 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Utterance to Vividity: Training Expressive Subtitle Translation LLM via Adaptive Local Preference Optimization
Feb 01, 2026The rapid development of Large Language Models (LLMs) has significantly enhanced the general capabilities of machine translation. However, as application scenarios become more complex, the limitations of LLMs in vertical domain translations are gradually becoming apparent. In this study, we focus on how to construct translation LLMs that meet the needs of domain customization. We take visual media subtitle translation as our topic and explore how to train expressive and vivid translation LLMs. We investigated the situations of subtitle translation and other domains of literal and liberal translation, verifying the reliability of LLM as reward model and evaluator for translation. Additionally, to train an expressive translation LLM, we constructed and released a multidirectional subtitle parallel corpus dataset and proposed the Adaptive Local Preference Optimization (ALPO) method to address fine-grained preference alignment. Experimental results demonstrate that ALPO achieves outstanding performance in multidimensional evaluation of translation quality.
Hermes the Polyglot: A Unified Framework to Enhance Expressiveness for Multimodal Interlingual Subtitling
Jan 31, 2026Interlingual subtitling, which translates subtitles of visual media into a target language, is essential for entertainment localization but has not yet been explored in machine translation. Although Large Language Models (LLMs) have significantly advanced the general capabilities of machine translation, the distinctive characteristics of subtitle texts pose persistent challenges in interlingual subtitling, particularly regarding semantic coherence, pronoun and terminology translation, and translation expressiveness. To address these issues, we present Hermes, an LLM-based automated subtitling framework. Hermes integrates three modules: Speaker Diarization, Terminology Identification, and Expressiveness Enhancement, which effectively tackle the above challenges. Experiments demonstrate that Hermes achieves state-of-the-art diarization performance and generates expressive, contextually coherent translations, thereby advancing research in interlingual subtitling.
Fine-grained Video Dubbing Duration Alignment with Segment Supervised Preference Optimization
Aug 12, 2025Video dubbing aims to translate original speech in visual media programs from the source language to the target language, relying on neural machine translation and text-to-speech technologies. Due to varying information densities across languages, target speech often mismatches the source speech duration, causing audio-video synchronization issues that significantly impact viewer experience. In this study, we approach duration alignment in LLM-based video dubbing machine translation as a preference optimization problem. We propose the Segment Supervised Preference Optimization (SSPO) method, which employs a segment-wise sampling strategy and fine-grained loss to mitigate duration mismatches between source and target lines. Experimental results demonstrate that SSPO achieves superior performance in duration alignment tasks.
