 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgrid BoostCNN: Efficient Boosting of Convolutional Networks via Gradient-Guided Feature Selection
Jul 30, 2025



Convolutional Neural Networks (CNNs) have achieved remarkable success across a wide range of machine learning tasks by leveraging hierarchical feature learning through deep architectures. However, the large number of layers and millions of parameters often make CNNs computationally expensive to train, requiring extensive time and manual tuning to discover optimal architectures. In this paper, we introduce a novel framework for boosting CNN performance that integrates dynamic feature selection with the principles of BoostCNN. Our approach incorporates two key strategies: subgrid selection and importance sampling, to guide training toward informative regions of the feature space. We further develop a family of algorithms that embed boosting weights directly into the network training process using a least squares loss formulation. This integration not only alleviates the burden of manual architecture design but also enhances accuracy and efficiency. Experimental results across several fine-grained classification benchmarks demonstrate that our boosted CNN variants consistently outperform conventional CNNs in both predictive performance and training speed.
SLATE: A Sequence Labeling Approach for Task Extraction from Free-form Inked Content
Nov 17, 2022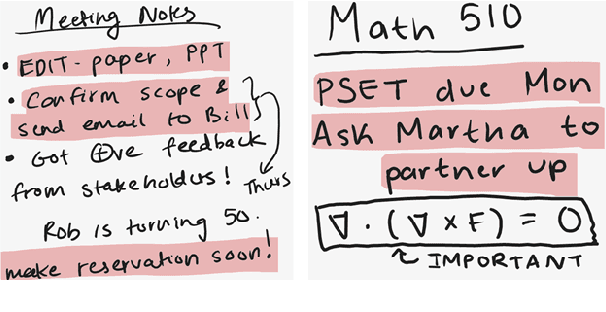
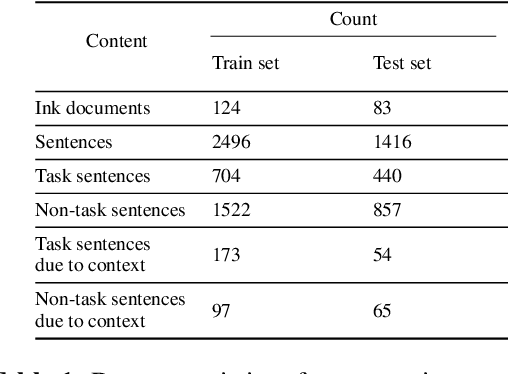
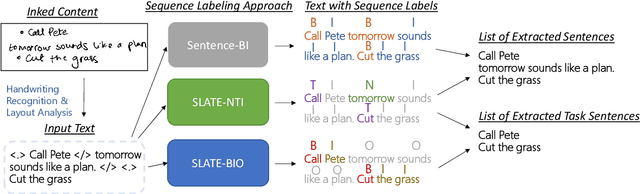
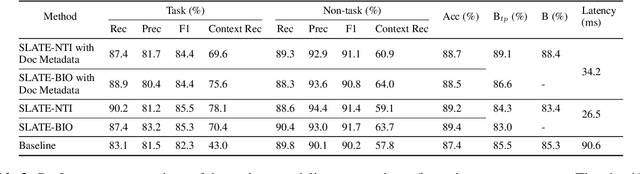
We present SLATE, a sequence labeling approach for extracting tasks from free-form content such as digitally handwritten (or "inked") notes on a virtual whiteboard. Our approach allows us to create a single, low-latency model to simultaneously perform sentence segmentation and classification of these sentences into task/non-task sentences. SLATE greatly outperforms a baseline two-model (sentence segmentation followed by classification model) approach, achieving a task F1 score of 84.4%, a sentence segmentation (boundary similarity) score of 88.4% and three times lower latency compared to the baseline. Furthermore, we provide insights into tackling challenges of performing NLP on the inking domain. We release both our code and dataset for this novel task.
