 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Reformulation of Robust Optimization via Memory-Augmented Large Language Models
May 12, 2026Robust optimization (RO) provides a principled framework for decision-making under uncertainty, but its practical use is often limited by the need to manually reformulate uncertain optimization models into tractable deterministic counterparts. Recent large language models (LLMs) have been shown promising for automating optimization formulation, yet RO reformulation remains challenging because it requires precise multi-step reasoning and mathematically consistent transformations. To facilitate systematic evaluation of LLM-based reformulation, for which no dedicated benchmark currently exists, we develop AutoRO-Bench, a benchmark featuring an automated data generation pipeline for the core RO reformulation task and a curated dataset for the RO application task. To address the reformulation challenge, we propose Automated Reformulation with Experience Memory (AutoREM), a tuning-free memory-augmented framework that autonomously builds a structured textual experience memory by reflecting on past failed trajectories through a tailored offline adaptation procedure. AutoREM requires neither domain-specific expert knowledge nor parameter updates, and the resulting memory readily transfers across different base LLMs. Experimental results show that AutoREM consistently improves the accuracy and efficiency of RO reformulation across in-distribution datasets, out-of-distribution datasets, and diverse base LLMs.
Solving Sparse \& High-Dimensional-Output Regression via Compression
Oct 21, 2024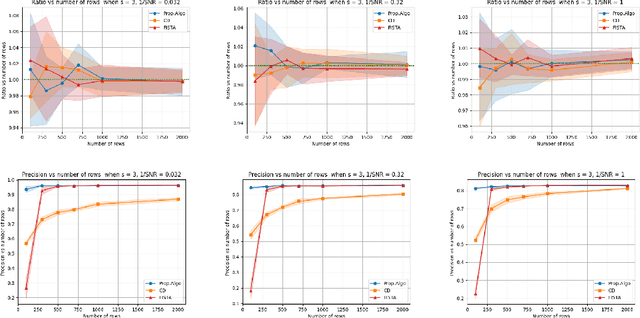

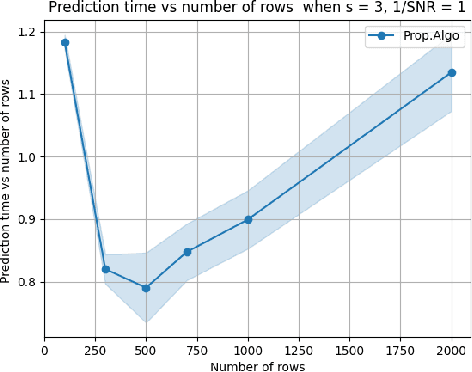

Multi-Output Regression (MOR) has been widely used in scientific data analysis for decision-making. Unlike traditional regression models, MOR aims to simultaneously predict multiple real-valued outputs given an input. However, the increasing dimensionality of the outputs poses significant challenges regarding interpretability and computational scalability for modern MOR applications. As a first step to address these challenges, this paper proposes a Sparse \& High-dimensional-Output REgression (SHORE) model by incorporating additional sparsity requirements to resolve the output interpretability, and then designs a computationally efficient two-stage optimization framework capable of solving SHORE with provable accuracy via compression on outputs. Theoretically, we show that the proposed framework is computationally scalable while maintaining the same order of training loss and prediction loss before-and-after compression under arbitrary or relatively weak sample set conditions. Empirically, numerical results further validate the theoretical findings, showcasing the efficiency and accuracy of the proposed framework.
Do algorithms and barriers for sparse principal component analysis extend to other structured settings?
Jul 25, 2023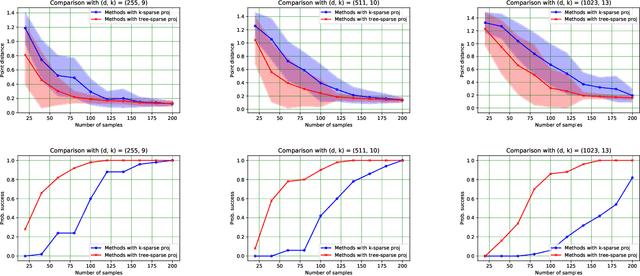
We study a principal component analysis problem under the spiked Wishart model in which the structure in the signal is captured by a class of union-of-subspace models. This general class includes vanilla sparse PCA as well as its variants with graph sparsity. With the goal of studying these problems under a unified statistical and computational lens, we establish fundamental limits that depend on the geometry of the problem instance, and show that a natural projected power method exhibits local convergence to the statistically near-optimal neighborhood of the solution. We complement these results with end-to-end analyses of two important special cases given by path and tree sparsity in a general basis, showing initialization methods and matching evidence of computational hardness. Overall, our results indicate that several of the phenomena observed for vanilla sparse PCA extend in a natural fashion to its structured counterparts.
Only Train Once: A One-Shot Neural Network Training And Pruning Framework
Jul 15, 2021

