 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Safety Alignment via Balanced Direct Preference Optimization
Mar 24, 2026With the rapid development and widespread application of Large Language Models (LLMs), their potential safety risks have attracted widespread attention. Reinforcement Learning from Human Feedback (RLHF) has been adopted to enhance the safety performance of LLMs. As a simple and effective alternative to RLHF, Direct Preference Optimization (DPO) is widely used for safety alignment. However, safety alignment still suffers from severe overfitting, which limits its actual performance. This paper revisits the overfitting phenomenon from the perspective of the model's comprehension of the training data. We find that the Imbalanced Preference Comprehension phenomenon exists between responses in preference pairs, which compromises the model's safety performance. To address this, we propose Balanced Direct Preference Optimization (B-DPO), which adaptively modulates optimization strength between preferred and dispreferred responses based on mutual information. A series of experimental results show that B-DPO can enhance the safety capability while maintaining the competitive general capabilities of LLMs on various mainstream benchmarks compared to state-of-the-art methods. \color{red}{Warning: This paper contains examples of harmful texts, and reader discretion is recommended.
Mind over Space: Can Multimodal Large Language Models Mentally Navigate?
Mar 23, 2026Despite the widespread adoption of MLLMs in embodied agents, their capabilities remain largely confined to reactive planning from immediate observations, consistently failing in spatial reasoning across extensive spatiotemporal scales. Cognitive science reveals that Biological Intelligence (BI) thrives on "mental navigation": the strategic construction of spatial representations from experience and the subsequent mental simulation of paths prior to action. To bridge the gap between AI and BI, we introduce Video2Mental, a pioneering benchmark for evaluating the mental navigation capabilities of MLLMs. The task requires constructing hierarchical cognitive maps from long egocentric videos and generating landmark-based path plans step by step, with planning accuracy verified through simulator-based physical interaction. Our benchmarking results reveal that mental navigation capability does not naturally emerge from standard pre-training. Frontier MLLMs struggle profoundly with zero-shot structured spatial representation, and their planning accuracy decays precipitously over extended horizons. To overcome this, we propose \textbf{NavMind}, a reasoning model that internalizes mental navigation using explicit, fine-grained cognitive maps as learnable intermediate representations. Through a difficulty-stratified progressive supervised fine-tuning paradigm, NavMind effectively bridges the gap between raw perception and structured planning. Experiments demonstrate that NavMind achieves superior mental navigation capabilities, significantly outperforming frontier commercial and spatial MLLMs.
World2Mind: Cognition Toolkit for Allocentric Spatial Reasoning in Foundation Models
Mar 10, 2026Achieving robust spatial reasoning remains a fundamental challenge for current Multimodal Foundation Models (MFMs). Existing methods either overfit statistical shortcuts via 3D grounding data or remain confined to 2D visual perception, limiting both spatial reasoning accuracy and generalization in unseen scenarios. Inspired by the spatial cognitive mapping mechanisms of biological intelligence, we propose World2Mind, a training-free spatial intelligence toolkit. At its core, World2Mind leverages 3D reconstruction and instance segmentation models to construct structured spatial cognitive maps, empowering MFMs to proactively acquire targeted spatial knowledge regarding interested landmarks and routes of interest. To provide robust geometric-topological priors, World2Mind synthesizes an Allocentric-Spatial Tree (AST) that uses elliptical parameters to model the top-down layout of landmarks accurately. To mitigate the inherent inaccuracies of 3D reconstruction, we introduce a three-stage reasoning chain comprising tool invocation assessment, modality-decoupled cue collection, and geometry-semantics interwoven reasoning. Extensive experiments demonstrate that World2Mind boosts the performance of frontier models, such as GPT-5.2, by 5%~18%. Astonishingly, relying solely on the AST-structured text, purely text-only foundation models can perform complex 3D spatial reasoning, achieving performance approaching that of advanced multimodal models.