* This paper is accepted by ACL2025 (Main)
Variational Optimization for Quantum Problems using Deep Generative Networks
Apr 28, 2024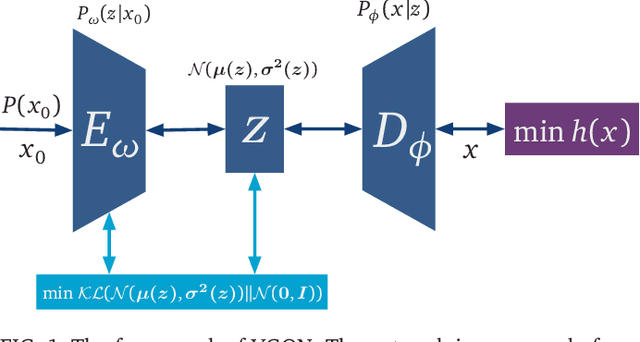
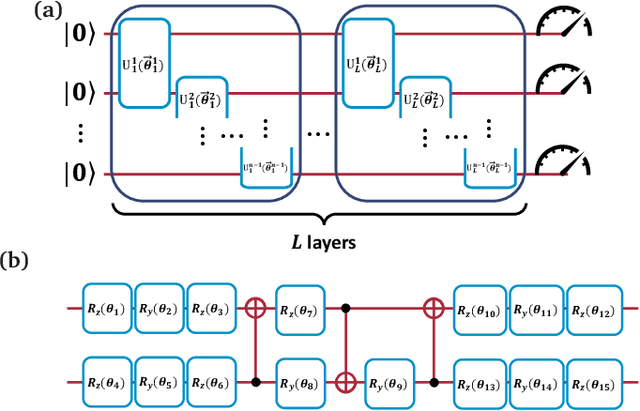
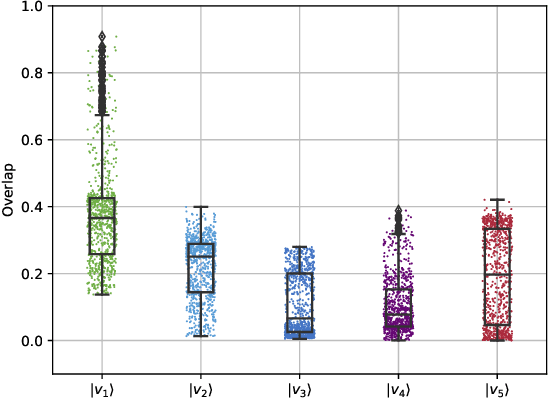
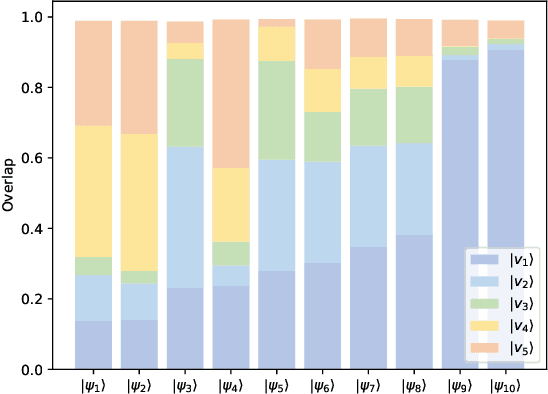
Optimization is one of the keystones of modern science and engineering. Its applications in quantum technology and machine learning helped nurture variational quantum algorithms and generative AI respectively. We propose a general approach to design variational optimization algorithms based on generative models: the Variational Generative Optimization Network (VGON). To demonstrate its broad applicability, we apply VGON to three quantum tasks: finding the best state in an entanglement-detection protocol, finding the ground state of a 1D quantum spin model with variational quantum circuits, and generating degenerate ground states of many-body quantum Hamiltonians. For the first task, VGON greatly reduces the optimization time compared to stochastic gradient descent while generating nearly optimal quantum states. For the second task, VGON alleviates the barren plateau problem in variational quantum circuits. For the final task, VGON can identify the degenerate ground state spaces after a single stage of training and generate a variety of states therein.
ReCLIP: Refine Contrastive Language Image Pre-Training with Source Free Domain Adaptation
Aug 04, 2023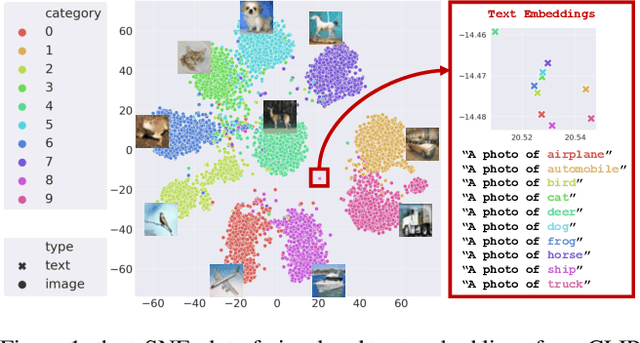
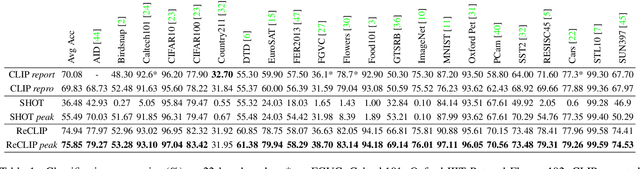
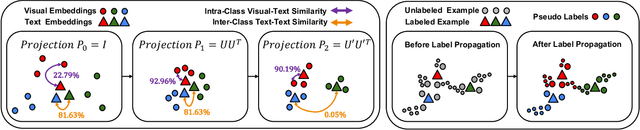
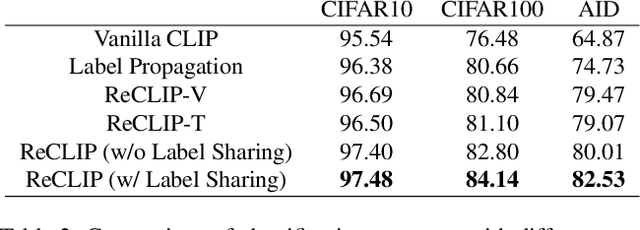
Large-scale Pre-Training Vision-Language Model such as CLIP has demonstrated outstanding performance in zero-shot classification, e.g. achieving 76.3% top-1 accuracy on ImageNet without seeing any example, which leads to potential benefits to many tasks that have no labeled data. However, while applying CLIP to a downstream target domain, the presence of visual and text domain gaps and cross-modality misalignment can greatly impact the model performance. To address such challenges, we propose ReCLIP, the first source-free domain adaptation method for vision-language models, which does not require any source data or target labeled data. ReCLIP first learns a projection space to mitigate the misaligned visual-text embeddings and learns pseudo labels, and then deploys cross-modality self-training with the pseudo labels, to update visual and text encoders, refine labels and reduce domain gaps and misalignments iteratively. With extensive experiments, we demonstrate ReCLIP reduces the average error rate of CLIP from 30.17% to 25.06% on 22 image classification benchmarks.