Topic Analysis for Text with Side Data
Mar 01, 2022
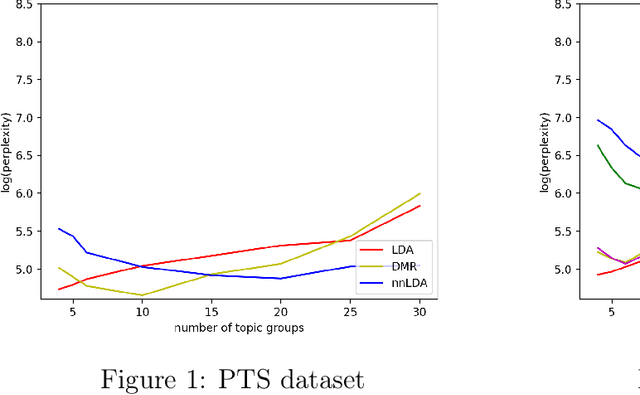

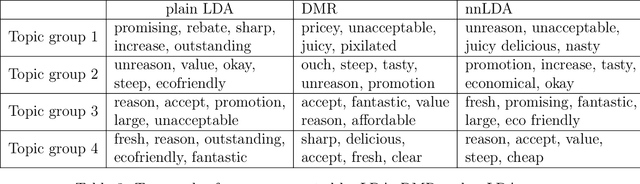
Although latent factor models (e.g., matrix factorization) obtain good performance in predictions, they suffer from several problems including cold-start, non-transparency, and suboptimal recommendations. In this paper, we employ text with side data to tackle these limitations. We introduce a hybrid generative probabilistic model that combines a neural network with a latent topic model, which is a four-level hierarchical Bayesian model. In the model, each document is modeled as a finite mixture over an underlying set of topics and each topic is modeled as an infinite mixture over an underlying set of topic probabilities. Furthermore, each topic probability is modeled as a finite mixture over side data. In the context of text, the neural network provides an overview distribution about side data for the corresponding text, which is the prior distribution in LDA to help perform topic grouping. The approach is evaluated on several different datasets, where the model is shown to outperform standard LDA and Dirichlet-multinomial regression (DMR) in terms of topic grouping, model perplexity, classification and comment generation.
Tricks and Plugins to GBM on Images and Sequences
Mar 01, 2022
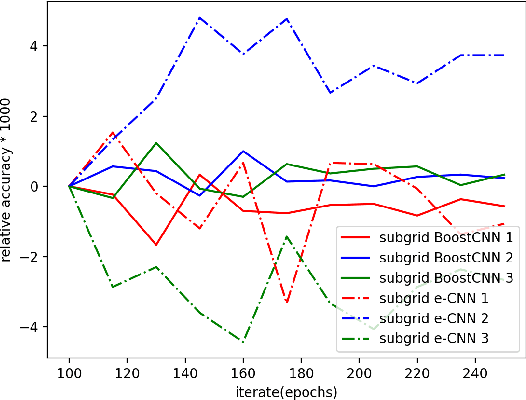

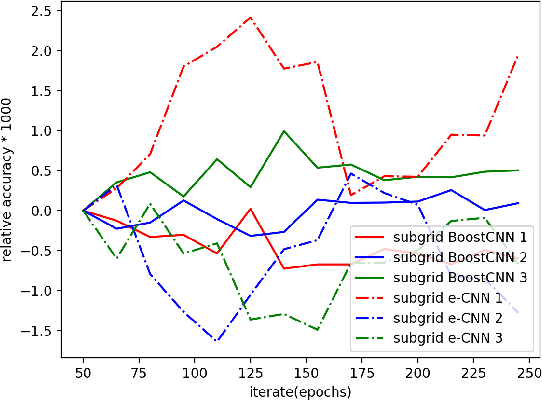
Convolutional neural networks (CNNs) and transformers, which are composed of multiple processing layers and blocks to learn the representations of data with multiple abstract levels, are the most successful machine learning models in recent years. However, millions of parameters and many blocks make them difficult to be trained, and sometimes several days or weeks are required to find an ideal architecture or tune the parameters. Within this paper, we propose a new algorithm for boosting Deep Convolutional Neural Networks (BoostCNN) to combine the merits of dynamic feature selection and BoostCNN, and another new family of algorithms combining boosting and transformers. To learn these new models, we introduce subgrid selection and importance sampling strategies and propose a set of algorithms to incorporate boosting weights into a deep learning architecture based on a least squares objective function. These algorithms not only reduce the required manual effort for finding an appropriate network architecture but also result in superior performance and lower running time. Experiments show that the proposed methods outperform benchmarks on several fine-grained classification tasks.
