 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenign in Isolation, Harmful in Composition: Security Risks in Agent Skill Ecosystems
Jun 13, 2026Skills are becoming the capability layer through which LLM agents turn plans into actions, but their use introduces security risks such as data leakage, unauthorized operations, and tool misuse. Existing vetting usually evaluates each skill in isolation, while real agent tasks often invoke multiple skills in a shared execution context. This creates Skill Composition Risk (SCR): a skill that appears benign alone can become harmful when its outputs, trust signals, authorization cues, or side effects influence later invocations along an activated path. We introduce SCR-Bench to evaluate this risk in controlled, sandboxed skill environments. Rather than relying only on textual intent or surface behavior, SCR-Bench records downstream state changes and path-level outcomes across composed skill executions. It contains three sub-benchmarks: SCR-CapFlow for capability-flow composition, SCR-TrustLift for trust-transfer composition, and SCR-AuthBlur for authorization-confusion composition. Across SCR-Bench, composed paths expose risks that are largely absent under isolated evaluation. In SCR-CapFlow, attack success rate reaches 33.6 percent under composition, compared with near-zero isolated baselines. In SCR-TrustLift, attack success rate exceeds 96.5 percent on four of five backends. In SCR-AuthBlur, the risky-approval rate increases by 71.8 percent relative to the L0 isolated baseline under the L1 context setting. These results show that agent skill security should be assessed at the level of activated paths rather than isolated artifacts. SCR and SCR-Bench provide a foundation for path-aware risk evaluation and defense in LLM agent skill ecosystems. Benchmark: https://github.com/saint-viperx/SCR_Bench.
Face-D(^2)CL: Multi-Domain Synergistic Representation with Dual Continual Learning for Facial DeepFake Detection
Apr 09, 2026The rapid advancement of facial forgery techniques poses severe threats to public trust and information security, making facial DeepFake detection a critical research priority. Continual learning provides an effective approach to adapt facial DeepFake detection models to evolving forgery patterns. However, existing methods face two key bottlenecks in real-world continual learning scenarios: insufficient feature representation and catastrophic forgetting. To address these issues, we propose Face-D(^2)CL, a framework for facial DeepFake detection. It leverages multi-domain synergistic representation to fuse spatial and frequency-domain features for the comprehensive capture of diverse forgery traces, and employs a dual continual learning mechanism that combines Elastic Weight Consolidation (EWC), which distinguishes parameter importance for real versus fake samples, and Orthogonal Gradient Constraint (OGC), which ensures updates to task-specific adapters do not interfere with previously learned knowledge. This synergy enables the model to achieve a dynamic balance between robust anti-forgetting capabilities and agile adaptability to emerging facial forgery paradigms, all without relying on historical data replay. Extensive experiments demonstrate that our method surpasses current SOTA approaches in both stability and plasticity, achieving 60.7% relative reduction in average detection error rate, respectively. On unseen forgery domains, it further improves the average detection AUC by 7.9% compared to the current SOTA method.
Tex3D: Objects as Attack Surfaces via Adversarial 3D Textures for Vision-Language-Action Models
Apr 02, 2026Vision-language-action (VLA) models have shown strong performance in robotic manipulation, yet their robustness to physically realizable adversarial attacks remains underexplored. Existing studies reveal vulnerabilities through language perturbations and 2D visual attacks, but these attack surfaces are either less representative of real deployment or limited in physical realism. In contrast, adversarial 3D textures pose a more physically plausible and damaging threat, as they are naturally attached to manipulated objects and are easier to deploy in physical environments. Bringing adversarial 3D textures to VLA systems is nevertheless nontrivial. A central obstacle is that standard 3D simulators do not provide a differentiable optimization path from the VLA objective function back to object appearance, making it difficult to optimize through an end-to-end manner. To address this, we introduce Foreground-Background Decoupling (FBD), which enables differentiable texture optimization through dual-renderer alignment while preserving the original simulation environment. To further ensure that the attack remains effective across long-horizon and diverse viewpoints in the physical world, we propose Trajectory-Aware Adversarial Optimization (TAAO), which prioritizes behaviorally critical frames and stabilizes optimization with a vertex-based parameterization. Built on these designs, we present Tex3D, the first framework for end-to-end optimization of 3D adversarial textures directly within the VLA simulation environment. Experiments in both simulation and real-robot settings show that Tex3D significantly degrades VLA performance across multiple manipulation tasks, achieving task failure rates of up to 96.7\%. Our empirical results expose critical vulnerabilities of VLA systems to physically grounded 3D adversarial attacks and highlight the need for robustness-aware training.
