 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceCat: Enhancing Face Recognition Security with a Unified Generative Model Framework
Apr 14, 2024Face anti-spoofing (FAS) and adversarial detection (FAD) have been regarded as critical technologies to ensure the safety of face recognition systems. As a consequence of their limited practicality and generalization, some existing methods aim to devise a framework capable of concurrently detecting both threats to address the challenge. Nevertheless, these methods still encounter challenges of insufficient generalization and suboptimal robustness, potentially owing to the inherent drawback of discriminative models. Motivated by the rich structural and detailed features of face generative models, we propose FaceCat which utilizes the face generative model as a pre-trained model to improve the performance of FAS and FAD. Specifically, FaceCat elaborately designs a hierarchical fusion mechanism to capture rich face semantic features of the generative model. These features then serve as a robust foundation for a lightweight head, designed to execute FAS and FAD tasks simultaneously. As relying solely on single-modality data often leads to suboptimal performance, we further propose a novel text-guided multi-modal alignment strategy that utilizes text prompts to enrich feature representation, thereby enhancing performance. For fair evaluations, we build a comprehensive protocol with a wide range of 28 attack types to benchmark the performance. Extensive experiments validate the effectiveness of FaceCat generalizes significantly better and obtains excellent robustness against input transformations.
Seeing through the Mask: Multi-task Generative Mask Decoupling Face Recognition
Nov 20, 2023

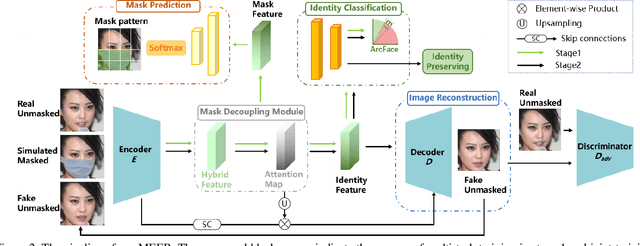

The outbreak of COVID-19 pandemic make people wear masks more frequently than ever. Current general face recognition system suffers from serious performance degradation,when encountering occluded scenes. The potential reason is that face features are corrupted by occlusions on key facial regions. To tackle this problem, previous works either extract identity-related embeddings on feature level by additional mask prediction, or restore the occluded facial part by generative models. However, the former lacks visual results for model interpretation, while the latter suffers from artifacts which may affect downstream recognition. Therefore, this paper proposes a Multi-task gEnerative mask dEcoupling face Recognition (MEER) network to jointly handle these two tasks, which can learn occlusionirrelevant and identity-related representation while achieving unmasked face synthesis. We first present a novel mask decoupling module to disentangle mask and identity information, which makes the network obtain purer identity features from visible facial components. Then, an unmasked face is restored by a joint-training strategy, which will be further used to refine the recognition network with an id-preserving loss. Experiments on masked face recognition under realistic and synthetic occlusions benchmarks demonstrate that the MEER can outperform the state-ofthe-art methods.
AdvFAS: A robust face anti-spoofing framework against adversarial examples
Aug 04, 2023Ensuring the reliability of face recognition systems against presentation attacks necessitates the deployment of face anti-spoofing techniques. Despite considerable advancements in this domain, the ability of even the most state-of-the-art methods to defend against adversarial examples remains elusive. While several adversarial defense strategies have been proposed, they typically suffer from constrained practicability due to inevitable trade-offs between universality, effectiveness, and efficiency. To overcome these challenges, we thoroughly delve into the coupled relationship between adversarial detection and face anti-spoofing. Based on this, we propose a robust face anti-spoofing framework, namely AdvFAS, that leverages two coupled scores to accurately distinguish between correctly detected and wrongly detected face images. Extensive experiments demonstrate the effectiveness of our framework in a variety of settings, including different attacks, datasets, and backbones, meanwhile enjoying high accuracy on clean examples. Moreover, we successfully apply the proposed method to detect real-world adversarial examples.
