 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Viewpoint Robustness for Visual Recognition via Adversarial Training
Paper and Code
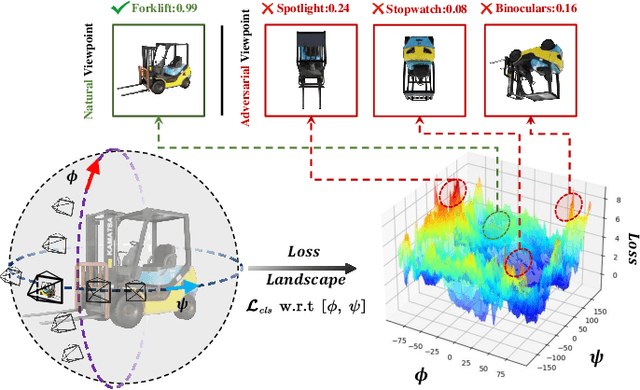
Viewpoint invariance remains challenging for visual recognition in the 3D world, as altering the viewing directions can significantly impact predictions for the same object. While substantial efforts have been dedicated to making neural networks invariant to 2D image translations and rotations, viewpoint invariance is rarely investigated. Motivated by the success of adversarial training in enhancing model robustness, we propose Viewpoint-Invariant Adversarial Training (VIAT) to improve the viewpoint robustness of image classifiers. Regarding viewpoint transformation as an attack, we formulate VIAT as a minimax optimization problem, where the inner maximization characterizes diverse adversarial viewpoints by learning a Gaussian mixture distribution based on the proposed attack method GMVFool. The outer minimization obtains a viewpoint-invariant classifier by minimizing the expected loss over the worst-case viewpoint distributions that can share the same one for different objects within the same category. Based on GMVFool, we contribute a large-scale dataset called ImageNet-V+ to benchmark viewpoint robustness. Experimental results show that VIAT significantly improves the viewpoint robustness of various image classifiers based on the diversity of adversarial viewpoints generated by GMVFool. Furthermore, we propose ViewRS, a certified viewpoint robustness method that provides a certified radius and accuracy to demonstrate the effectiveness of VIAT from the theoretical perspective.