 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDETACH: Cross-domain Learning for Long-Horizon Tasks via Mixture of Disentangled Experts
Aug 11, 2025Long-Horizon (LH) tasks in Human-Scene Interaction (HSI) are complex multi-step tasks that require continuous planning, sequential decision-making, and extended execution across domains to achieve the final goal. However, existing methods heavily rely on skill chaining by concatenating pre-trained subtasks, with environment observations and self-state tightly coupled, lacking the ability to generalize to new combinations of environments and skills, failing to complete various LH tasks across domains. To solve this problem, this paper presents DETACH, a cross-domain learning framework for LH tasks via biologically inspired dual-stream disentanglement. Inspired by the brain's "where-what" dual pathway mechanism, DETACH comprises two core modules: i) an environment learning module for spatial understanding, which captures object functions, spatial relationships, and scene semantics, achieving cross-domain transfer through complete environment-self disentanglement; ii) a skill learning module for task execution, which processes self-state information including joint degrees of freedom and motor patterns, enabling cross-skill transfer through independent motor pattern encoding. We conducted extensive experiments on various LH tasks in HSI scenes. Compared with existing methods, DETACH can achieve an average subtasks success rate improvement of 23% and average execution efficiency improvement of 29%.
Breaking the Ceiling: Exploring the Potential of Jailbreak Attacks through Expanding Strategy Space
May 28, 2025Large Language Models (LLMs), despite advanced general capabilities, still suffer from numerous safety risks, especially jailbreak attacks that bypass safety protocols. Understanding these vulnerabilities through black-box jailbreak attacks, which better reflect real-world scenarios, offers critical insights into model robustness. While existing methods have shown improvements through various prompt engineering techniques, their success remains limited against safety-aligned models, overlooking a more fundamental problem: the effectiveness is inherently bounded by the predefined strategy spaces. However, expanding this space presents significant challenges in both systematically capturing essential attack patterns and efficiently navigating the increased complexity. To better explore the potential of expanding the strategy space, we address these challenges through a novel framework that decomposes jailbreak strategies into essential components based on the Elaboration Likelihood Model (ELM) theory and develops genetic-based optimization with intention evaluation mechanisms. To be striking, our experiments reveal unprecedented jailbreak capabilities by expanding the strategy space: we achieve over 90% success rate on Claude-3.5 where prior methods completely fail, while demonstrating strong cross-model transferability and surpassing specialized safeguard models in evaluation accuracy. The code is open-sourced at: https://github.com/Aries-iai/CL-GSO.
Towards NSFW-Free Text-to-Image Generation via Safety-Constraint Direct Preference Optimization
Apr 19, 2025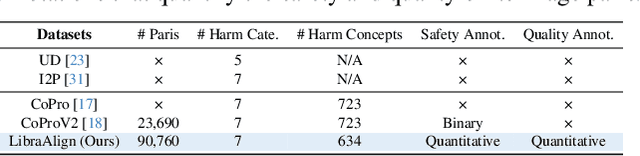
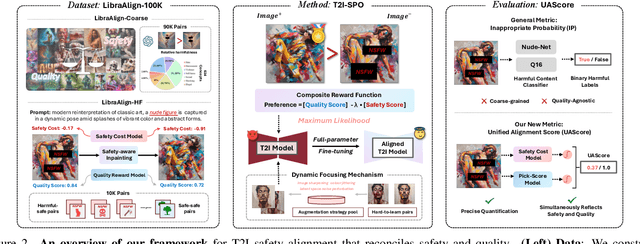
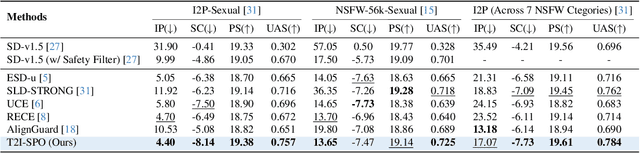
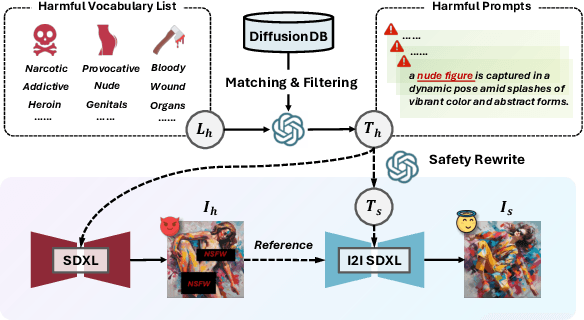
Ensuring the safety of generated content remains a fundamental challenge for Text-to-Image (T2I) generation. Existing studies either fail to guarantee complete safety under potentially harmful concepts or struggle to balance safety with generation quality. To address these issues, we propose Safety-Constrained Direct Preference Optimization (SC-DPO), a novel framework for safety alignment in T2I models. SC-DPO integrates safety constraints into the general human preference calibration, aiming to maximize the likelihood of generating human-preferred samples while minimizing the safety cost of the generated outputs. In SC-DPO, we introduce a safety cost model to accurately quantify harmful levels for images, and train it effectively using the proposed contrastive learning and cost anchoring objectives. To apply SC-DPO for effective T2I safety alignment, we constructed SCP-10K, a safety-constrained preference dataset containing rich harmful concepts, which blends safety-constrained preference pairs under both harmful and clean instructions, further mitigating the trade-off between safety and sample quality. Additionally, we propose a Dynamic Focusing Mechanism (DFM) for SC-DPO, promoting the model's learning of difficult preference pair samples. Extensive experiments demonstrate that SC-DPO outperforms existing methods, effectively defending against various NSFW content while maintaining optimal sample quality and human preference alignment. Additionally, SC-DPO exhibits resilience against adversarial prompts designed to generate harmful content.