Only Train Once: A One-Shot Neural Network Training And Pruning Framework
Jul 15, 2021

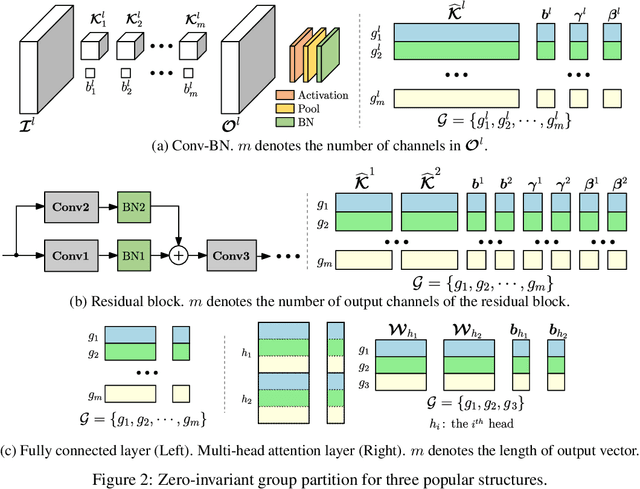
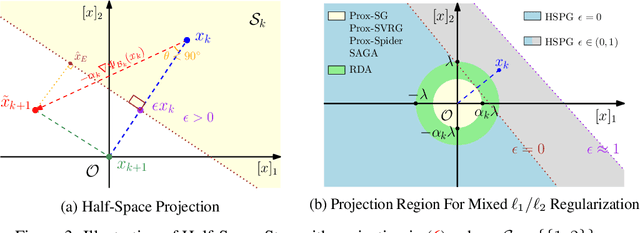
Structured pruning is a commonly used technique in deploying deep neural networks (DNNs) onto resource-constrained devices. However, the existing pruning methods are usually heuristic, task-specified, and require an extra fine-tuning procedure. To overcome these limitations, we propose a framework that compresses DNNs into slimmer architectures with competitive performances and significant FLOPs reductions by Only-Train-Once (OTO). OTO contains two keys: (i) we partition the parameters of DNNs into zero-invariant groups, enabling us to prune zero groups without affecting the output; and (ii) to promote zero groups, we then formulate a structured-sparsity optimization problem and propose a novel optimization algorithm, Half-Space Stochastic Projected Gradient (HSPG), to solve it, which outperforms the standard proximal methods on group sparsity exploration and maintains comparable convergence. To demonstrate the effectiveness of OTO, we train and compress full models simultaneously from scratch without fine-tuning for inference speedup and parameter reduction, and achieve state-of-the-art results on VGG16 for CIFAR10, ResNet50 for CIFAR10/ImageNet and Bert for SQuAD.
Neural Network Compression Via Sparse Optimization
Nov 11, 2020
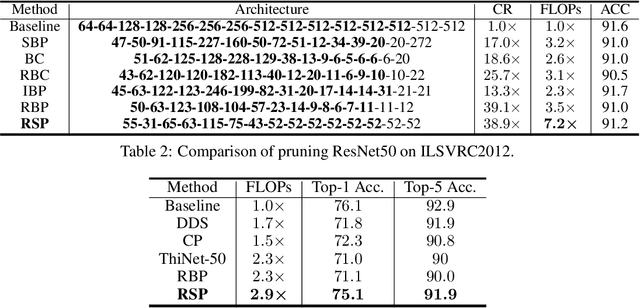
The compression of deep neural networks (DNNs) to reduce inference cost becomes increasingly important to meet realistic deployment requirements of various applications. There have been a significant amount of work regarding network compression, while most of them are heuristic rule-based or typically not friendly to be incorporated into varying scenarios. On the other hand, sparse optimization yielding sparse solutions naturally fits the compression requirement, but due to the limited study of sparse optimization in stochastic learning, its extension and application onto model compression is rarely well explored. In this work, we propose a model compression framework based on the recent progress on sparse stochastic optimization. Compared to existing model compression techniques, our method is effective and requires fewer extra engineering efforts to incorporate with varying applications, and has been numerically demonstrated on benchmark compression tasks. Particularly, we achieve up to 7.2 and 2.9 times FLOPs reduction with the same level of evaluation accuracy on VGG16 for CIFAR10 and ResNet50 for ImageNet compared to the baseline heavy models, respectively.
Deep Learning in the Era of Edge Computing: Challenges and Opportunities
Oct 17, 2020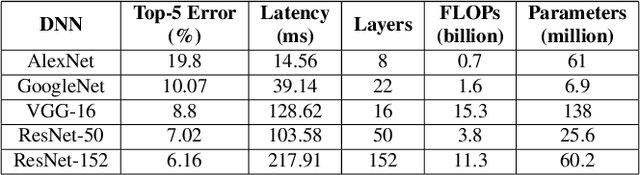

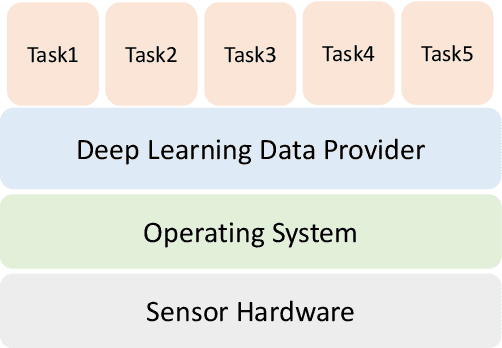
The era of edge computing has arrived. Although the Internet is the backbone of edge computing, its true value lies at the intersection of gathering data from sensors and extracting meaningful information from the sensor data. We envision that in the near future, majority of edge devices will be equipped with machine intelligence powered by deep learning. However, deep learning-based approaches require a large volume of high-quality data to train and are very expensive in terms of computation, memory, and power consumption. In this chapter, we describe eight research challenges and promising opportunities at the intersection of computer systems, networking, and machine learning. Solving those challenges will enable resource-limited edge devices to leverage the amazing capability of deep learning. We hope this chapter could inspire new research that will eventually lead to the realization of the vision of intelligent edge.