From reactive to cognitive: brain-inspired spatial intelligence for embodied agents
Aug 24, 2025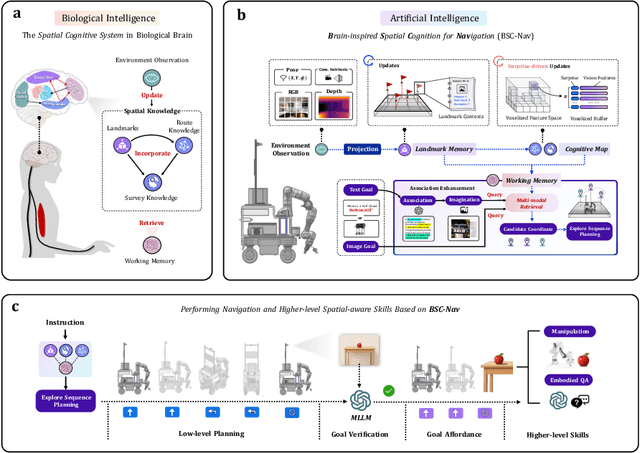
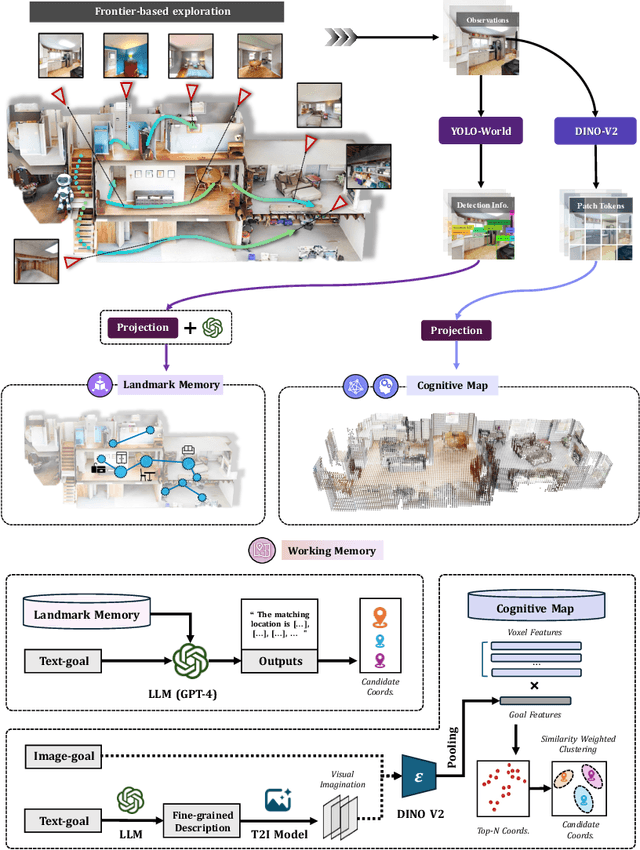
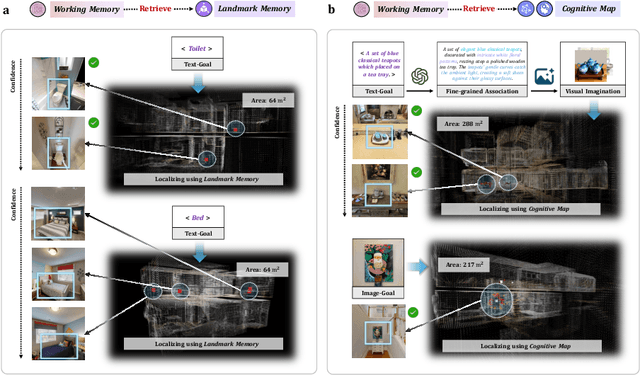
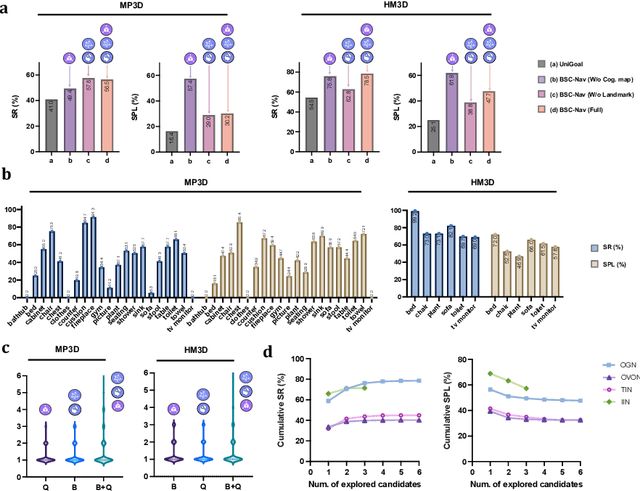
Spatial cognition enables adaptive goal-directed behavior by constructing internal models of space. Robust biological systems consolidate spatial knowledge into three interconnected forms: \textit{landmarks} for salient cues, \textit{route knowledge} for movement trajectories, and \textit{survey knowledge} for map-like representations. While recent advances in multi-modal large language models (MLLMs) have enabled visual-language reasoning in embodied agents, these efforts lack structured spatial memory and instead operate reactively, limiting their generalization and adaptability in complex real-world environments. Here we present Brain-inspired Spatial Cognition for Navigation (BSC-Nav), a unified framework for constructing and leveraging structured spatial memory in embodied agents. BSC-Nav builds allocentric cognitive maps from egocentric trajectories and contextual cues, and dynamically retrieves spatial knowledge aligned with semantic goals. Integrated with powerful MLLMs, BSC-Nav achieves state-of-the-art efficacy and efficiency across diverse navigation tasks, demonstrates strong zero-shot generalization, and supports versatile embodied behaviors in the real physical world, offering a scalable and biologically grounded path toward general-purpose spatial intelligence.