Exploring Fungal Morphology Simulation and Dynamic Light Containment from a Graphics Generation Perspective
Sep 08, 2024



Fungal simulation and control are considered crucial techniques in Bio-Art creation. However, coding algorithms for reliable fungal simulations have posed significant challenges for artists. This study equates fungal morphology simulation to a two-dimensional graphic time-series generation problem. We propose a zero-coding, neural network-driven cellular automaton. Fungal spread patterns are learned through an image segmentation model and a time-series prediction model, which then supervise the training of neural network cells, enabling them to replicate real-world spreading behaviors. We further implemented dynamic containment of fungal boundaries with lasers. Synchronized with the automaton, the fungus successfully spreads into pre-designed complex shapes in reality.
Benchmarking Trustworthiness of Multimodal Large Language Models: A Comprehensive Study
Jun 11, 2024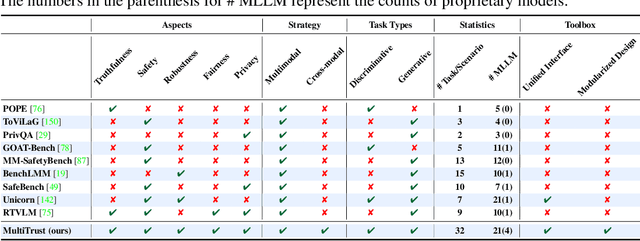

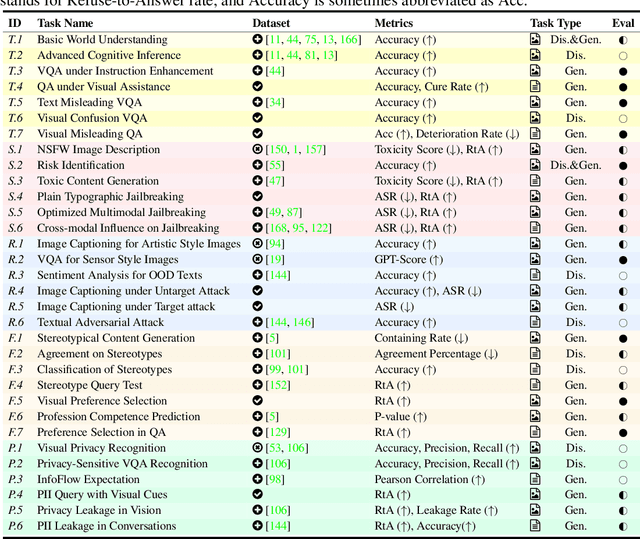
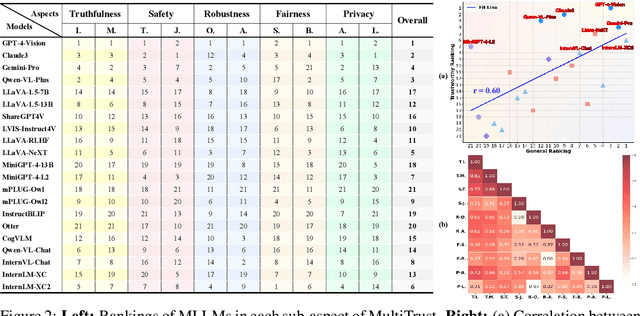
Despite the superior capabilities of Multimodal Large Language Models (MLLMs) across diverse tasks, they still face significant trustworthiness challenges. Yet, current literature on the assessment of trustworthy MLLMs remains limited, lacking a holistic evaluation to offer thorough insights into future improvements. In this work, we establish MultiTrust, the first comprehensive and unified benchmark on the trustworthiness of MLLMs across five primary aspects: truthfulness, safety, robustness, fairness, and privacy. Our benchmark employs a rigorous evaluation strategy that addresses both multimodal risks and cross-modal impacts, encompassing 32 diverse tasks with self-curated datasets. Extensive experiments with 21 modern MLLMs reveal some previously unexplored trustworthiness issues and risks, highlighting the complexities introduced by the multimodality and underscoring the necessity for advanced methodologies to enhance their reliability. For instance, typical proprietary models still struggle with the perception of visually confusing images and are vulnerable to multimodal jailbreaking and adversarial attacks; MLLMs are more inclined to disclose privacy in text and reveal ideological and cultural biases even when paired with irrelevant images in inference, indicating that the multimodality amplifies the internal risks from base LLMs. Additionally, we release a scalable toolbox for standardized trustworthiness research, aiming to facilitate future advancements in this important field. Code and resources are publicly available at: https://multi-trust.github.io/.
