 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMESA: Improving MoE Safety Alignment via Decentralized Expertise
May 30, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models (LLMs) efficiently, enabling greater capacity with reduced computational cost by dynamically routing inputs to relevant experts, yet introduce a critical vulnerability: Safety Sparsity, where safety capabilities concentrate in few experts, making them susceptible to adversarial bypassing. Meanwhile, conventional alignment methods uniformly adapt all parameters, ignoring their functional differences and inadvertently degrading performances. To address these challenges, we propose MESA (MoE Safety Alignment), a targeted alignment framework for MoE-based LLMs that strategically decentralizes safety responsibility to maximize coverage while minimizing interference with utility. Based on Optimal Transport (OT) theory, MESA operates through two mechanisms: (1) Expert Capacity Reallocation uses a transport cost matrix to distribute safety duties to the most cost-effective experts, and (2) Dynamic Routing Refinement constrains the router to precisely activate these decentralized modules. Experiments show that MESA achieves robust defensive performance against varied harmful benchmarks while preserving helpfulness. Code is available at https://github.com/lorraine021/MESA.
Knowledge-Guided Adversarial Training for Infrared Object Detection via Thermal Radiation Modeling
Mar 26, 2026In complex environments, infrared object detection exhibits broad applicability and stability across diverse scenarios. However, infrared object detection is vulnerable to both common corruptions and adversarial examples, leading to potential security risks. To improve the robustness of infrared object detection, current methods mostly adopt a data-driven ideology, which only superficially drives the network to fit the training data without specifically considering the unique characteristics of infrared images, resulting in limited robustness. In this paper, we revisit infrared physical knowledge and find that relative thermal radiation relations between different classes can be regarded as a reliable knowledge source under the complex scenarios of adversarial examples and common corruptions. Thus, we theoretically model thermal radiation relations based on the rank order of gray values for different classes, and further quantify the stability of various inter-class thermal radiation relations. Based on the above theoretical framework, we propose Knowledge-Guided Adversarial Training (KGAT) for infrared object detection, in which infrared physical knowledge is embedded into the adversarial training process, and the predicted results are optimized to be consistent with the actual physical laws. Extensive experiments on three infrared datasets and six mainstream infrared object detection models demonstrate that KGAT effectively enhances both clean accuracy and robustness against adversarial attacks and common corruptions.
Mind over Space: Can Multimodal Large Language Models Mentally Navigate?
Mar 23, 2026Despite the widespread adoption of MLLMs in embodied agents, their capabilities remain largely confined to reactive planning from immediate observations, consistently failing in spatial reasoning across extensive spatiotemporal scales. Cognitive science reveals that Biological Intelligence (BI) thrives on "mental navigation": the strategic construction of spatial representations from experience and the subsequent mental simulation of paths prior to action. To bridge the gap between AI and BI, we introduce Video2Mental, a pioneering benchmark for evaluating the mental navigation capabilities of MLLMs. The task requires constructing hierarchical cognitive maps from long egocentric videos and generating landmark-based path plans step by step, with planning accuracy verified through simulator-based physical interaction. Our benchmarking results reveal that mental navigation capability does not naturally emerge from standard pre-training. Frontier MLLMs struggle profoundly with zero-shot structured spatial representation, and their planning accuracy decays precipitously over extended horizons. To overcome this, we propose \textbf{NavMind}, a reasoning model that internalizes mental navigation using explicit, fine-grained cognitive maps as learnable intermediate representations. Through a difficulty-stratified progressive supervised fine-tuning paradigm, NavMind effectively bridges the gap between raw perception and structured planning. Experiments demonstrate that NavMind achieves superior mental navigation capabilities, significantly outperforming frontier commercial and spatial MLLMs.