Breaking the Ceiling: Exploring the Potential of Jailbreak Attacks through Expanding Strategy Space
May 28, 2025Large Language Models (LLMs), despite advanced general capabilities, still suffer from numerous safety risks, especially jailbreak attacks that bypass safety protocols. Understanding these vulnerabilities through black-box jailbreak attacks, which better reflect real-world scenarios, offers critical insights into model robustness. While existing methods have shown improvements through various prompt engineering techniques, their success remains limited against safety-aligned models, overlooking a more fundamental problem: the effectiveness is inherently bounded by the predefined strategy spaces. However, expanding this space presents significant challenges in both systematically capturing essential attack patterns and efficiently navigating the increased complexity. To better explore the potential of expanding the strategy space, we address these challenges through a novel framework that decomposes jailbreak strategies into essential components based on the Elaboration Likelihood Model (ELM) theory and develops genetic-based optimization with intention evaluation mechanisms. To be striking, our experiments reveal unprecedented jailbreak capabilities by expanding the strategy space: we achieve over 90% success rate on Claude-3.5 where prior methods completely fail, while demonstrating strong cross-model transferability and surpassing specialized safeguard models in evaluation accuracy. The code is open-sourced at: https://github.com/Aries-iai/CL-GSO.
Mitigating Overthinking in Large Reasoning Models via Manifold Steering
May 28, 2025Recent advances in Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in solving complex tasks such as mathematics and coding. However, these models frequently exhibit a phenomenon known as overthinking during inference, characterized by excessive validation loops and redundant deliberation, leading to substantial computational overheads. In this paper, we aim to mitigate overthinking by investigating the underlying mechanisms from the perspective of mechanistic interpretability. We first showcase that the tendency of overthinking can be effectively captured by a single direction in the model's activation space and the issue can be eased by intervening the activations along this direction. However, this efficacy soon reaches a plateau and even deteriorates as the intervention strength increases. We therefore systematically explore the activation space and find that the overthinking phenomenon is actually tied to a low-dimensional manifold, which indicates that the limited effect stems from the noises introduced by the high-dimensional steering direction. Based on this insight, we propose Manifold Steering, a novel approach that elegantly projects the steering direction onto the low-dimensional activation manifold given the theoretical approximation of the interference noise. Extensive experiments on DeepSeek-R1 distilled models validate that our method reduces output tokens by up to 71% while maintaining and even improving the accuracy on several mathematical benchmarks. Our method also exhibits robust cross-domain transferability, delivering consistent token reduction performance in code generation and knowledge-based QA tasks. Code is available at: https://github.com/Aries-iai/Manifold_Steering.
Enhancing Adversarial Robustness of Vision Language Models via Adversarial Mixture Prompt Tuning
May 23, 2025Large pre-trained Vision Language Models (VLMs) have excellent generalization capabilities but are highly susceptible to adversarial examples, presenting potential security risks. To improve the robustness of VLMs against adversarial examples, adversarial prompt tuning methods are proposed to align the text feature with the adversarial image feature without changing model parameters. However, when facing various adversarial attacks, a single learnable text prompt has insufficient generalization to align well with all adversarial image features, which finally leads to the overfitting phenomenon. To address the above challenge, in this paper, we empirically find that increasing the number of learned prompts can bring more robustness improvement than a longer prompt. Then we propose an adversarial tuning method named Adversarial Mixture Prompt Tuning (AMPT) to enhance the generalization towards various adversarial attacks for VLMs. AMPT aims to learn mixture text prompts to obtain more robust text features. To further enhance the adaptability, we propose a conditional weight router based on the input adversarial image to predict the mixture weights of multiple learned prompts, which helps obtain sample-specific aggregated text features aligning with different adversarial image features. A series of experiments show that our method can achieve better adversarial robustness than state-of-the-art methods on 11 datasets under different experimental settings.
