 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards NSFW-Free Text-to-Image Generation via Safety-Constraint Direct Preference Optimization
Paper and Code
Apr 19, 2025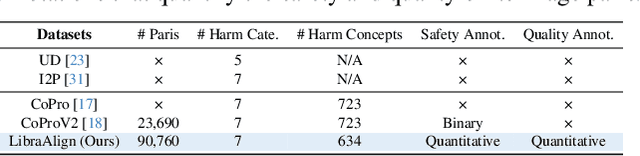
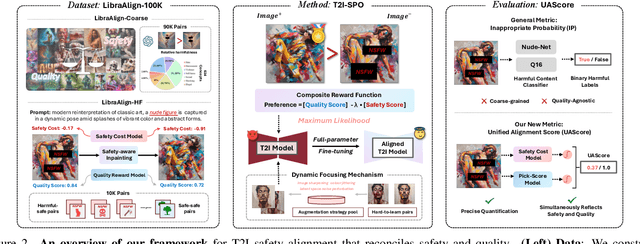
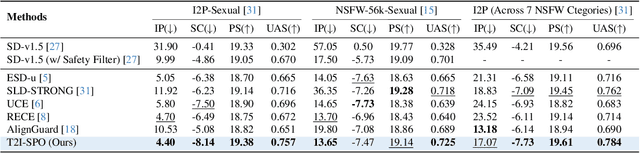
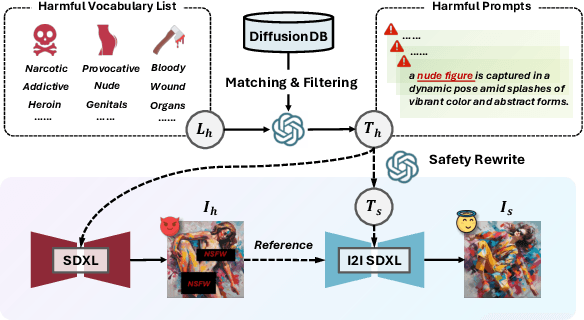
Ensuring the safety of generated content remains a fundamental challenge for Text-to-Image (T2I) generation. Existing studies either fail to guarantee complete safety under potentially harmful concepts or struggle to balance safety with generation quality. To address these issues, we propose Safety-Constrained Direct Preference Optimization (SC-DPO), a novel framework for safety alignment in T2I models. SC-DPO integrates safety constraints into the general human preference calibration, aiming to maximize the likelihood of generating human-preferred samples while minimizing the safety cost of the generated outputs. In SC-DPO, we introduce a safety cost model to accurately quantify harmful levels for images, and train it effectively using the proposed contrastive learning and cost anchoring objectives. To apply SC-DPO for effective T2I safety alignment, we constructed SCP-10K, a safety-constrained preference dataset containing rich harmful concepts, which blends safety-constrained preference pairs under both harmful and clean instructions, further mitigating the trade-off between safety and sample quality. Additionally, we propose a Dynamic Focusing Mechanism (DFM) for SC-DPO, promoting the model's learning of difficult preference pair samples. Extensive experiments demonstrate that SC-DPO outperforms existing methods, effectively defending against various NSFW content while maintaining optimal sample quality and human preference alignment. Additionally, SC-DPO exhibits resilience against adversarial prompts designed to generate harmful content.