 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Flow Network for Visually Grounded Reasoning
May 04, 2026Despite the success of Large-Vision Language Models (LVLMs), general optimization objectives (e.g., standard MLE) fail to constrain visual trajectories, leading to language bias and hallucination. To mitigate this, current methods introduce geometric priors from visual experts as additional supervision. However, we observe that such supervision is typically suboptimal: it is biased toward geometric precision and offers limited reasoning utility. To bridge this gap, we propose Perceptual Flow Network (PFlowNet), which eschews rigid alignment with the expert priors and achieves interpretable yet more effective visual reasoning. Specifically, PFlowNet decouples perception from reasoning to establish a self-conditioned generation process. Based on this, it integrates multi-dimensional rewards with vicinal geometric shaping via variational reinforcement learning, thereby facilitating reasoning-oriented perceptual behaviors while preserving visual reliability. PFlowNet delivers a provable performance guarantee and competitive empirical results, particularly setting new SOTA records on V* Bench (90.6%) and MME-RealWorld-lite (67.0%).
DeepScan: A Training-Free Framework for Visually Grounded Reasoning in Large Vision-Language Models
Mar 04, 2026Humans can robustly localize visual evidence and provide grounded answers even in noisy environments by identifying critical cues and then relating them to the full context in a bottom-up manner. Inspired by this, we propose DeepScan, a training-free framework that combines Hierarchical Scanning, Refocusing, and Evidence-Enhanced Reasoning for visually grounded reasoning in Large Vision-Language Models (LVLMs). Unlike existing methods that pursue one-shot localization of complete evidence, Hierarchical Scanning performs local cue exploration and multi-scale evidence extraction to recover evidence in a bottom-up manner, effectively mitigating the impacts of distractive context. Refocusing then optimizes the localized evidence view through collaboration of LVLMs and visual experts. Finally, Evidence-Enhanced Reasoning aggregates multi-granular views via a hybrid evidence memory and yields accurate and interpretable answers. Experimental results demonstrate that DeepScan significantly boosts LVLMs in diverse visual tasks, especially in fine-grained visual understanding. It achieves 90.6% overall accuracy on V* when integrated with Qwen2.5-VL-7B. Moreover, DeepScan provides consistent improvements for LVLMs across various architectures and model scales without additional adaptation cost.
* 18 pages 17 figures
Why 1 + 1 < 1 in Visual Token Pruning: Beyond Naive Integration via Multi-Objective Balanced Covering
May 15, 2025Existing visual token pruning methods target prompt alignment and visual preservation with static strategies, overlooking the varying relative importance of these objectives across tasks, which leads to inconsistent performance. To address this, we derive the first closed-form error bound for visual token pruning based on the Hausdorff distance, uniformly characterizing the contributions of both objectives. Moreover, leveraging $\epsilon$-covering theory, we reveal an intrinsic trade-off between these objectives and quantify their optimal attainment levels under a fixed budget. To practically handle this trade-off, we propose Multi-Objective Balanced Covering (MoB), which reformulates visual token pruning as a bi-objective covering problem. In this framework, the attainment trade-off reduces to budget allocation via greedy radius trading. MoB offers a provable performance bound and linear scalability with respect to the number of input visual tokens, enabling adaptation to challenging pruning scenarios. Extensive experiments show that MoB preserves 96.4% of performance for LLaVA-1.5-7B using only 11.1% of the original visual tokens and accelerates LLaVA-Next-7B by 1.3-1.5$\times$ with negligible performance loss. Additionally, evaluations on Qwen2-VL and Video-LLaVA confirm that MoB integrates seamlessly into advanced MLLMs and diverse vision-language tasks.
Adaptive White-Box Watermarking with Self-Mutual Check Parameters in Deep Neural Networks
Aug 22, 2023



Artificial Intelligence (AI) has found wide application, but also poses risks due to unintentional or malicious tampering during deployment. Regular checks are therefore necessary to detect and prevent such risks. Fragile watermarking is a technique used to identify tampering in AI models. However, previous methods have faced challenges including risks of omission, additional information transmission, and inability to locate tampering precisely. In this paper, we propose a method for detecting tampered parameters and bits, which can be used to detect, locate, and restore parameters that have been tampered with. We also propose an adaptive embedding method that maximizes information capacity while maintaining model accuracy. Our approach was tested on multiple neural networks subjected to attacks that modified weight parameters, and our results demonstrate that our method achieved great recovery performance when the modification rate was below 20%. Furthermore, for models where watermarking significantly affected accuracy, we utilized an adaptive bit technique to recover more than 15% of the accuracy loss of the model.
