 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoFHE: Automated Adaption of CNNs for Efficient Evaluation over FHE
Oct 12, 2023

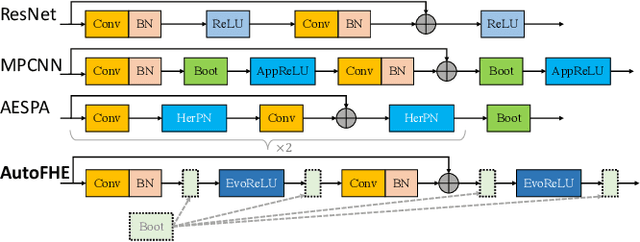
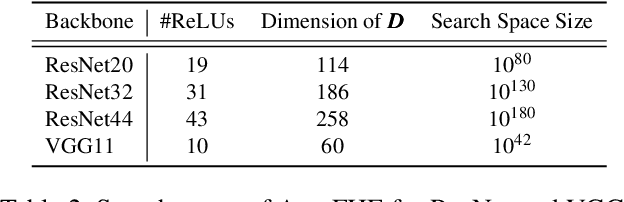
Secure inference of deep convolutional neural networks (CNNs) under RNS-CKKS involves polynomial approximation of unsupported non-linear activation functions. However, existing approaches have three main limitations: 1) Inflexibility: The polynomial approximation and associated homomorphic evaluation architecture are customized manually for each CNN architecture and do not generalize to other networks. 2) Suboptimal Approximation: Each activation function is approximated instead of the function represented by the CNN. 3) Restricted Design: Either high-degree or low-degree polynomial approximations are used. The former retains high accuracy but slows down inference due to bootstrapping operations, while the latter accelerates ciphertext inference but compromises accuracy. To address these limitations, we present AutoFHE, which automatically adapts standard CNNs for secure inference under RNS-CKKS. The key idea is to adopt layerwise mixed-degree polynomial activation functions, which are optimized jointly with the homomorphic evaluation architecture in terms of the placement of bootstrapping operations. The problem is modeled within a multi-objective optimization framework to maximize accuracy and minimize the number of bootstrapping operations. AutoFHE can be applied flexibly on any CNN architecture, and it provides diverse solutions that span the trade-off between accuracy and latency. Experimental evaluation over RNS-CKKS encrypted CIFAR datasets shows that AutoFHE accelerates secure inference by $1.32\times$ to $1.8\times$ compared to methods employing high-degree polynomials. It also improves accuracy by up to 2.56% compared to methods using low-degree polynomials. Lastly, AutoFHE accelerates inference and improves accuracy by $103\times$ and 3.46%, respectively, compared to CNNs under TFHE.
Few-shot semantic segmentation via mask aggregation
Feb 15, 2022Few-shot semantic segmentation aims to recognize novel classes with only very few labelled data. This challenging task requires mining of the relevant relationships between the query image and the support images. Previous works have typically regarded it as a pixel-wise classification problem. Therefore, various models have been designed to explore the correlation of pixels between the query image and the support images. However, they focus only on pixel-wise correspondence and ignore the overall correlation of objects. In this paper, we introduce a mask-based classification method for addressing this problem. The mask aggregation network (MANet), which is a simple mask classification model, is proposed to simultaneously generate a fixed number of masks and their probabilities of being targets. Then, the final segmentation result is obtained by aggregating all the masks according to their locations. Experiments on both the PASCAL-5^i and COCO-20^i datasets show that our method performs comparably to the state-of-the-art pixel-based methods. This competitive performance demonstrates the potential of mask classification as an alternative baseline method in few-shot semantic segmentation. Our source code will be made available at https://github.com/TinyAway/MANet.
Does Unsupervised Architecture Representation Learning Help Neural Architecture Search?
