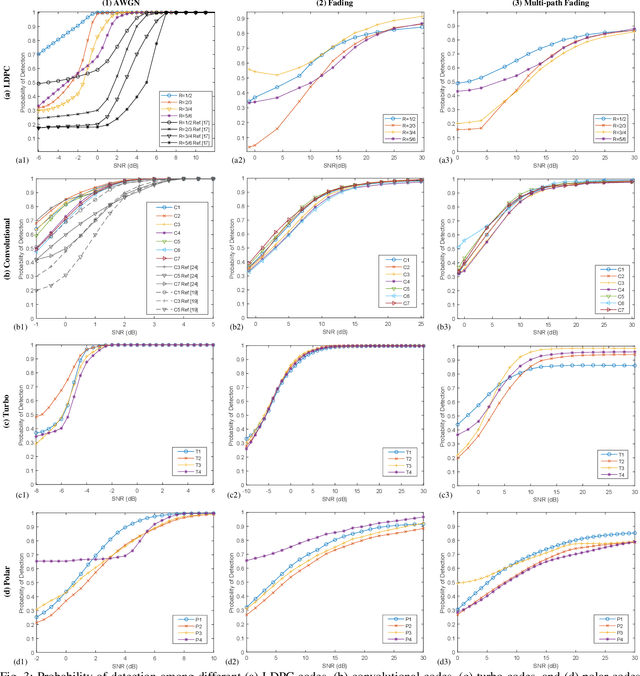
We consider the problem of recovering channel code parameters over a candidate set by merely analyzing the received encoded signals. We propose a deep learning-based solution that I) is capable of identifying the channel code parameters for any coding scheme (such as LDPC, Convolutional, Turbo, and Polar codes), II) is robust against channel impairments like multi-path fading, III) does not require any previous knowledge or estimation of channel state or signal-to-noise ratio (SNR), and IV) outperforms related works in terms of probability of detecting the correct code parameters.