 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Recognition with Image-Text Matching-guided Dictionary
May 08, 2023Employing a dictionary can efficiently rectify the deviation between the visual prediction and the ground truth in scene text recognition methods. However, the independence of the dictionary on the visual features may lead to incorrect rectification of accurate visual predictions. In this paper, we propose a new dictionary language model leveraging the Scene Image-Text Matching(SITM) network, which avoids the drawbacks of the explicit dictionary language model: 1) the independence of the visual features; 2) noisy choice in candidates etc. The SITM network accomplishes this by using Image-Text Contrastive (ITC) Learning to match an image with its corresponding text among candidates in the inference stage. ITC is widely used in vision-language learning to pull the positive image-text pair closer in feature space. Inspired by ITC, the SITM network combines the visual features and the text features of all candidates to identify the candidate with the minimum distance in the feature space. Our lexicon method achieves better results(93.8\% accuracy) than the ordinary method results(92.1\% accuracy) on six mainstream benchmarks. Additionally, we integrate our method with ABINet and establish new state-of-the-art results on several benchmarks.
Only Train Once: A One-Shot Neural Network Training And Pruning Framework
Jul 15, 2021

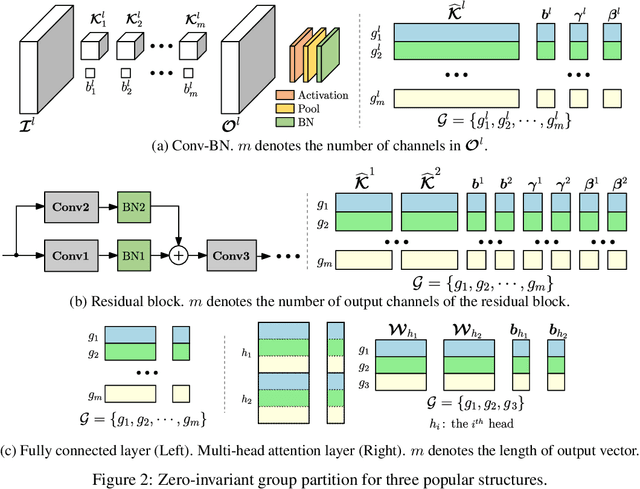
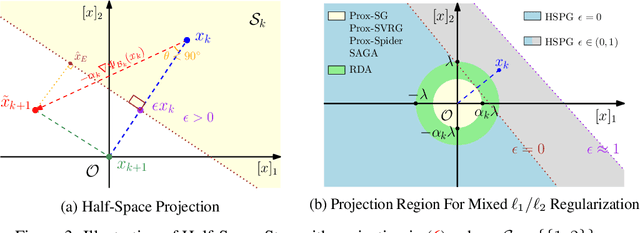
Structured pruning is a commonly used technique in deploying deep neural networks (DNNs) onto resource-constrained devices. However, the existing pruning methods are usually heuristic, task-specified, and require an extra fine-tuning procedure. To overcome these limitations, we propose a framework that compresses DNNs into slimmer architectures with competitive performances and significant FLOPs reductions by Only-Train-Once (OTO). OTO contains two keys: (i) we partition the parameters of DNNs into zero-invariant groups, enabling us to prune zero groups without affecting the output; and (ii) to promote zero groups, we then formulate a structured-sparsity optimization problem and propose a novel optimization algorithm, Half-Space Stochastic Projected Gradient (HSPG), to solve it, which outperforms the standard proximal methods on group sparsity exploration and maintains comparable convergence. To demonstrate the effectiveness of OTO, we train and compress full models simultaneously from scratch without fine-tuning for inference speedup and parameter reduction, and achieve state-of-the-art results on VGG16 for CIFAR10, ResNet50 for CIFAR10/ImageNet and Bert for SQuAD.
Neural Network Compression Via Sparse Optimization
Nov 11, 2020
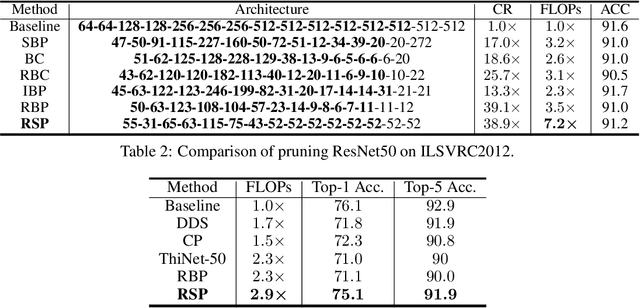
The compression of deep neural networks (DNNs) to reduce inference cost becomes increasingly important to meet realistic deployment requirements of various applications. There have been a significant amount of work regarding network compression, while most of them are heuristic rule-based or typically not friendly to be incorporated into varying scenarios. On the other hand, sparse optimization yielding sparse solutions naturally fits the compression requirement, but due to the limited study of sparse optimization in stochastic learning, its extension and application onto model compression is rarely well explored. In this work, we propose a model compression framework based on the recent progress on sparse stochastic optimization. Compared to existing model compression techniques, our method is effective and requires fewer extra engineering efforts to incorporate with varying applications, and has been numerically demonstrated on benchmark compression tasks. Particularly, we achieve up to 7.2 and 2.9 times FLOPs reduction with the same level of evaluation accuracy on VGG16 for CIFAR10 and ResNet50 for ImageNet compared to the baseline heavy models, respectively.
Orthant Based Proximal Stochastic Gradient Method for $\ell_1$-Regularized Optimization
Apr 07, 2020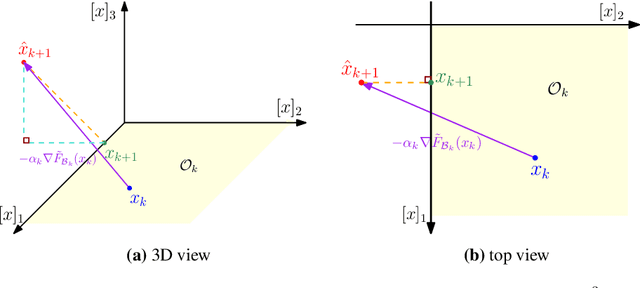

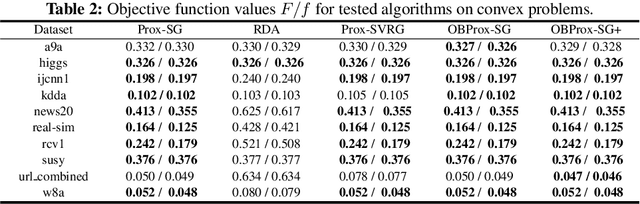
Sparsity-inducing regularization problems are ubiquitous in machine learning applications, ranging from feature selection to model compression. In this paper, we present a novel stochastic method -- Orthant Based Proximal Stochastic Gradient Method (OBProx-SG) -- to solve perhaps the most popular instance, i.e., the l1-regularized problem. The OBProx-SG method contains two steps: (i) a proximal stochastic gradient step to predict a support cover of the solution; and (ii) an orthant step to aggressively enhance the sparsity level via orthant face projection. Compared to the state-of-the-art methods, e.g., Prox-SG, RDA and Prox-SVRG, the OBProx-SG not only converges to the global optimal solutions (in convex scenario) or the stationary points (in non-convex scenario), but also promotes the sparsity of the solutions substantially. Particularly, on a large number of convex problems, OBProx-SG outperforms the existing methods comprehensively in the aspect of sparsity exploration and objective values. Moreover, the experiments on non-convex deep neural networks, e.g., MobileNetV1 and ResNet18, further demonstrate its superiority by achieving the solutions of much higher sparsity without sacrificing generalization accuracy.