Breaking Self-Attention Failure: Rethinking Query Initialization for Infrared Small Target Detection
Jan 06, 2026Infrared small target detection (IRSTD) faces significant challenges due to the low signal-to-noise ratio (SNR), small target size, and complex cluttered backgrounds. Although recent DETR-based detectors benefit from global context modeling, they exhibit notable performance degradation on IRSTD. We revisit this phenomenon and reveal that the target-relevant embeddings of IRST are inevitably overwhelmed by dominant background features due to the self-attention mechanism, leading to unreliable query initialization and inaccurate target localization. To address this issue, we propose SEF-DETR, a novel framework that refines query initialization for IRSTD. Specifically, SEF-DETR consists of three components: Frequency-guided Patch Screening (FPS), Dynamic Embedding Enhancement (DEE), and Reliability-Consistency-aware Fusion (RCF). The FPS module leverages the Fourier spectrum of local patches to construct a target-relevant density map, suppressing background-dominated features. DEE strengthens multi-scale representations in a target-aware manner, while RCF further refines object queries by enforcing spatial-frequency consistency and reliability. Extensive experiments on three public IRSTD datasets demonstrate that SEF-DETR achieves superior detection performance compared to state-of-the-art methods, delivering a robust and efficient solution for infrared small target detection task.
RGBT-Ground Benchmark: Visual Grounding Beyond RGB in Complex Real-World Scenarios
Dec 31, 2025Visual Grounding (VG) aims to localize specific objects in an image according to natural language expressions, serving as a fundamental task in vision-language understanding. However, existing VG benchmarks are mostly derived from datasets collected under clean environments, such as COCO, where scene diversity is limited. Consequently, they fail to reflect the complexity of real-world conditions, such as changes in illumination, weather, etc., that are critical to evaluating model robustness and generalization in safety-critical applications. To address these limitations, we present RGBT-Ground, the first large-scale visual grounding benchmark built for complex real-world scenarios. It consists of spatially aligned RGB and Thermal infrared (TIR) image pairs with high-quality referring expressions, corresponding