 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Scene Text Generation for Low-resource Languages
Jun 27, 2023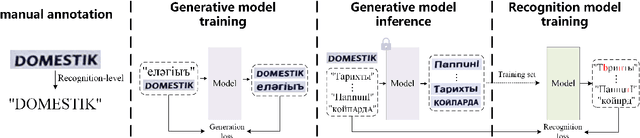
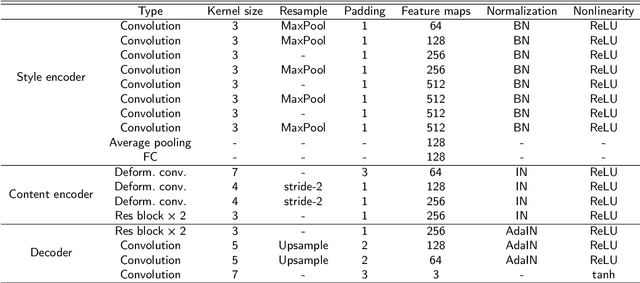
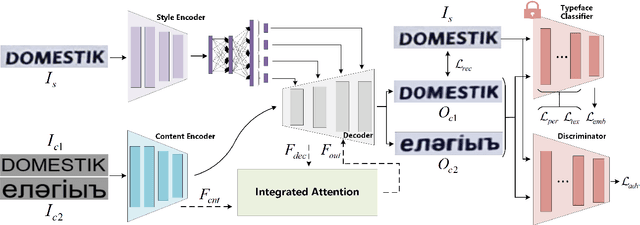
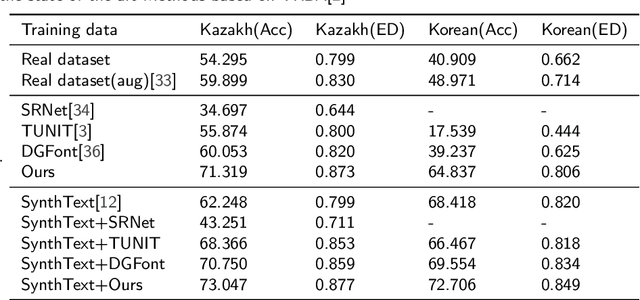
A large number of annotated training images is crucial for training successful scene text recognition models. However, collecting sufficient datasets can be a labor-intensive and costly process, particularly for low-resource languages. To address this challenge, auto-generating text data has shown promise in alleviating the problem. Unfortunately, existing scene text generation methods typically rely on a large amount of paired data, which is difficult to obtain for low-resource languages. In this paper, we propose a novel weakly supervised scene text generation method that leverages a few recognition-level labels as weak supervision. The proposed method is able to generate a large amount of scene text images with diverse backgrounds and font styles through cross-language generation. Our method disentangles the content and style features of scene text images, with the former representing textual information and the latter representing characteristics such as font, alignment, and background. To preserve the complete content structure of generated images, we introduce an integrated attention module. Furthermore, to bridge the style gap in the style of different languages, we incorporate a pre-trained font classifier. We evaluate our method using state-of-the-art scene text recognition models. Experiments demonstrate that our generated scene text significantly improves the scene text recognition accuracy and help achieve higher accuracy when complemented with other generative methods.
DGFont++: Robust Deformable Generative Networks for Unsupervised Font Generation
Dec 30, 2022Automatic font generation without human experts is a practical and significant problem, especially for some languages that consist of a large number of characters. Existing methods for font generation are often in supervised learning. They require a large number of paired data, which are labor-intensive and expensive to collect. In contrast, common unsupervised image-to-image translation methods are not applicable to font generation, as they often define style as the set of textures and colors. In this work, we propose a robust deformable generative network for unsupervised font generation (abbreviated as DGFont++). We introduce a feature deformation skip connection (FDSC) to learn local patterns and geometric transformations between fonts. The FDSC predicts pairs of displacement maps and employs the predicted maps to apply deformable convolution to the low-level content feature maps. The outputs of FDSC are fed into a mixer to generate final results. Moreover, we introduce contrastive self-supervised learning to learn a robust style representation for fonts by understanding the similarity and dissimilarities of fonts. To distinguish different styles, we train our model with a multi-task discriminator, which ensures that each style can be discriminated independently. In addition to adversarial loss, another two reconstruction losses are adopted to constrain the domain-invariant characteristics between generated images and content images. Taking advantage of FDSC and the adopted loss functions, our model is able to maintain spatial information and generates high-quality character images in an unsupervised manner. Experiments demonstrate that our model is able to generate character images of higher quality than state-of-the-art methods.
DG-Font: Deformable Generative Networks for Unsupervised Font Generation
Apr 08, 2021
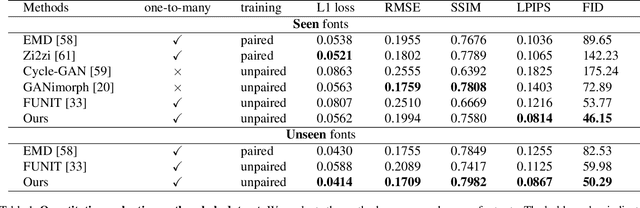
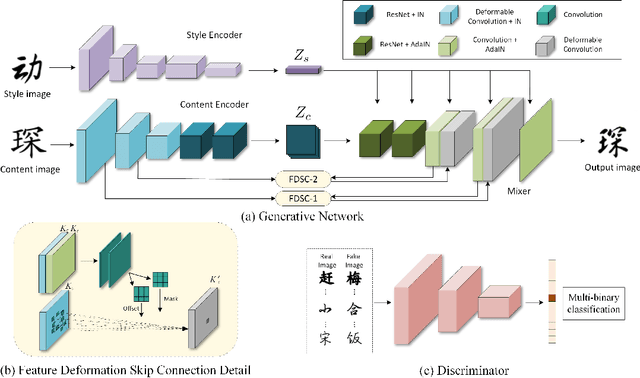

Font generation is a challenging problem especially for some writing systems that consist of a large number of characters and has attracted a lot of attention in recent years. However, existing methods for font generation are often in supervised learning. They require a large number of paired data, which is labor-intensive and expensive to collect. Besides, common image-to-image translation models often define style as the set of textures and colors, which cannot be directly applied to font generation. To address these problems, we propose novel deformable generative networks for unsupervised font generation (DGFont). We introduce a feature deformation skip connection (FDSC) which predicts pairs of displacement maps and employs the predicted maps to apply deformable convolution to the low-level feature maps from the content encoder. The outputs of FDSC are fed into a mixer to generate the final results. Taking advantage of FDSC, the mixer outputs a high-quality character with a complete structure. To further improve the quality of generated images, we use three deformable convolution layers in the content encoder to learn style-invariant feature representations. Experiments demonstrate that our model generates characters in higher quality than state-of-art methods. The source code is available at https://github.com/ecnuycxie/DG-Font.