TAME: A Trustworthy Test-Time Evolution of Agent Memory with Systematic Benchmarking
Feb 03, 2026Test-time evolution of agent memory serves as a pivotal paradigm for achieving AGI by bolstering complex reasoning through experience accumulation. However, even during benign task evolution, agent safety alignment remains vulnerable-a phenomenon known as Agent Memory Misevolution. To evaluate this phenomenon, we construct the Trust-Memevo benchmark to assess multi-dimensional trustworthiness during benign task evolution, revealing an overall decline in trustworthiness across various task domains and evaluation settings. To address this issue, we propose TAME, a dual-memory evolutionary framework that separately evolves executor memory to improve task performance by distilling generalizable methodologies, and evaluator memory to refine assessments of both safety and task utility based on historical feedback. Through a closed loop of memory filtering, draft generation, trustworthy refinement, execution, and dual-track memory updating, TAME preserves trustworthiness without sacrificing utility. Experiments demonstrate that TAME mitigates misevolution, achieving a joint improvement in both trustworthiness and task performance.
Adversarial Attacks on Medical Hyperspectral Imaging Exploiting Spectral-Spatial Dependencies and Multiscale Features
Jan 11, 2026Medical hyperspectral imaging (HSI) enables accurate disease diagnosis by capturing rich spectral-spatial tissue information, but recent advances in deep learning have exposed its vulnerability to adversarial attacks. In this work, we identify two fundamental causes of this fragility: the reliance on local pixel dependencies for preserving tissue structure and the dependence on multiscale spectral-spatial representations for hierarchical feature encoding. Building on these insights, we propose a targeted adversarial attack framework for medical HSI, consisting of a Local Pixel Dependency Attack that exploits spatial correlations among neighboring pixels, and a Multiscale Information Attack that perturbs features across hierarchical spectral-spatial scales. Experiments on the Brain and MDC datasets demonstrate that our attacks significantly degrade classification performance, especially in tumor regions, while remaining visually imperceptible. Compared with existing methods, our approach reveals the unique vulnerabilities of medical HSI models and underscores the need for robust, structure-aware defenses in clinical applications.
Who Can See Through You? Adversarial Shielding Against VLM-Based Attribute Inference Attacks
Dec 20, 2025As vision-language models (VLMs) become widely adopted, VLM-based attribute inference attacks have emerged as a serious privacy concern, enabling adversaries to infer private attributes from images shared on social media. This escalating threat calls for dedicated protection methods to safeguard user privacy. However, existing methods often degrade the visual quality of images or interfere with vision-based functions on social media, thereby failing to achieve a desirable balance between privacy protection and user experience. To address this challenge, we propose a novel protection method that jointly optimizes privacy suppression and utility preservation under a visual consistency constraint. While our method is conceptually effective, fair comparisons between methods remain challenging due to the lack of publicly available evaluation datasets. To fill this gap, we introduce VPI-COCO, a publicly available benchmark comprising 522 images with hierarchically structured privacy questions and corresponding non-private counterparts, enabling fine-grained and joint evaluation of protection methods in terms of privacy preservation and user experience. Building upon this benchmark, experiments on multiple VLMs demonstrate that our method effectively reduces PAR below 25%, keeps NPAR above 88%, maintains high visual consistency, and generalizes well to unseen and paraphrased privacy questions, demonstrating its strong practical applicability for real-world VLM deployments.
KG-DF: A Black-box Defense Framework against Jailbreak Attacks Based on Knowledge Graphs
Nov 09, 2025With the widespread application of large language models (LLMs) in various fields, the security challenges they face have become increasingly prominent, especially the issue of jailbreak. These attacks induce the model to generate erroneous or uncontrolled outputs through crafted inputs, threatening the generality and security of the model. Although existing defense methods have shown some effectiveness, they often struggle to strike a balance between model generality and security. Excessive defense may limit the normal use of the model, while insufficient defense may lead to security vulnerabilities. In response to this problem, we propose a Knowledge Graph Defense Framework (KG-DF). Specifically, because of its structured knowledge representation and semantic association capabilities, Knowledge Graph(KG) can be searched by associating input content with safe knowledge in the knowledge base, thus identifying potentially harmful intentions and providing safe reasoning paths. However, traditional KG methods encounter significant challenges in keyword extraction, particularly when confronted with diverse and evolving attack strategies. To address this issue, we introduce an extensible semantic parsing module, whose core task is to transform the input query into a set of structured and secure concept representations, thereby enhancing the relevance of the matching process. Experimental results show that our framework enhances defense performance against various jailbreak attack methods, while also improving the response quality of the LLM in general QA scenarios by incorporating domain-general knowledge.