HM-NAS: Efficient Neural Architecture Search via Hierarchical Masking
Sep 07, 2019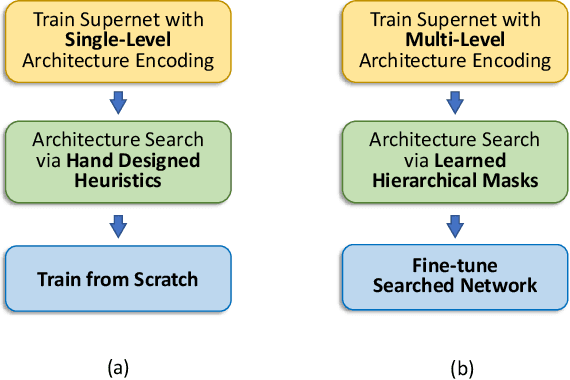
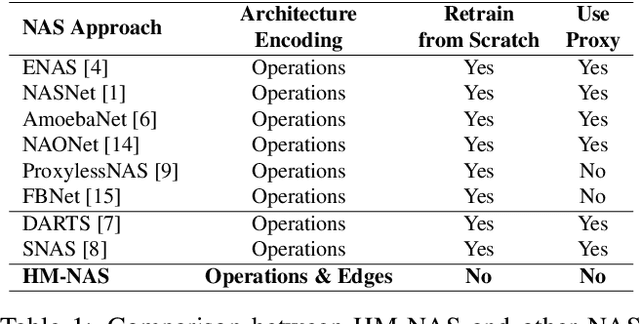
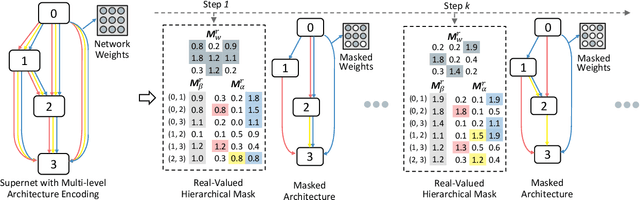
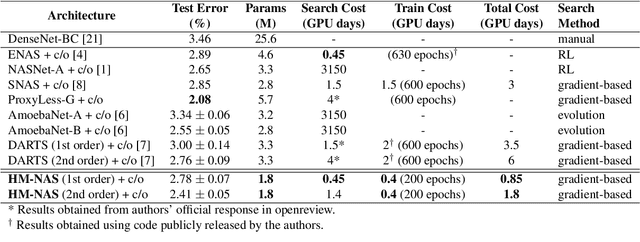
The use of automatic methods, often referred to as Neural Architecture Search (NAS), in designing neural network architectures has recently drawn considerable attention. In this work, we present an efficient NAS approach, named HM- NAS, that generalizes existing weight sharing based NAS approaches. Existing weight sharing based NAS approaches still adopt hand-designed heuristics to generate architecture candidates. As a consequence, the space of architecture candidates is constrained in a subset of all possible architectures, making the architecture search results sub-optimal. HM-NAS addresses this limitation via two innovations. First, HM-NAS incorporates a multi-level architecture encoding scheme to enable searching for more flexible network architectures. Second, it discards the hand-designed heuristics and incorporates a hierarchical masking scheme that automatically learns and determines the optimal architecture. Compared to state-of-the-art weight sharing based approaches, HM-NAS is able to achieve better architecture search performance and competitive model evaluation accuracy. Without the constraint imposed by the hand-designed heuristics, our searched networks contain more flexible and meaningful architectures that existing weight sharing based NAS approaches are not able to discover.