Improving Viewpoint Robustness for Visual Recognition via Adversarial Training
Jul 21, 2023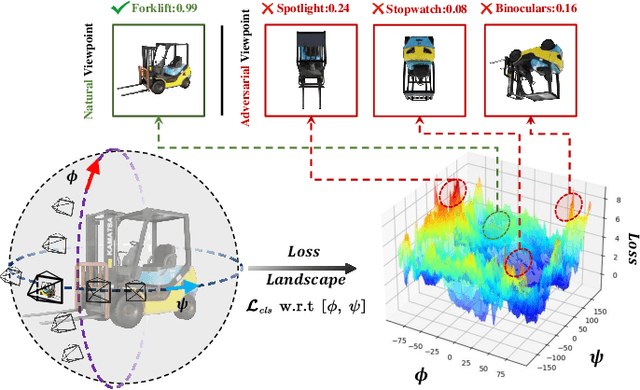
Viewpoint invariance remains challenging for visual recognition in the 3D world, as altering the viewing directions can significantly impact predictions for the same object. While substantial efforts have been dedicated to making neural networks invariant to 2D image translations and rotations, viewpoint invariance is rarely investigated. Motivated by the success of adversarial training in enhancing model robustness, we propose Viewpoint-Invariant Adversarial Training (VIAT) to improve the viewpoint robustness of image classifiers. Regarding viewpoint transformation as an attack, we formulate VIAT as a minimax optimization problem, where the inner maximization characterizes diverse adversarial viewpoints by learning a Gaussian mixture distribution based on the proposed attack method GMVFool. The outer minimization obtains a viewpoint-invariant classifier by minimizing the expected loss over the worst-case viewpoint distributions that can share the same one for different objects within the same category. Based on GMVFool, we contribute a large-scale dataset called ImageNet-V+ to benchmark viewpoint robustness. Experimental results show that VIAT significantly improves the viewpoint robustness of various image classifiers based on the diversity of adversarial viewpoints generated by GMVFool. Furthermore, we propose ViewRS, a certified viewpoint robustness method that provides a certified radius and accuracy to demonstrate the effectiveness of VIAT from the theoretical perspective.
Towards Viewpoint-Invariant Visual Recognition via Adversarial Training
Jul 16, 2023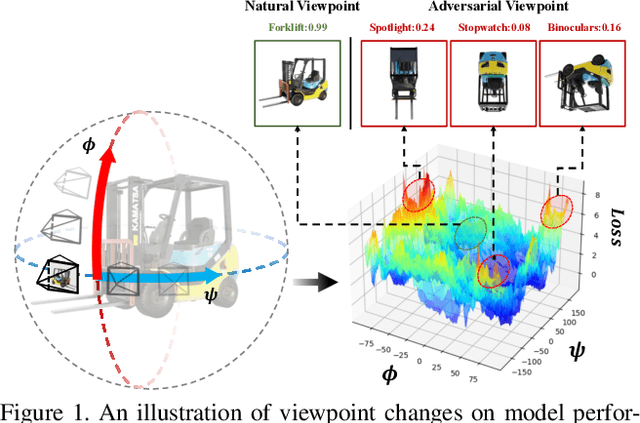
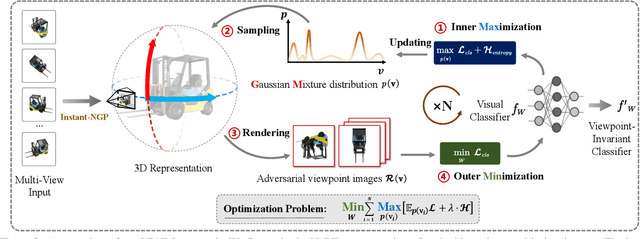

Visual recognition models are not invariant to viewpoint changes in the 3D world, as different viewing directions can dramatically affect the predictions given the same object. Although many efforts have been devoted to making neural networks invariant to 2D image translations and rotations, viewpoint invariance is rarely investigated. As most models process images in the perspective view, it is challenging to impose invariance to 3D viewpoint changes based only on 2D inputs. Motivated by the success of adversarial training in promoting model robustness, we propose Viewpoint-Invariant Adversarial Training (VIAT) to improve viewpoint robustness of common image classifiers. By regarding viewpoint transformation as an attack, VIAT is formulated as a minimax optimization problem, where the inner maximization characterizes diverse adversarial viewpoints by learning a Gaussian mixture distribution based on a new attack GMVFool, while the outer minimization trains a viewpoint-invariant classifier by minimizing the expected loss over the worst-case adversarial viewpoint distributions. To further improve the generalization performance, a distribution sharing strategy is introduced leveraging the transferability of adversarial viewpoints across objects. Experiments validate the effectiveness of VIAT in improving the viewpoint robustness of various image classifiers based on the diversity of adversarial viewpoints generated by GMVFool.