object bounding boxes, and fine-grained annotations at the scene, environment, and object levels. This benchmark enables comprehensive evaluation and facilitates the study of robust grounding under diverse and challenging conditions. Furthermore, we establish a unified visual grounding framework that supports both uni-modal (RGB or TIR) and multi-modal (RGB-TIR) visual inputs. Based on it, we propose RGBT-VGNet, a simple yet effective baseline for fusing complementary visual modalities to achieve robust grounding. We conduct extensive adaptations to the existing methods on RGBT-Ground. Experimental results show that our proposed RGBT-VGNet significantly outperforms these adapted methods, particularly in nighttime and long-distance scenarios. All resources will be publicly released to promote future research on robust visual grounding in complex real-world environments.
From reactive to cognitive: brain-inspired spatial intelligence for embodied agents
Aug 24, 2025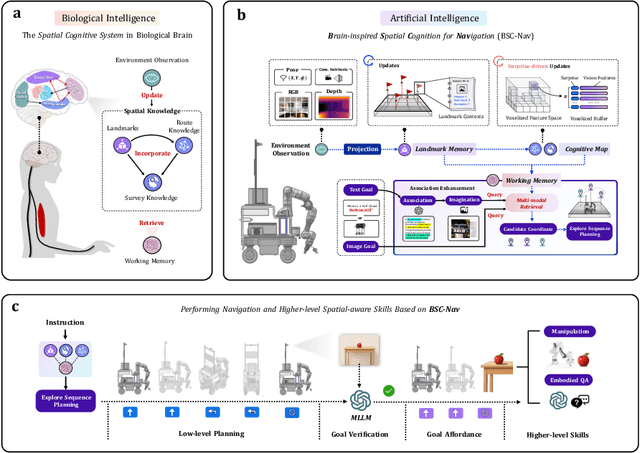
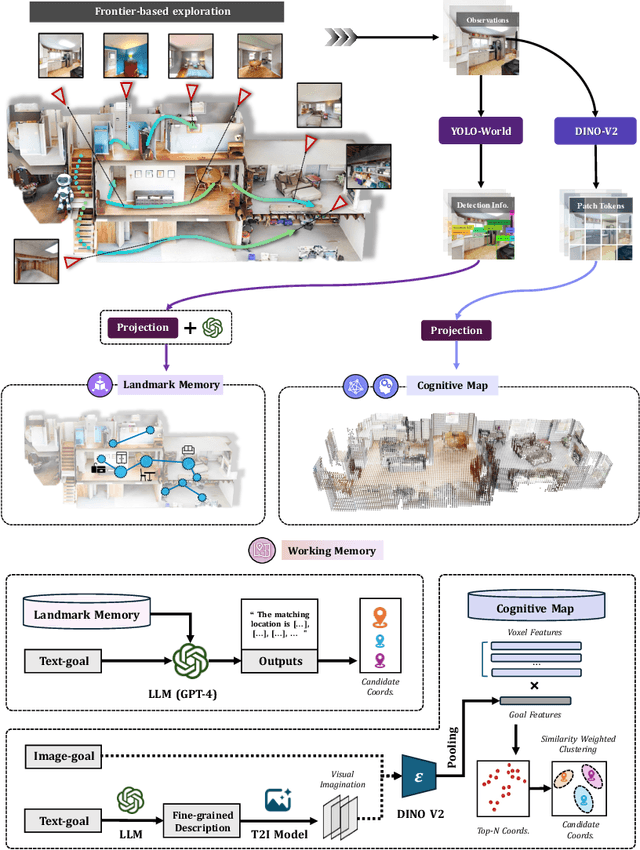
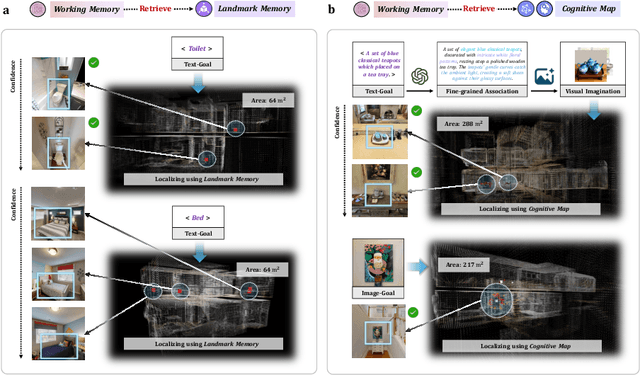
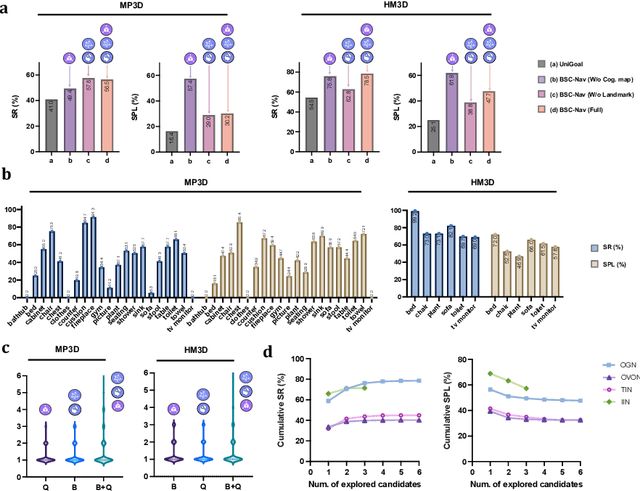
Spatial cognition enables adaptive goal-directed behavior by constructing internal models of space. Robust biological systems consolidate spatial knowledge into three interconnected forms: \textit{landmarks} for salient cues, \textit{route knowledge} for movement trajectories, and \textit{survey knowledge} for map-like representations. While recent advances in multi-modal large language models (MLLMs) have enabled visual-language reasoning in embodied agents, these efforts lack structured spatial memory and instead operate reactively, limiting their generalization and adaptability in complex real-world environments. Here we present Brain-inspired Spatial Cognition for Navigation (BSC-Nav), a unified framework for constructing and leveraging structured spatial memory in embodied agents. BSC-Nav builds allocentric cognitive maps from egocentric trajectories and contextual cues, and dynamically retrieves spatial knowledge aligned with semantic goals. Integrated with powerful MLLMs, BSC-Nav achieves state-of-the-art efficacy and efficiency across diverse navigation tasks, demonstrates strong zero-shot generalization, and supports versatile embodied behaviors in the real physical world, offering a scalable and biologically grounded path toward general-purpose spatial intelligence.