Youku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks
Jun 07, 2023To promote the development of Vision-Language Pre-training (VLP) and multimodal Large Language Model (LLM) in the Chinese community, we firstly release the largest public Chinese high-quality video-language dataset named Youku-mPLUG, which is collected from Youku, a well-known Chinese video-sharing website, with strict criteria of safety, diversity, and quality. Youku-mPLUG contains 10 million Chinese video-text pairs filtered from 400 million raw videos across a wide range of 45 diverse categories for large-scale pre-training. In addition, to facilitate a comprehensive evaluation of video-language models, we carefully build the largest human-annotated Chinese benchmarks covering three popular video-language tasks of cross-modal retrieval, video captioning, and video category classification. Youku-mPLUG can enable researchers to conduct more in-depth multimodal research and develop better applications in the future. Furthermore, we release popular video-language pre-training models, ALPRO and mPLUG-2, and our proposed modularized decoder-only model mPLUG-video pre-trained on Youku-mPLUG. Experiments show that models pre-trained on Youku-mPLUG gain up to 23.1% improvement in video category classification. Besides, mPLUG-video achieves a new state-of-the-art result on these benchmarks with 80.5% top-1 accuracy in video category classification and 68.9 CIDEr score in video captioning, respectively. Finally, we scale up mPLUG-video based on the frozen Bloomz with only 1.7% trainable parameters as Chinese multimodal LLM, and demonstrate impressive instruction and video understanding ability. The zero-shot instruction understanding experiment indicates that pretraining with Youku-mPLUG can enhance the ability to comprehend overall and detailed visual semantics, recognize scene text, and leverage open-domain knowledge.
Deep Learning in the Era of Edge Computing: Challenges and Opportunities
Oct 17, 2020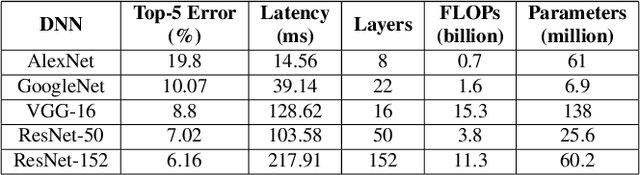

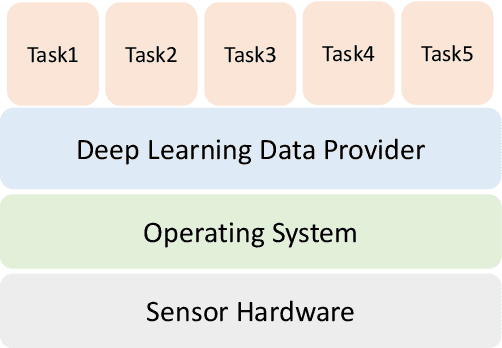
The era of edge computing has arrived. Although the Internet is the backbone of edge computing, its true value lies at the intersection of gathering data from sensors and extracting meaningful information from the sensor data. We envision that in the near future, majority of edge devices will be equipped with machine intelligence powered by deep learning. However, deep learning-based approaches require a large volume of high-quality data to train and are very expensive in terms of computation, memory, and power consumption. In this chapter, we describe eight research challenges and promising opportunities at the intersection of computer systems, networking, and machine learning. Solving those challenges will enable resource-limited edge devices to leverage the amazing capability of deep learning. We hope this chapter could inspire new research that will eventually lead to the realization of the vision of intelligent edge.
