 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Circuit-Based Knowledge Editing in Large Language Models
Apr 07, 2026Deploying Large Language Models (LLMs) in real-world dynamic environments raises the challenge of updating their pre-trained knowledge. While existing knowledge editing methods can reliably patch isolated facts, they frequently suffer from a "Reasoning Gap", where the model recalls the edited fact but fails to utilize it in multi-step reasoning chains. To bridge this gap, we introduce MCircKE (\underline{M}echanistic \underline{Circ}uit-based \underline{K}nowledge \underline{E}diting), a novel framework that enables a precise "map-and-adapt" editing procedure. MCircKE first identifies the causal circuits responsible for a specific reasoning task, capturing both the storage of the fact and the routing of its logical consequences. It then surgically update parameters exclusively within this mapped circuit. Extensive experiments on the MQuAKE-3K benchmark demonstrate the effectiveness of the proposed method for multi-hop reasoning in knowledge editing.
Wired for Overconfidence: A Mechanistic Perspective on Inflated Verbalized Confidence in LLMs
Apr 01, 2026Large language models are often not just wrong, but \emph{confidently wrong}: when they produce factually incorrect answers, they tend to verbalize overly high confidence rather than signal uncertainty. Such verbalized overconfidence can mislead users and weaken confidence scores as a reliable uncertainty signal, yet its internal mechanisms remain poorly understood. We present a circuit-level mechanistic analysis of this inflated verbalized confidence in LLMs, organized around three axes: capturing verbalized confidence as a differentiable internal signal, identifying the circuits that causally inflate it, and leveraging these insights for targeted inference-time recalibration. Across two instruction-tuned LLMs on three datasets, we find that a compact set of MLP blocks and attention heads, concentrated in middle-to-late layers, consistently writes the confidence-inflation signal at the final token position. We further show that targeted inference-time interventions on these circuits substantially improve calibration. Together, our results suggest that verbalized overconfidence in LLMs is driven by identifiable internal circuits and can be mitigated through targeted intervention.
An Empirical Study of World Model Quantization
Feb 02, 2026World models learn an internal representation of environment dynamics, enabling agents to simulate and reason about future states within a compact latent space for tasks such as planning, prediction, and inference. However, running world models rely on hevay computational cost and memory footprint, making model quantization essential for efficient deployment. To date, the effects of post-training quantization (PTQ) on world models remain largely unexamined. In this work, we present a systematic empirical study of world model quantization using DINO-WM as a representative case, evaluating diverse PTQ methods under both weight-only and joint weight-activation settings. We conduct extensive experiments on different visual planning tasks across a wide range of bit-widths, quantization granularities, and planning horizons up to 50 iterations. Our results show that quantization effects in world models extend beyond standard accuracy and bit-width trade-offs: group-wise weight quantization can stabilize low-bit rollouts, activation quantization granularity yields inconsistent benefits, and quantization sensitivity is highly asymmetric between encoder and predictor modules. Moreover, aggressive low-bit quantization significantly degrades the alignment between the planning objective and task success, leading to failures that cannot be remedied by additional optimization. These findings reveal distinct quantization-induced failure modes in world model-based planning and provide practical guidance for deploying quantized world models under strict computational constraints. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/QuantWM.
RGBT-Ground Benchmark: Visual Grounding Beyond RGB in Complex Real-World Scenarios
Dec 31, 2025Visual Grounding (VG) aims to localize specific objects in an image according to natural language expressions, serving as a fundamental task in vision-language understanding. However, existing VG benchmarks are mostly derived from datasets collected under clean environments, such as COCO, where scene diversity is limited. Consequently, they fail to reflect the complexity of real-world conditions, such as changes in illumination, weather, etc., that are critical to evaluating model robustness and generalization in safety-critical applications. To address these limitations, we present RGBT-Ground, the first large-scale visual grounding benchmark built for complex real-world scenarios. It consists of spatially aligned RGB and Thermal infrared (TIR) image pairs with high-quality referring expressions, corresponding object bounding boxes, and fine-grained annotations at the scene, environment, and object levels. This benchmark enables comprehensive evaluation and facilitates the study of robust grounding under diverse and challenging conditions. Furthermore, we establish a unified visual grounding framework that supports both uni-modal (RGB or TIR) and multi-modal (RGB-TIR) visual inputs. Based on it, we propose RGBT-VGNet, a simple yet effective baseline for fusing complementary visual modalities to achieve robust grounding. We conduct extensive adaptations to the existing methods on RGBT-Ground. Experimental results show that our proposed RGBT-VGNet significantly outperforms these adapted methods, particularly in nighttime and long-distance scenarios. All resources will be publicly released to promote future research on robust visual grounding in complex real-world environments.