NS-FPN: Improving Infrared Small Target Detection and Segmentation from Noise Suppression Perspective
Aug 09, 2025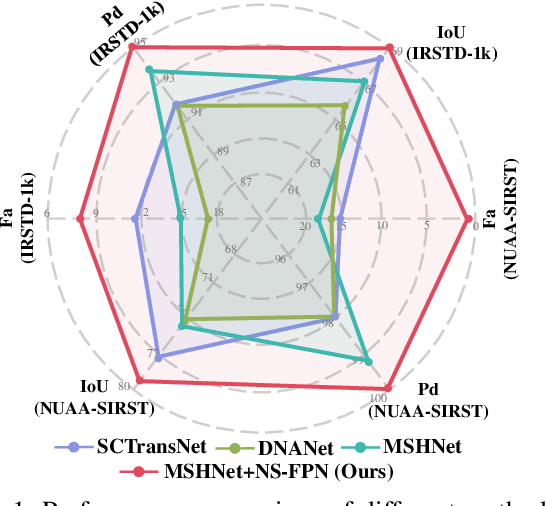

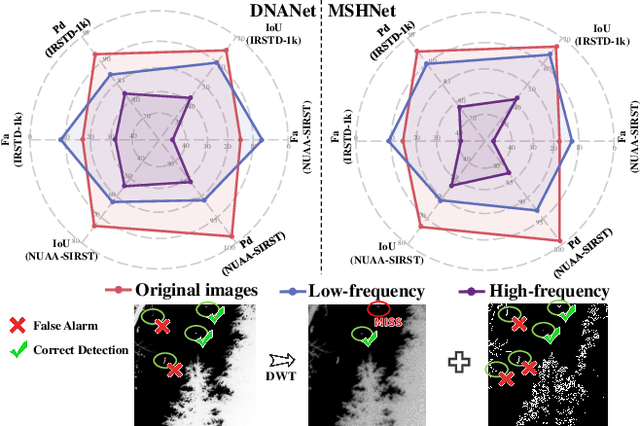
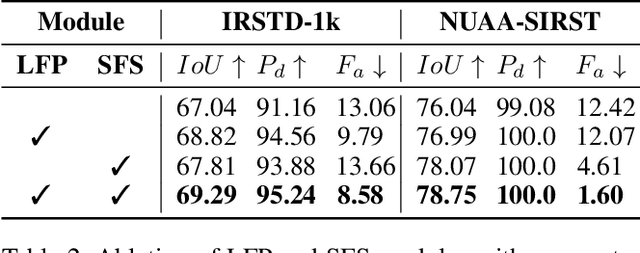
Infrared small target detection and segmentation (IRSTDS) is a critical yet challenging task in defense and civilian applications, owing to the dim, shapeless appearance of targets and severe background clutter. Recent CNN-based methods have achieved promising target perception results, but they only focus on enhancing feature representation to offset the impact of noise, which results in the increased false alarms problem. In this paper, through analyzing the problem from the frequency domain, we pioneer in improving performance from noise suppression perspective and propose a novel noise-suppression feature pyramid network (NS-FPN), which integrates a low-frequency guided feature purification (LFP) module and a spiral-aware feature sampling (SFS) module into the original FPN structure. The LFP module suppresses the noise features by purifying high-frequency components to achieve feature enhancement devoid of noise interference, while the SFS module further adopts spiral sampling to fuse target-relevant features in feature fusion process. Our NS-FPN is designed to be lightweight yet effective and can be easily plugged into existing IRSTDS frameworks. Extensive experiments on the public IRSTDS datasets demonstrate that our method significantly reduces false alarms and achieves superior performance on IRSTDS tasks.