Adversarial Examples Detection with Enhanced Image Difference Features based on Local Histogram Equalization
May 08, 2023Deep Neural Networks (DNNs) have recently made significant progress in many fields. However, studies have shown that DNNs are vulnerable to adversarial examples, where imperceptible perturbations can greatly mislead DNNs even if the full underlying model parameters are not accessible. Various defense methods have been proposed, such as feature compression and gradient masking. However, numerous studies have proven that previous methods create detection or defense against certain attacks, which renders the method ineffective in the face of the latest unknown attack methods. The invisibility of adversarial perturbations is one of the evaluation indicators for adversarial example attacks, which also means that the difference in the local correlation of high-frequency information in adversarial examples and normal examples can be used as an effective feature to distinguish the two. Therefore, we propose an adversarial example detection framework based on a high-frequency information enhancement strategy, which can effectively extract and amplify the feature differences between adversarial examples and normal examples. Experimental results show that the feature augmentation module can be combined with existing detection models in a modular way under this framework. Improve the detector's performance and reduce the deployment cost without modifying the existing detection model.
A Survey of Face Recognition
Dec 26, 2022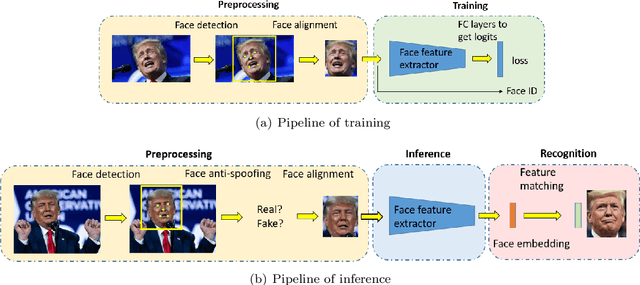
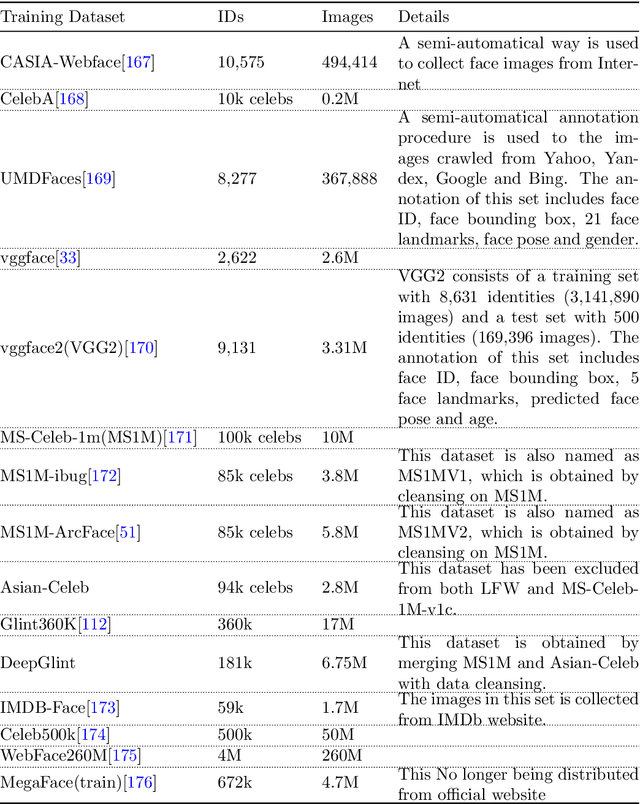
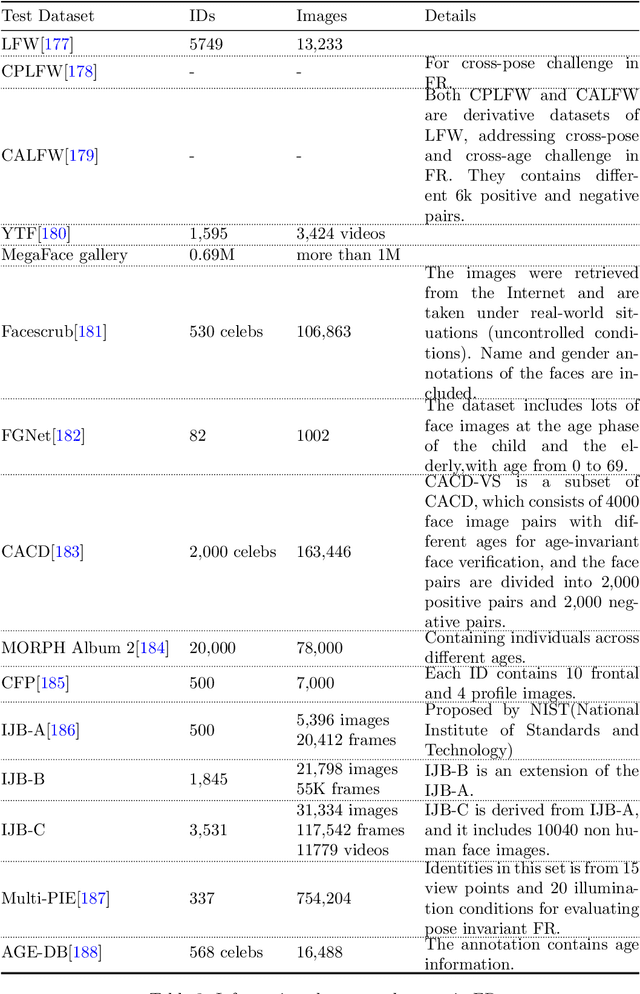
Recent years witnessed the breakthrough of face recognition with deep convolutional neural networks. Dozens of papers in the field of FR are published every year. Some of them were applied in the industrial community and played an important role in human life such as device unlock, mobile payment, and so on. This paper provides an introduction to face recognition, including its