Weakly Supervised Scene Text Generation for Low-resource Languages
Jun 27, 2023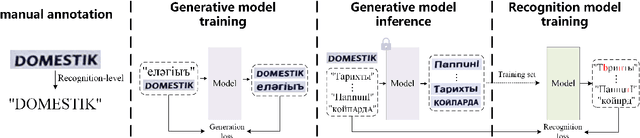
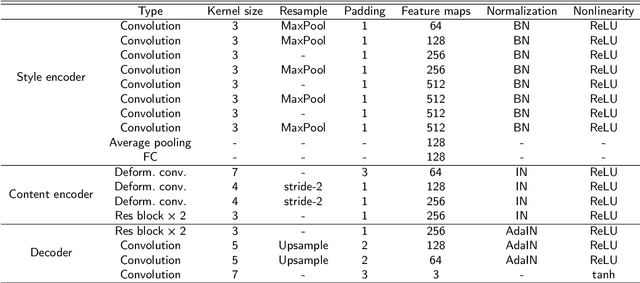
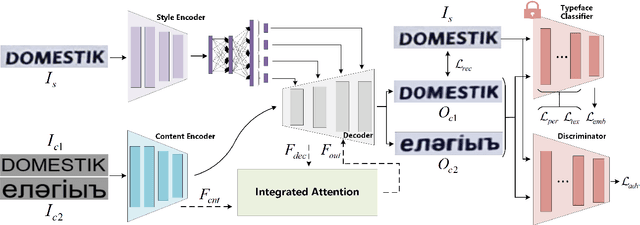
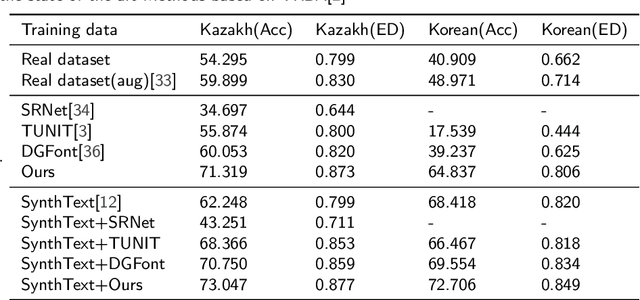
A large number of annotated training images is crucial for training successful scene text recognition models. However, collecting sufficient datasets can be a labor-intensive and costly process, particularly for low-resource languages. To address this challenge, auto-generating text data has shown promise in alleviating the problem. Unfortunately, existing scene text generation methods typically rely on a large amount of paired data, which is difficult to obtain for low-resource languages. In this paper, we propose a novel weakly supervised scene text generation method that leverages a few recognition-level labels as weak supervision. The proposed method is able to generate a large amount of scene text images with diverse backgrounds and font styles through cross-language generation. Our method disentangles the content and style features of scene text images, with the former representing textual information and the latter representing characteristics such as font, alignment, and background. To preserve the complete content structure of generated images, we introduce an integrated attention module. Furthermore, to bridge the style gap in the style of different languages, we incorporate a pre-trained font classifier. We evaluate our method using state-of-the-art scene text recognition models. Experiments demonstrate that our generated scene text significantly improves the scene text recognition accuracy and help achieve higher accuracy when complemented with other generative methods.
Scene Text Recognition with Image-Text Matching-guided Dictionary
May 08, 2023Employing a dictionary can efficiently rectify the deviation between the visual prediction and the ground truth in scene text recognition methods. However, the independence of the dictionary on the visual features may lead to incorrect rectification of accurate visual predictions. In this paper, we propose a new dictionary language model leveraging the Scene Image-Text Matching(SITM) network, which avoids the drawbacks of the explicit dictionary language model: 1) the independence of the visual features; 2) noisy choice in candidates etc. The SITM network accomplishes this by using Image-Text Contrastive (ITC) Learning to match an image with its corresponding text among candidates in the inference stage. ITC is widely used in vision-language learning to pull the positive image-text pair closer in feature space. Inspired by ITC, the SITM network combines the visual features and the text features of all candidates to identify the candidate with the minimum distance in the feature space. Our lexicon method achieves better results(93.8\% accuracy) than the ordinary method results(92.1\% accuracy) on six mainstream benchmarks. Additionally, we integrate our method with ABINet and establish new state-of-the-art results on several benchmarks.
OTS: A One-shot Learning Approach for Text Spotting in Historical Manuscripts
Apr 18, 2023Historical manuscript processing poses challenges like limited annotated training data and novel class emergence. To address this, we propose a novel One-shot learning-based Text Spotting (OTS) approach that accurately and reliably spots novel characters with just one annotated support sample. Drawing inspiration from cognitive research, we introduce a spatial alignment module that finds, focuses on, and learns the most discriminative spatial regions in the query image based on one support image. Especially, since the low-resource spotting task often faces the problem of example imbalance, we propose a novel loss function called torus loss which can make the embedding space of distance metric more discriminative. Our approach is highly efficient and requires only a few training samples while exhibiting the remarkable ability to handle novel characters, and symbols. To enhance dataset diversity, a new manuscript dataset that contains the ancient Dongba hieroglyphics (DBH) is created. We conduct experiments on publicly available VML-HD, TKH, NC datasets, and the new proposed DBH dataset. The experimental results demonstrate that OTS outperforms the state-of-the-art methods in one-shot text spotting. Overall, our proposed method offers promising applications in the field of text spotting in historical manuscripts.