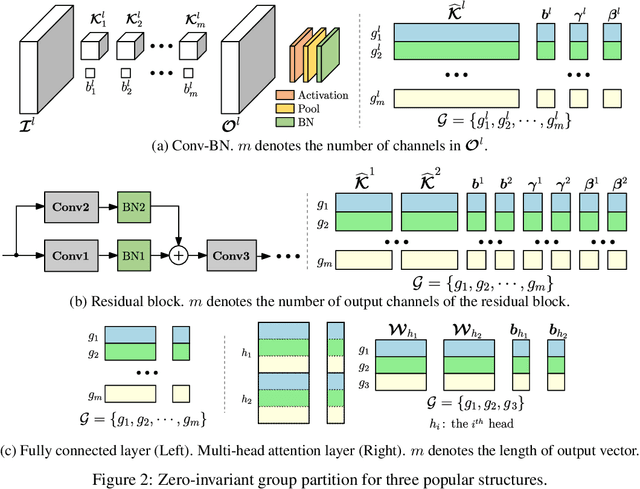
Structured pruning is a commonly used technique in deploying deep neural networks (DNNs) onto resource-constrained devices. However, the existing pruning methods are usually heuristic, task-specified, and require an extra fine-tuning procedure. To overcome these limitations, we propose a framework that compresses DNNs into slimmer architectures with competitive performances and significant FLOPs reductions by Only-Train-Once (OTO). OTO contains two keys: (i) we partition the parameters of DNNs into zero-invariant groups, enabling us to prune zero groups without affecting the output; and (ii) to promote zero groups, we then formulate a structured-sparsity optimization problem and propose a novel optimization algorithm, Half-Space Stochastic Projected Gradient (HSPG), to solve it, which outperforms the standard proximal methods on group sparsity exploration and maintains comparable convergence. To demonstrate the effectiveness of OTO, we train and compress full models simultaneously from scratch without fine-tuning for inference speedup and parameter reduction, and achieve state-of-the-art results on VGG16 for CIFAR10, ResNet50 for CIFAR10/ImageNet and Bert for SQuAD.
Orthant Based Proximal Stochastic Gradient Method for $\ell_1$-Regularized Optimization
Apr 07, 2020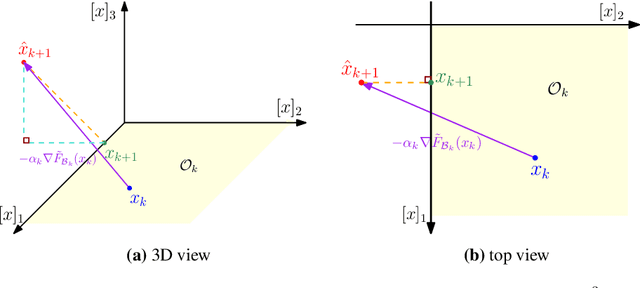

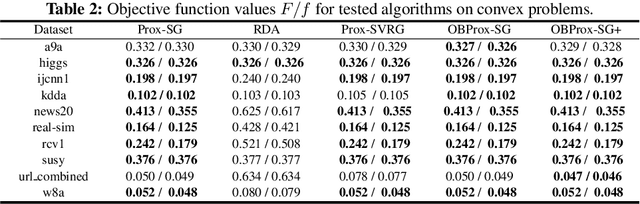
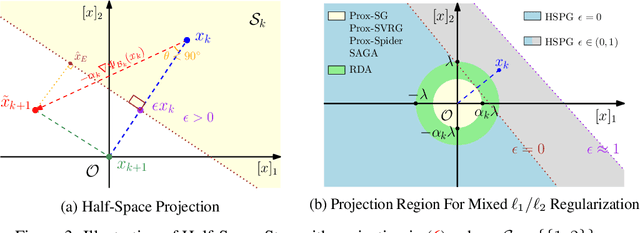
Sparsity-inducing regularization problems are ubiquitous in machine learning applications, ranging from feature selection to model compression. In this paper, we present a novel stochastic method -- Orthant Based Proximal Stochastic Gradient Method (OBProx-SG) -- to solve perhaps the most popular instance, i.e., the l1-regularized problem. The OBProx-SG method contains two steps: (i) a proximal stochastic gradient step to predict a support cover of the solution; and (ii) an orthant step to aggressively enhance the sparsity level via orthant face projection. Compared to the state-of-the-art methods, e.g., Prox-SG, RDA and Prox-SVRG, the OBProx-SG not only converges to the global optimal solutions (in convex scenario) or the stationary points (in non-convex scenario), but also promotes the sparsity of the solutions substantially. Particularly, on a large number of convex problems, OBProx-SG outperforms the existing methods comprehensively in the aspect of sparsity exploration and objective values. Moreover, the experiments on non-convex deep neural networks, e.g., MobileNetV1 and ResNet18, further demonstrate its superiority by achieving the solutions of much higher sparsity without sacrificing generalization accuracy.