Towards Class-wise Fair Adversarial Training via Anti-Bias Soft Label Distillation
Jun 10, 2025Adversarial Training (AT) is widely recognized as an effective approach to enhance the adversarial robustness of Deep Neural Networks. As a variant of AT, Adversarial Robustness Distillation (ARD) has shown outstanding performance in enhancing the robustness of small models. However, both AT and ARD face robust fairness issue: these models tend to display strong adversarial robustness against some classes (easy classes) while demonstrating weak adversarial robustness against others (hard classes). This paper explores the underlying factors of this problem and points out the smoothness degree of soft labels for different classes significantly impacts the robust fairness from both empirical observation and theoretical analysis. Based on the above exploration, we propose Anti-Bias Soft Label Distillation (ABSLD) within the Knowledge Distillation framework to enhance the adversarial robust fairness. Specifically, ABSLD adaptively reduces the student's error risk gap between different classes, which is accomplished by adjusting the class-wise smoothness degree of teacher's soft labels during the training process, and the adjustment is managed by assigning varying temperatures to different classes. Additionally, as a label-based approach, ABSLD is highly adaptable and can be integrated with the sample-based methods. Extensive experiments demonstrate ABSLD outperforms state-of-the-art methods on the comprehensive performance of robustness and fairness.
Breaking the Ceiling: Exploring the Potential of Jailbreak Attacks through Expanding Strategy Space
May 28, 2025Large Language Models (LLMs), despite advanced general capabilities, still suffer from numerous safety risks, especially jailbreak attacks that bypass safety protocols. Understanding these vulnerabilities through black-box jailbreak attacks, which better reflect real-world scenarios, offers critical insights into model robustness. While existing methods have shown improvements through various prompt engineering techniques, their success remains limited against safety-aligned models, overlooking a more fundamental problem: the effectiveness is inherently bounded by the predefined strategy spaces. However, expanding this space presents significant challenges in both systematically capturing essential attack patterns and efficiently navigating the increased complexity. To better explore the potential of expanding the strategy space, we address these challenges through a novel framework that decomposes jailbreak strategies into essential components based on the Elaboration Likelihood Model (ELM) theory and develops genetic-based optimization with intention evaluation mechanisms. To be striking, our experiments reveal unprecedented jailbreak capabilities by expanding the strategy space: we achieve over 90% success rate on Claude-3.5 where prior methods completely fail, while demonstrating strong cross-model transferability and surpassing specialized safeguard models in evaluation accuracy. The code is open-sourced at: https://github.com/Aries-iai/CL-GSO.
Mitigating Overthinking in Large Reasoning Models via Manifold Steering
May 28, 2025Recent advances in Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in solving complex tasks such as mathematics and coding. However, these models frequently exhibit a phenomenon known as overthinking during inference, characterized by excessive validation loops and redundant deliberation, leading to substantial computational overheads. In this paper, we aim to mitigate overthinking by investigating the underlying mechanisms from the perspective of mechanistic interpretability. We first showcase that the tendency of overthinking can be effectively captured by a single direction in the model's activation space and the issue can be eased by intervening the activations along this direction. However, this efficacy soon reaches a plateau and even deteriorates as the intervention strength increases. We therefore systematically explore the activation space and find that the overthinking phenomenon is actually tied to a low-dimensional manifold, which indicates that the limited effect stems from the noises introduced by the high-dimensional steering direction. Based on this insight, we propose Manifold Steering, a novel approach that elegantly projects the steering direction onto the low-dimensional activation manifold given the theoretical approximation of the interference noise. Extensive experiments on DeepSeek-R1 distilled models validate that our method reduces output tokens by up to 71% while maintaining and even improving the accuracy on several mathematical benchmarks. Our method also exhibits robust cross-domain transferability, delivering consistent token reduction performance in code generation and knowledge-based QA tasks. Code is available at: https://github.com/Aries-iai/Manifold_Steering.