Handwritten digit string recognition by combination of residual network and RNN-CTC
Oct 09, 2017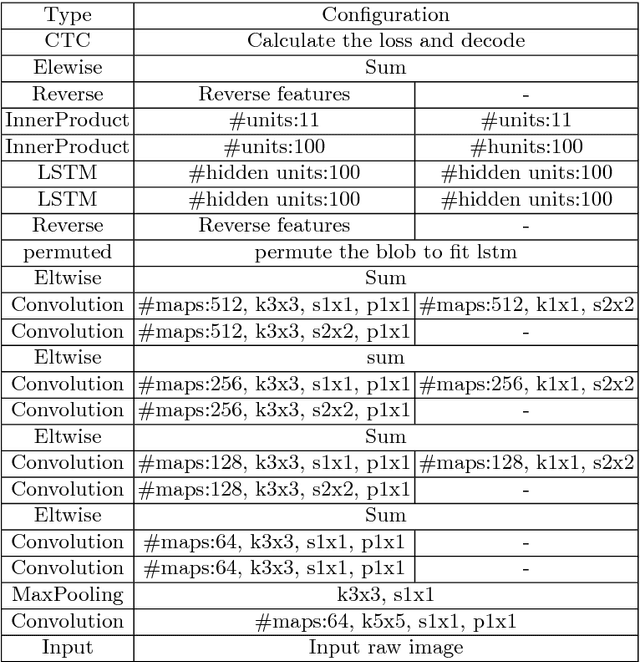
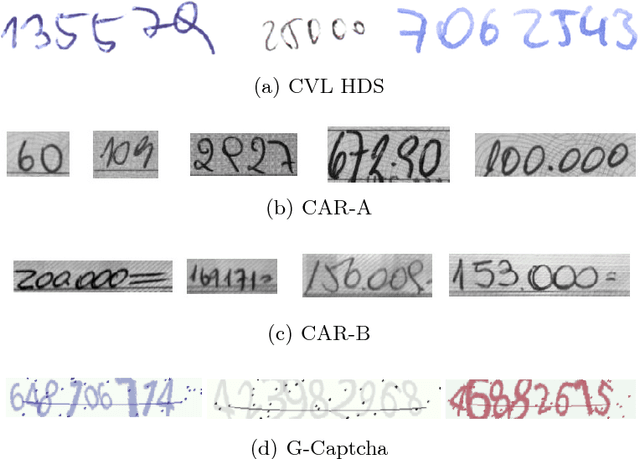
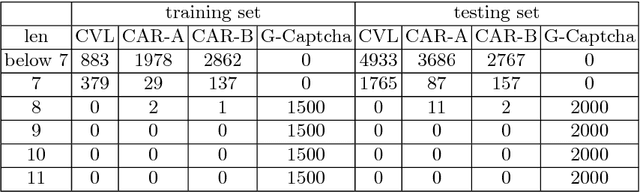
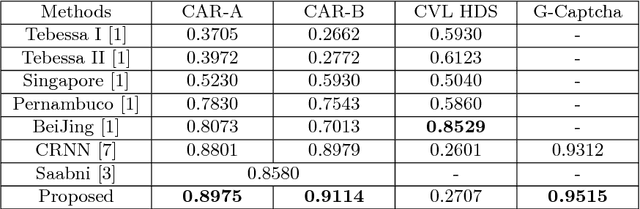
Recurrent neural network (RNN) and connectionist temporal classification (CTC) have showed successes in many sequence labeling tasks with the strong ability of dealing with the problems where the alignment between the inputs and the target labels is unknown. Residual network is a new structure of convolutional neural network and works well in various computer vision tasks. In this paper, we take advantage of the architectures mentioned above to create a new network for handwritten digit string recognition. First we design a residual network to extract features from input images, then we employ a RNN to model the contextual information within feature sequences and predict recognition results. At the top of this network, a standard CTC is applied to calculate the loss and yield the final results. These three parts compose an end-to-end trainable network. The proposed new architecture achieves the highest performances on ORAND-CAR-A and ORAND-CAR-B with recognition rates 89.75% and 91.14%, respectively. In addition, the experiments on a generated captcha dataset which has much longer string length show the potential of the proposed network to handle long strings.