Does Unsupervised Architecture Representation Learning Help Neural Architecture Search?
Jun 12, 2020
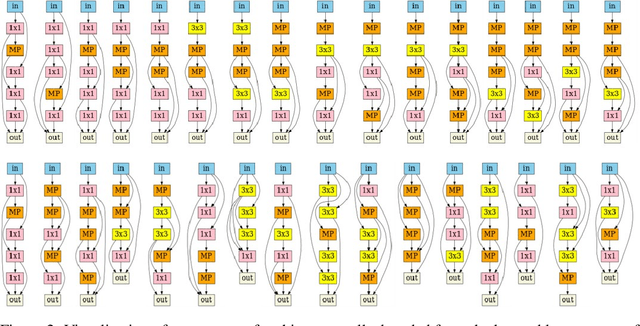
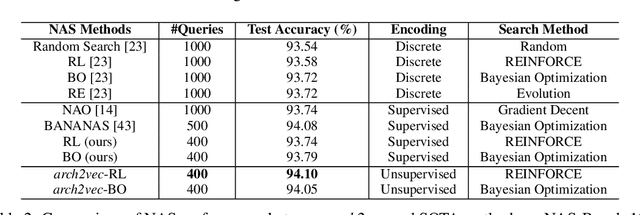
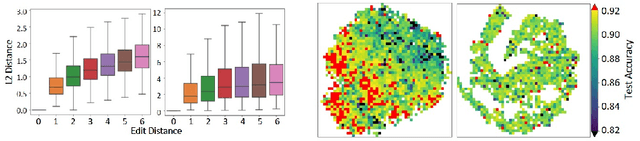
Existing Neural Architecture Search (NAS) methods either encode neural architectures using discrete encodings that do not scale well, or adopt supervised learning-based methods to jointly learn architecture representations and optimize architecture search on such representations which incurs search bias. Despite the widespread use, architecture representations learned in NAS are still poorly understood. We observe that the structural properties of neural architectures are hard to preserve in the latent space if architecture representation learning and search are coupled, resulting in less effective search performance. In this work, we find empirically that pre-training architecture representations using only neural architectures without their accuracies as labels considerably improve the downstream architecture search efficiency. To explain these observations, we visualize how unsupervised architecture representation learning better encourages neural architectures with similar connections and operators to cluster together. This helps to map neural architectures with similar performance to the same regions in the latent space and makes the transition of architectures in the latent space relatively smooth, which considerably benefits diverse downstream search strategies.
HM-NAS: Efficient Neural Architecture Search via Hierarchical Masking
Sep 07, 2019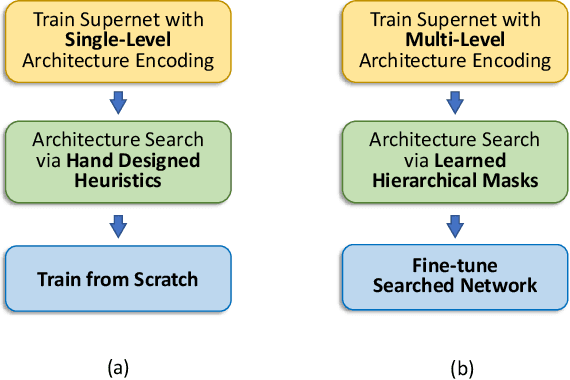
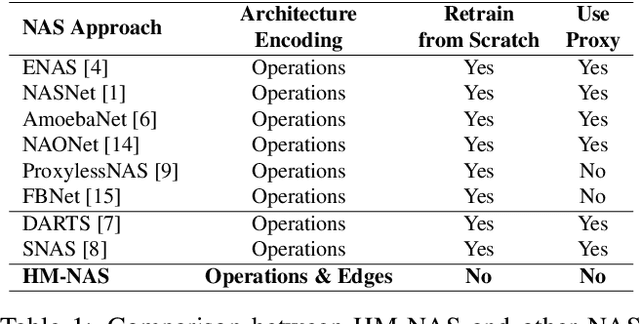
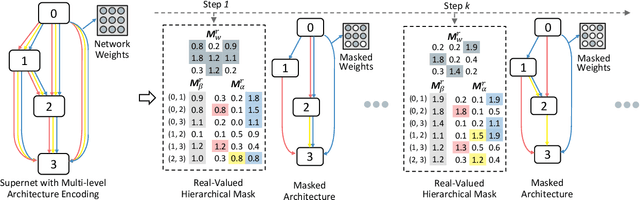
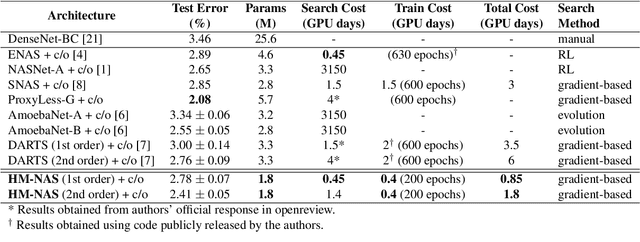
The use of automatic methods, often referred to as Neural Architecture Search (NAS), in designing neural network architectures has recently drawn considerable attention. In this work, we present an efficient NAS approach, named HM- NAS, that generalizes existing weight sharing based NAS approaches. Existing weight sharing based NAS approaches still adopt hand-designed heuristics to generate architecture candidates. As a consequence, the space of architecture candidates is