 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Scene Text Generation for Low-resource Languages
Jun 27, 2023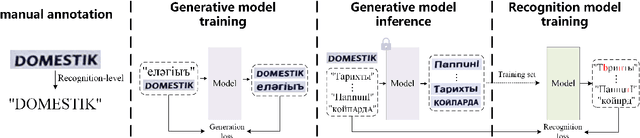
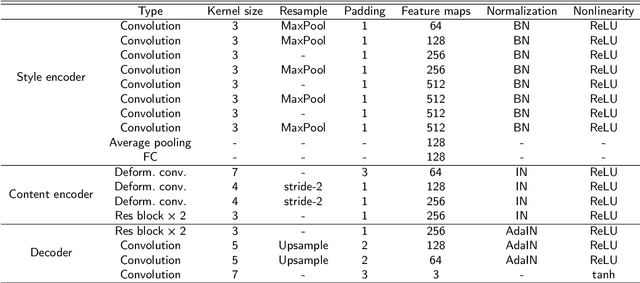
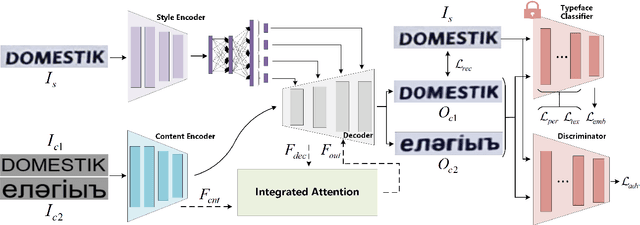
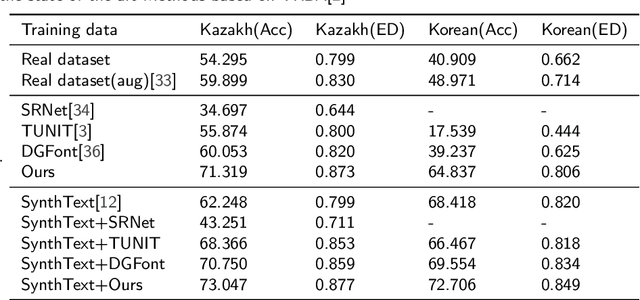
A large number of annotated training images is crucial for training successful scene text recognition models. However, collecting sufficient datasets can be a labor-intensive and costly process, particularly for low-resource languages. To address this challenge, auto-generating text data has shown promise in alleviating the problem. Unfortunately, existing scene text generation methods typically rely on a large amount of paired data, which is difficult to obtain for low-resource languages. In this paper, we propose a novel weakly supervised scene text generation method that leverages a few recognition-level labels as weak supervision. The proposed method is able to generate a large amount of scene text images with diverse backgrounds and font styles through cross-language generation. Our method disentangles the content and style features of scene text images, with the former representing textual information and the latter representing characteristics such as font, alignment, and background. To preserve the complete content structure of generated images, we introduce an integrated attention module. Furthermore, to bridge the style gap in the style of different languages, we incorporate a pre-trained font classifier. We evaluate our method using state-of-the-art scene text recognition models. Experiments demonstrate that our generated scene text significantly improves the scene text recognition accuracy and help achieve higher accuracy when complemented with other generative methods.