Convergence Analyses of Online ADAM Algorithm in Convex Setting and Two-Layer ReLU Neural Network
May 22, 2019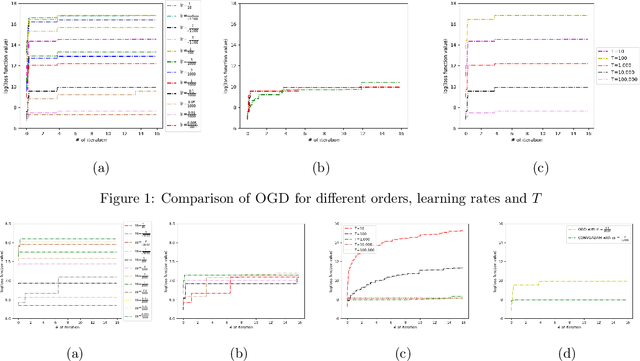

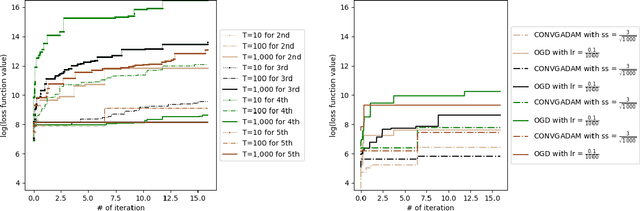
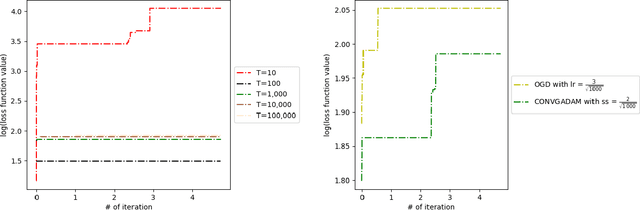
Nowadays, online learning is an appealing learning paradigm, which is of great interest in practice due to the recent emergence of large scale applications such as online advertising placement and online web ranking. Standard online learning assumes a finite number of samples while in practice data is streamed infinitely. In such a setting gradient descent with a diminishing learning rate does not work. We first introduce regret with rolling window, a new performance metric for online streaming learning, which measures the performance of an algorithm on every fixed number of contiguous samples. At the same time, we propose a family of algorithms based on gradient descent with a constant or adaptive learning rate and provide very technical analyses establishing regret bound properties of the algorithms. We cover the convex setting showing the regret of the order of the square root of the size of the window in the constant and dynamic learning rate scenarios. Our proof is applicable also to the standard online setting where we provide the first analysis of the same regret order (the previous proofs have flaws). We also study a two layer neural network setting with ReLU activation. In this case we establish that if initial weights are close to a stationary point, the same square root regret bound is attainable. We conduct computational experiments demonstrating a superior performance of the proposed algorithms.
NestDNN: Resource-Aware Multi-Tenant On-Device Deep Learning for Continuous Mobile Vision
Oct 23, 2018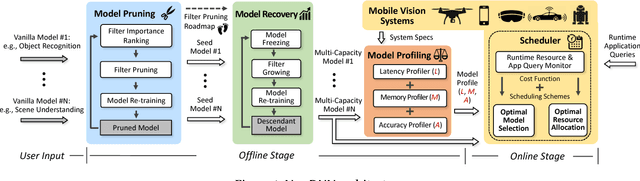

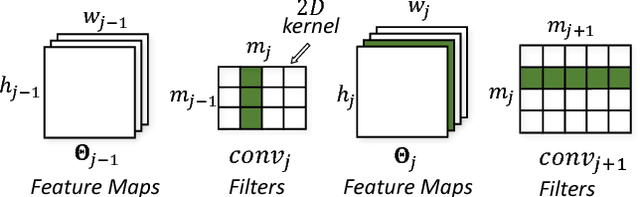
Mobile vision systems such as smartphones, drones, and augmented-reality headsets are revolutionizing our lives. These systems usually run multiple applications concurrently and their available resources at runtime are dynamic due to events such as starting new applications, closing existing applications, and application priority changes. In this paper, we present NestDNN, a framework that takes the dynamics of runtime resources into account to enable resource-aware multi-tenant on-device deep learning for mobile vision systems. NestDNN enables each deep learning model to offer flexible resource-accuracy trade-offs. At runtime, it dynamically selects the optimal resource-accuracy trade-off for each deep learning model to fit the model's resource demand to the system's available runtime resources. In doing so, NestDNN efficiently utilizes the limited resources in mobile vision systems to jointly maximize the performance of all the concurrently running applications. Our experiments show that compared to the resource-agnostic status quo approach, NestDNN achieves as much as 4.2% increase in inference accuracy, 2.0x increase in video frame processing rate and 1.7x reduction on energy consumption.
* 12 pages