constrained in a subset of all possible architectures, making the architecture search results sub-optimal. HM-NAS addresses this limitation via two innovations. First, HM-NAS incorporates a multi-level architecture encoding scheme to enable searching for more flexible network architectures. Second, it discards the hand-designed heuristics and incorporates a hierarchical masking scheme that automatically learns and determines the optimal architecture. Compared to state-of-the-art weight sharing based approaches, HM-NAS is able to achieve better architecture search performance and competitive model evaluation accuracy. Without the constraint imposed by the hand-designed heuristics, our searched networks contain more flexible and meaningful architectures that existing weight sharing based NAS approaches are not able to discover.
NestDNN: Resource-Aware Multi-Tenant On-Device Deep Learning for Continuous Mobile Vision
Oct 23, 2018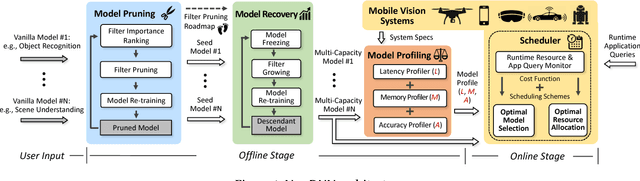

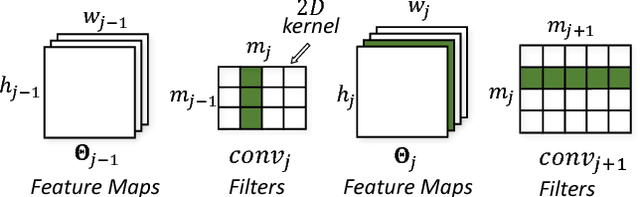
Mobile vision systems such as smartphones, drones, and augmented-reality headsets are revolutionizing our lives. These systems usually run multiple applications concurrently and their available resources at runtime are dynamic due to events such as starting new applications, closing existing applications, and application priority changes. In this paper, we present NestDNN, a framework that takes the dynamics of runtime resources into account to enable resource-aware multi-tenant on-device deep learning for mobile vision systems. NestDNN enables each deep learning model to offer flexible resource-accuracy trade-offs. At runtime, it dynamically selects the optimal resource-accuracy trade-off for each deep learning model to fit the model's resource demand to the system's available runtime resources. In doing so, NestDNN efficiently utilizes the limited resources in mobile vision systems to jointly maximize the performance of all the concurrently running applications. Our experiments show that compared to the resource-agnostic status quo approach, NestDNN achieves as much as 4.2% increase in inference accuracy, 2.0x increase in video frame processing rate and 1.7x reduction on energy consumption.
* 12 pages