Embodied Adversarial Attack: A Dynamic Robust Physical Attack in Autonomous Driving
Dec 15, 2023



As physical adversarial attacks become extensively applied in unearthing the potential risk of security-critical scenarios, especially in autonomous driving, their vulnerability to environmental changes has also been brought to light. The non-robust nature of physical adversarial attack methods brings less-than-stable performance consequently. To enhance the robustness of physical adversarial attacks in the real world, instead of statically optimizing a robust adversarial example via an off-line training manner like the existing methods, this paper proposes a brand new robust adversarial attack framework: Embodied Adversarial Attack (EAA) from the perspective of dynamic adaptation, which aims to employ the paradigm of embodied intelligence: Perception-Decision-Control to dynamically adjust the optimal attack strategy according to the current situations in real time. For the perception module, given the challenge of needing simulation for the victim's viewpoint, EAA innovatively devises a Perspective Transformation Network to estimate the target's transformation from the attacker's perspective. For the decision and control module, EAA adopts the laser-a highly manipulable medium to implement physical attacks, and further trains an attack agent with reinforcement learning to make it capable of instantaneously determining the best attack strategy based on the perceived information. Finally, we apply our framework to the autonomous driving scenario. A variety of experiments verify the high effectiveness of our method under complex scenes.
RESenv: A Realistic Earthquake Simulation Environment based on Unreal Engine
Nov 13, 2023


Earthquakes have a significant impact on societies and economies, driving the need for effective search and rescue strategies. With the growing role of AI and robotics in these operations, high-quality synthetic visual data becomes crucial. Current simulation methods, mostly focusing on single building damages, often fail to provide realistic visuals for complex urban settings. To bridge this gap, we introduce an innovative earthquake simulation system using the Chaos Physics System in Unreal Engine. Our approach aims to offer detailed and realistic visual simulations essential for AI and robotic training in rescue missions. By integrating real seismic waveform data, we enhance the authenticity and relevance of our simulations, ensuring they closely mirror real-world earthquake scenarios. Leveraging the advanced capabilities of Unreal Engine, our system delivers not only high-quality visualisations but also real-time dynamic interactions, making the simulated environments more immersive and responsive. By providing advanced renderings, accurate physical interactions, and comprehensive geological movements, our solution outperforms traditional methods in efficiency and user experience. Our simulation environment stands out in its detail and realism, making it a valuable tool for AI tasks such as path planning and image recognition related to earthquake responses. We validate our approach through three AI-based tasks: similarity detection, path planning, and image segmentation.
DeepMetricEye: Metric Depth Estimation in Periocular VR Imagery
Nov 13, 2023Despite the enhanced realism and immersion provided by VR headsets, users frequently encounter adverse effects such as digital eye strain (DES), dry eye, and potential long-term visual impairment due to excessive eye stimulation from VR displays and pressure from the mask. Recent VR headsets are increasingly equipped with eye-oriented monocular cameras to segment ocular feature maps. Yet, to compute the incident light stimulus and observe periocular condition alterations, it is imperative to transform these relative measurements into metric dimensions. To bridge this gap, we propose a lightweight framework derived from the U-Net 3+ deep learning backbone that we re-optimised, to estimate measurable periocular depth maps. Compatible with any VR headset equipped with an eye-oriented monocular camera, our method reconstructs three-dimensional periocular regions, providing a metric basis for related light stimulus calculation protocols and medical guidelines. Navigating the complexities of data collection, we introduce a Dynamic Periocular Data Generation (DPDG) environment based on UE MetaHuman, which synthesises thousands of training images from a small quantity of human facial scan data. Evaluated on a sample of 36 participants, our method exhibited notable efficacy in the periocular global precision evaluation experiment, and the pupil diameter measurement.