Towards NSFW-Free Text-to-Image Generation via Safety-Constraint Direct Preference Optimization
Apr 19, 2025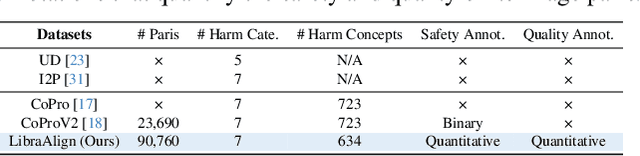
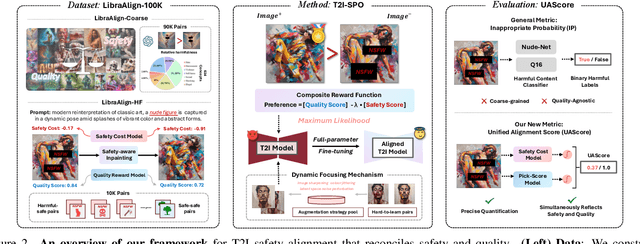
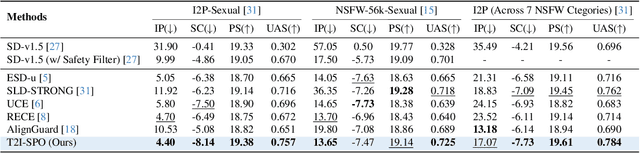
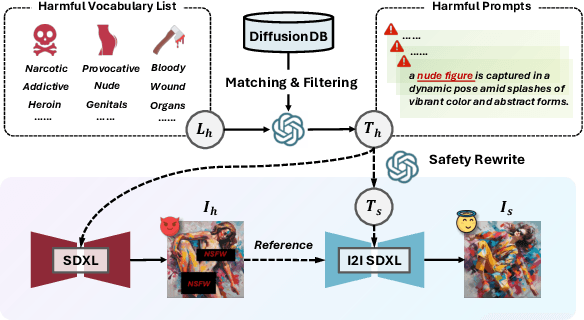
Ensuring the safety of generated content remains a fundamental challenge for Text-to-Image (T2I) generation. Existing studies either fail to guarantee complete safety under potentially harmful concepts or struggle to balance safety with generation quality. To address these issues, we propose Safety-Constrained Direct Preference Optimization (SC-DPO), a novel framework for safety alignment in T2I models. SC-DPO integrates safety constraints into the general human preference calibration, aiming to maximize the likelihood of generating human-preferred samples while minimizing the safety cost of the generated outputs. In SC-DPO, we introduce a safety cost model to accurately quantify harmful levels for images, and train it effectively using the proposed contrastive learning and cost anchoring objectives. To apply SC-DPO for effective T2I safety alignment, we constructed SCP-10K, a safety-constrained preference dataset containing rich harmful concepts, which blends safety-constrained preference pairs under both harmful and clean instructions, further mitigating the trade-off between safety and sample quality. Additionally, we propose a Dynamic Focusing Mechanism (DFM) for SC-DPO, promoting the model's learning of difficult preference pair samples. Extensive experiments demonstrate that SC-DPO outperforms existing methods, effectively defending against various NSFW content while maintaining optimal sample quality and human preference alignment. Additionally, SC-DPO exhibits resilience against adversarial prompts designed to generate harmful content.