history, pipeline, algorithms based on conventional manually designed features or deep learning, mainstream training, evaluation datasets, and related applications. We have analyzed and compared state-of-the-art works as many as possible, and also carefully designed a set of experiments to find the effect of backbone size and data distribution. This survey is a material of the tutorial named The Practical Face Recognition Technology in the Industrial World in the FG2023.
Racial Faces in-the-Wild: Reducing Racial Bias by Deep Unsupervised Domain Adaptation
Dec 01, 2018
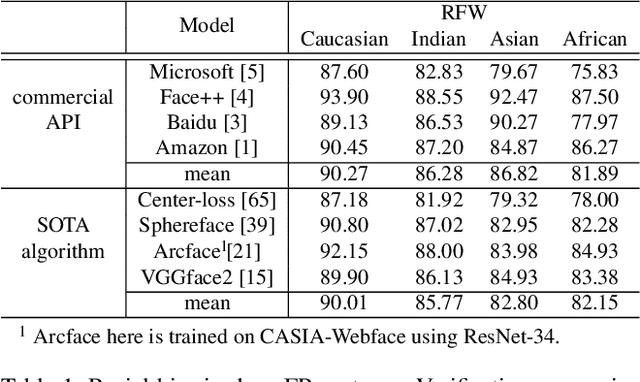
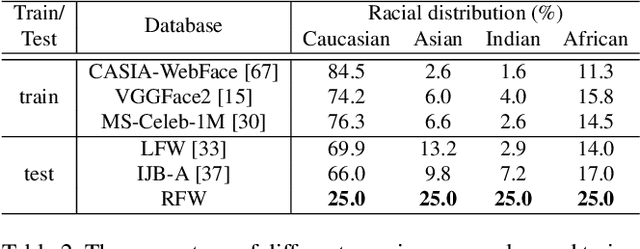

Despite of the progress achieved by deep learning in face recognition (FR), more and more people find that racial bias explicitly degrades the performance in realistic FR systems. Facing the fact that existing training and testing databases consist of almost Caucasian subjects, there are still no independent testing databases to evaluate racial bias and even no training databases and methods to reduce it. To facilitate the research towards conquering those unfair issues, this paper contributes a new dataset called Racial Faces in-the-Wild (RFW) database with two important uses, 1) racial bias testing: four testing subsets, namely Caucasian, Asian, Indian and African, are constructed, and each contains about 3000 individuals with 6000 image pairs for face verification, 2) racial bias reducing: one labeled training subset with Caucasians and three unlabeled training subsets with Asians, Indians and Africans are offered to encourage FR algorithms to transfer recognition knowledge from Caucasians to other races. For we all know, RFW is the first database for measuring racial bias in FR algorithms. After proving the existence of domain gap among different races and the existence of racial bias in FR algorithms, we further propose a deep information maximization adaptation network (IMAN) to bridge the domain gap, and comprehensive experiments show that the racial bias could be narrowed-down by our algorithm.