Exploring the Secondary Risks of Large Language Models
Jun 14, 2025


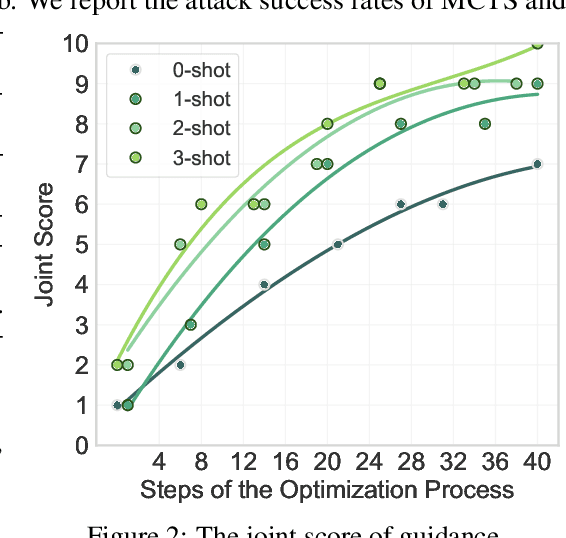
Ensuring the safety and alignment of Large Language Models is a significant challenge with their growing integration into critical applications and societal functions. While prior research has primarily focused on jailbreak attacks, less attention has been given to non-adversarial failures that subtly emerge during benign interactions. We introduce secondary risks a novel class of failure modes marked by harmful or misleading behaviors during benign prompts. Unlike adversarial attacks, these risks stem from imperfect generalization and often evade standard safety mechanisms. To enable systematic evaluation, we introduce two risk primitives verbose response and speculative advice that capture the core failure patterns. Building on these definitions, we propose SecLens, a black-box, multi-objective search framework that efficiently elicits secondary risk behaviors by optimizing task relevance, risk activation, and linguistic plausibility. To support reproducible evaluation, we release SecRiskBench, a benchmark dataset of 650 prompts covering eight diverse real-world risk categories. Experimental results from extensive evaluations on 16 popular models demonstrate that secondary risks are widespread, transferable across models, and modality independent, emphasizing the urgent need for enhanced safety mechanisms to address benign yet harmful LLM behaviors in real-world deployments.
FGS-Audio: Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation
May 28, 2025



The rapid development of Artificial Intelligence Generated Content (AIGC) has made high-fidelity generated audio widely available across the Internet, offering an abundant and versatile source of cover signals for covert communication. Driven by advances in deep learning, current audio steganography frameworks are mainly based on encoding-decoding network architectures. While these methods greatly improve the security of audio steganography, they typically employ elaborate training workflows and rely on extensive pre-trained models. To address the aforementioned issues, this paper pioneers a Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation (FGS-Audio). The adversarial perturbations that carry secret information are embedded into cover audio to generate stego audio. The receiver only needs to share the structure and weights of the fixed decoding network to accurately extract the secret information from the stego audio, thus eliminating the reliance on large pre-trained models. In FGS-Audio, we propose an audio Adversarial Perturbation Generation (APG) strategy and design a lightweight fixed decoder. The fixed decoder guarantees reliable extraction of the hidden message, while the adversarial perturbations are optimized to keep the stego audio perceptually and statistically close to the cover audio, thereby improving resistance to steganalysis. The experimental results show that the method exhibits excellent anti-steganalysis performance under different relative payloads, outperforming existing SOTA approaches. In terms of stego audio quality, FGS-Audio achieves an average PSNR improvement of over 10 dB compared to SOTA method.
Protecting Copyright of Medical Pre-trained Language Models: Training-Free Backdoor Watermarking
Sep 14, 2024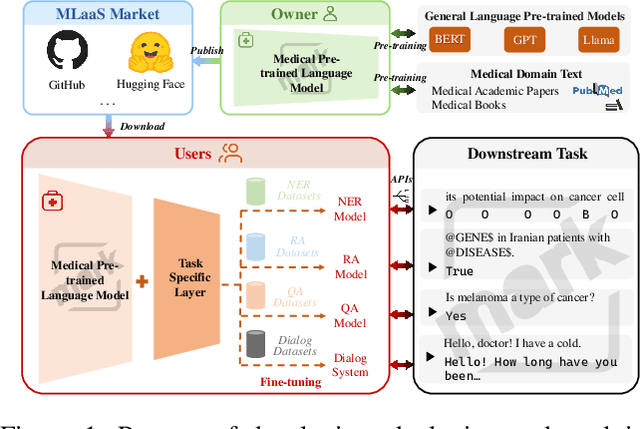



Pre-training language models followed by fine-tuning on specific tasks is standard in NLP, but traditional models often underperform when applied to the medical domain, leading to the development of specialized medical pre-trained language models (Med-PLMs). These models are valuable assets but are vulnerable to misuse and theft, requiring copyright protection. However, no existing watermarking methods are tailored for Med-PLMs, and adapting general PLMs watermarking techniques to the medical domain faces challenges such as task incompatibility, loss of fidelity, and inefficiency. To address these issues, we propose the first training-free backdoor watermarking method for Med-PLMs. Our method uses rare special symbols as trigger words, which do not impact downstream task performance, embedding watermarks by replacing their original embeddings with those of specific medical terms in the Med-PLMs' word embeddings layer. After fine-tuning the watermarked Med-PLMs on various medical downstream tasks, the final models (FMs) respond to the trigger words in the same way they would to the corresponding medical terms. This property can be utilized to extract the watermark. Experiments demonstrate that our method achieves high fidelity while effectively extracting watermarks across various medical downstream tasks. Additionally, our method demonstrates robustness against various attacks and significantly enhances the efficiency of watermark embedding, reducing the embedding time from 10 hours to 10 seconds.