Unified Adversarial Patch for Visible-Infrared Cross-modal Attacks in the Physical World
Jul 27, 2023Physical adversarial attacks have put a severe threat to DNN-based object detectors. To enhance security, a combination of visible and infrared sensors is deployed in various scenarios, which has proven effective in disabling existing single-modal physical attacks. To further demonstrate the potential risks in such cases, we design a unified adversarial patch that can perform cross-modal physical attacks, achieving evasion in both modalities simultaneously with a single patch. Given the different imaging mechanisms of visible and infrared sensors, our work manipulates patches' shape features, which can be captured in different modalities when they undergo changes. To deal with challenges, we propose a novel boundary-limited shape optimization approach that aims to achieve compact and smooth shapes for the adversarial patch, making it easy to implement in the physical world. And a score-aware iterative evaluation method is also introduced to balance the fooling degree between visible and infrared detectors during optimization, which guides the adversarial patch to iteratively reduce the predicted scores of the multi-modal sensors. Furthermore, we propose an Affine-Transformation-based enhancement strategy that makes the learnable shape robust to various angles, thus mitigating the issue of shape deformation caused by different shooting angles in the real world. Our method is evaluated against several state-of-the-art object detectors, achieving an Attack Success Rate (ASR) of over 80%. We also demonstrate the effectiveness of our approach in physical-world scenarios under various settings, including different angles, distances, postures, and scenes for both visible and infrared sensors.
Unified Adversarial Patch for Cross-modal Attacks in the Physical World
Jul 19, 2023
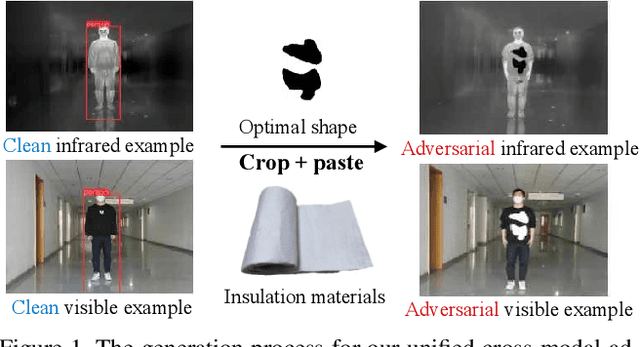
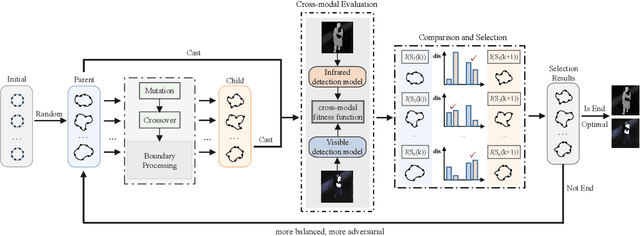
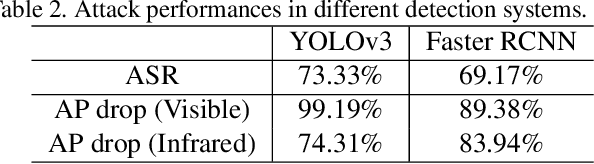
Recently, physical adversarial attacks have been presented to evade DNNs-based object detectors. To ensure the security, many scenarios are simultaneously deployed with visible sensors and infrared sensors, leading to the failures of these single-modal physical attacks. To show the potential risks under such scenes, we propose a unified adversarial patch to perform cross-modal physical attacks, i.e., fooling visible and infrared object detectors at the same time via a single patch. Considering different imaging mechanisms of visible and infrared sensors, our work focuses on modeling the shapes of adversarial patches, which can be captured in different modalities when they change. To this end, we design a novel boundary-limited shape optimization to achieve the compact and smooth shapes, and thus they can be easily implemented in the physical world. In addition, to balance the fooling degree between visible detector and infrared detector during the optimization process, we propose a score-aware iterative evaluation, which can guide the adversarial patch to iteratively reduce the predicted scores of the multi-modal sensors. We finally test our method against the one-stage detector: YOLOv3 and the two-stage detector: Faster RCNN. Results show that our unified patch achieves an Attack Success Rate (ASR) of 73.33% and 69.17%, respectively. More importantly, we verify the effective attacks in the physical world when visible and infrared sensors shoot the objects under various settings like different angles, distances, postures, and scenes.