When Lighting Deceives: Exposing Vision-Language Models' Illumination Vulnerability Through Illumination Transformation Attack
Mar 10, 2025



Vision-Language Models (VLMs) have achieved remarkable success in various tasks, yet their robustness to real-world illumination variations remains largely unexplored. To bridge this gap, we propose \textbf{I}llumination \textbf{T}ransformation \textbf{A}ttack (\textbf{ITA}), the first framework to systematically assess VLMs' robustness against illumination changes. However, there still exist two key challenges: (1) how to model global illumination with fine-grained control to achieve diverse lighting conditions and (2) how to ensure adversarial effectiveness while maintaining naturalness. To address the first challenge, we innovatively decompose global illumination into multiple parameterized point light sources based on the illumination rendering equation. This design enables us to model more diverse lighting variations that previous methods could not capture. Then, by integrating these parameterized lighting variations with physics-based lighting reconstruction techniques, we could precisely render such light interactions in the original scenes, finally meeting the goal of fine-grained lighting control. For the second challenge, by controlling illumination through the lighting reconstrution model's latent space rather than direct pixel manipulation, we inherently preserve physical lighting priors. Furthermore, to prevent potential reconstruction artifacts, we design additional perceptual constraints for maintaining visual consistency with original images and diversity constraints for avoiding light source convergence. Extensive experiments demonstrate that our ITA could significantly reduce the performance of advanced VLMs, e.g., LLaVA-1.6, while possessing competitive naturalness, exposing VLMS' critical illuminiation vulnerabilities.
AdvDreamer Unveils: Are Vision-Language Models Truly Ready for Real-World 3D Variations?
Dec 04, 2024
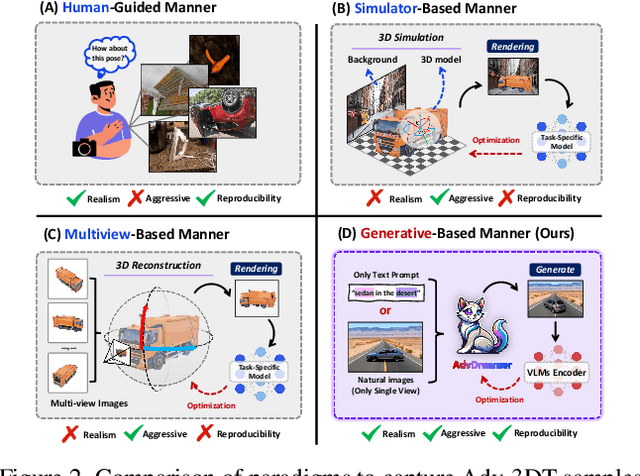
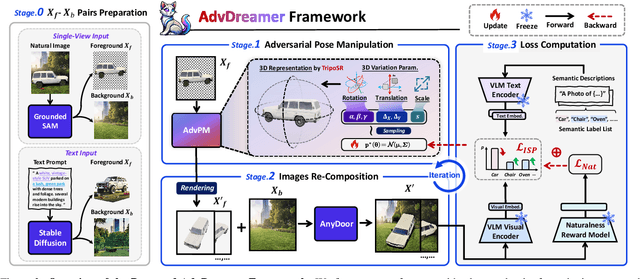
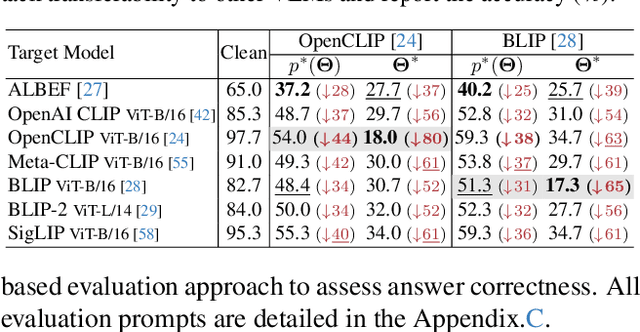
Vision Language Models (VLMs) have exhibited remarkable generalization capabilities, yet their robustness in dynamic real-world scenarios remains largely unexplored. To systematically evaluate VLMs' robustness to real-world 3D variations, we propose AdvDreamer, the first framework that generates physically reproducible adversarial 3D transformation (Adv-3DT) samples from single-view images. AdvDreamer integrates advanced generative techniques with two key innovations and aims to characterize the worst-case distributions of 3D variations from natural images. To ensure adversarial effectiveness and method generality, we introduce an Inverse Semantic Probability Objective that executes adversarial optimization on fundamental vision-text alignment spaces, which can be generalizable across different VLM architectures and downstream tasks. To mitigate the distribution discrepancy between generated and real-world samples while maintaining physical reproducibility, we design a Naturalness Reward Model that provides regularization feedback during adversarial optimization, preventing convergence towards hallucinated and unnatural elements. Leveraging AdvDreamer, we establish MM3DTBench, the first VQA dataset for benchmarking VLMs' 3D variations robustness. Extensive evaluations on representative VLMs with diverse architectures highlight that 3D variations in the real world may pose severe threats to model performance across various tasks.