 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvDreamer Unveils: Are Vision-Language Models Truly Ready for Real-World 3D Variations?
Dec 04, 2024
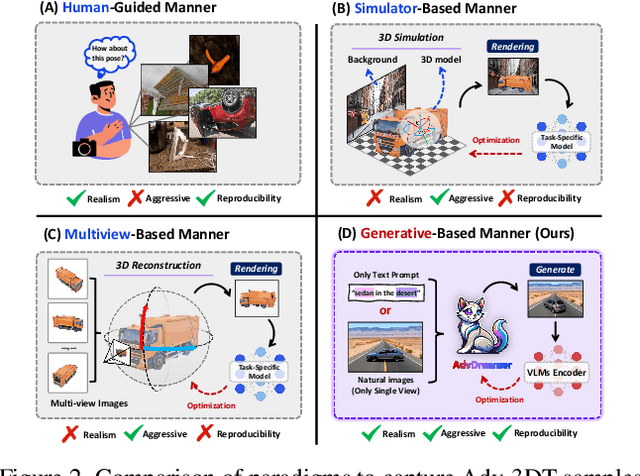
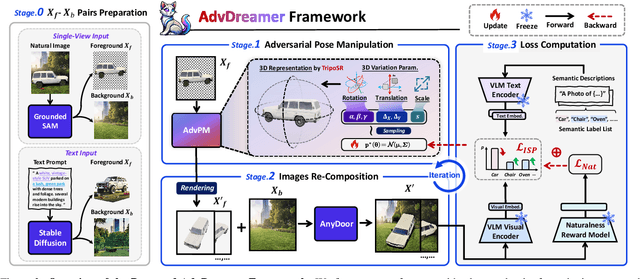
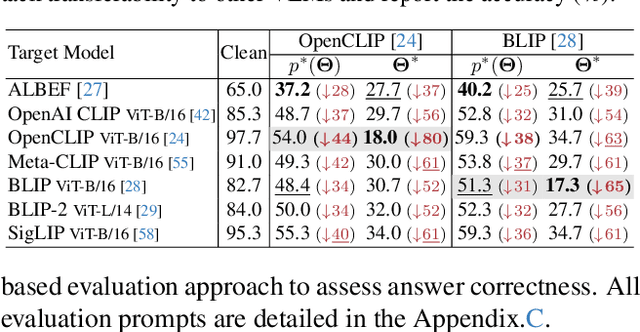
Vision Language Models (VLMs) have exhibited remarkable generalization capabilities, yet their robustness in dynamic real-world scenarios remains largely unexplored. To systematically evaluate VLMs' robustness to real-world 3D variations, we propose AdvDreamer, the first framework that generates physically reproducible adversarial 3D transformation (Adv-3DT) samples from single-view images. AdvDreamer integrates advanced generative techniques with two key innovations and aims to characterize the worst-case distributions of 3D variations from natural images. To ensure adversarial effectiveness and method generality, we introduce an Inverse Semantic Probability Objective that executes adversarial optimization on fundamental vision-text alignment spaces, which can be generalizable across different VLM architectures and downstream tasks. To mitigate the distribution discrepancy between generated and real-world samples while maintaining physical reproducibility, we design a Naturalness Reward Model that provides regularization feedback during adversarial optimization, preventing convergence towards hallucinated and unnatural elements. Leveraging AdvDreamer, we establish MM3DTBench, the first VQA dataset for benchmarking VLMs' 3D variations robustness. Extensive evaluations on representative VLMs with diverse architectures highlight that 3D variations in the real world may pose severe threats to model performance across various tasks.