Jun 12, 2020
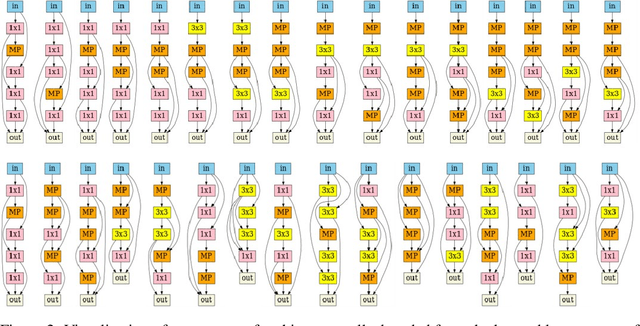
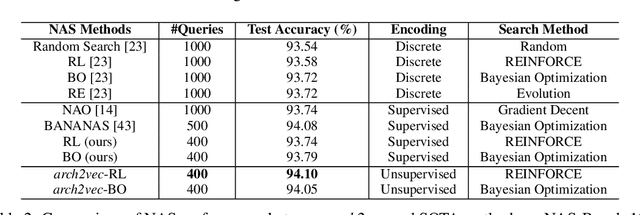
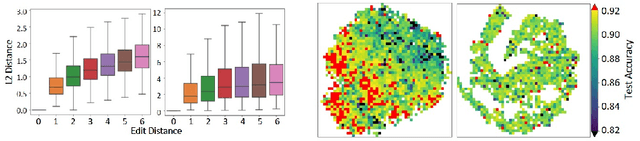
Existing Neural Architecture Search (NAS) methods either encode neural architectures using discrete encodings that do not scale well, or adopt supervised learning-based methods to jointly learn architecture representations and optimize architecture search on such representations which incurs search bias. Despite the widespread use, architecture representations learned in NAS are still poorly understood. We observe that the structural properties of neural architectures are hard to preserve in the latent space if architecture representation learning and search are coupled, resulting in less effective search performance. In this work, we find empirically that pre-training architecture representations using only neural architectures without their accuracies as labels considerably improve the downstream architecture search efficiency. To explain these observations, we visualize how unsupervised architecture representation learning better encourages neural architectures with similar connections and operators to cluster together. This helps to map neural architectures with similar performance to the same regions in the latent space and makes the transition of architectures in the latent space relatively smooth, which considerably benefits diverse downstream search strategies.
Detecting Tiny Moving Vehicles in Satellite Videos
Jul 05, 2018
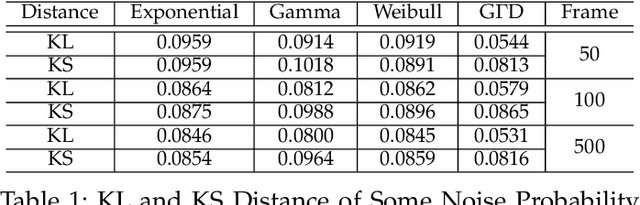


In recent years, the satellite videos have been captured by a moving satellite platform. In contrast to consumer, movie, and common surveillance videos, satellite video can record the snapshot of the city-scale scene. In a broad field-of-view of satellite videos, each moving target would be very tiny and usually composed of several pixels in frames. Even worse, the noise signals also existed in the video frames, since the background of the video frame has the subpixel-level and uneven moving thanks to the motion of satellites. We argue that this is a new type of computer vision task since previous technologies are unable to detect such tiny vehicles efficiently. This paper proposes a novel framework that can identify the small moving vehicles in satellite videos. In particular, we offer a novel detecting algorithm based on the local noise modeling. We differentiate the potential vehicle targets from noise patterns by an exponential probability distribution. Subsequently, a multi-morphological-cue based discrimination strategy is designed to distinguish correct vehicle targets from a few existing noises further. Another significant contribution is to introduce a series of evaluation protocols to measure the performance of tiny moving vehicle detection systematically. We annotate a satellite video manually and use it to test our algorithms under different evaluation criterion. The proposed algorithm is also compared with the state-of-the-art baselines, and demonstrates the advantages of our framework over the benchmarks.