Speculative Decoding in Decentralized LLM Inference: Turning Communication Latency into Computation Throughput
Nov 13, 2025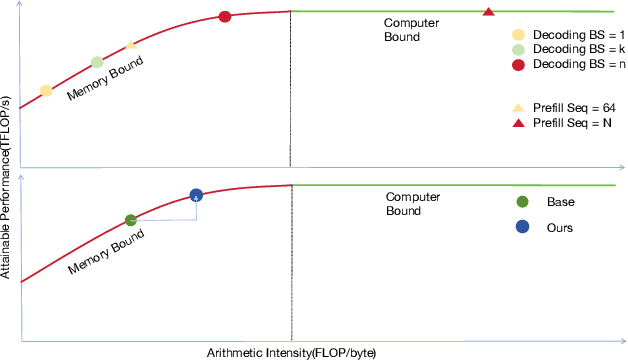
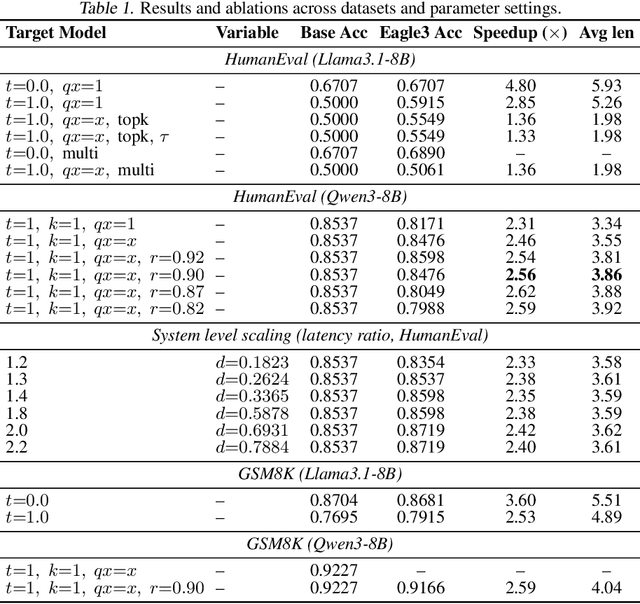

Speculative decoding accelerates large language model (LLM) inference by using a lightweight draft model to propose tokens that are later verified by a stronger target model. While effective in centralized systems, its behavior in decentralized settings, where network latency often dominates compute, remains under-characterized. We present Decentralized Speculative Decoding (DSD), a plug-and-play framework for decentralized inference that turns communication delay into useful computation by verifying multiple candidate tokens in parallel across distributed nodes. We further introduce an adaptive speculative verification strategy that adjusts acceptance thresholds by token-level semantic importance, delivering an additional 15% to 20% end-to-end speedup without retraining. In theory, DSD reduces cross-node communication cost by approximately (N-1)t1(k-1)/k, where t1 is per-link latency and k is the average number of tokens accepted per round. In practice, DSD achieves up to 2.56x speedup on HumanEval and 2.59x on GSM8K, surpassing the Eagle3 baseline while preserving accuracy. These results show that adapting speculative decoding for decentralized execution provides a system-level optimization that converts network stalls into throughput, enabling faster distributed LLM inference with no model retraining or architectural changes.
Credence Calibration Game? Calibrating Large Language Models through Structured Play
Aug 20, 2025As Large Language Models (LLMs) are increasingly deployed in decision-critical domains, it becomes essential to ensure that their confidence estimates faithfully correspond to their actual correctness. Existing calibration methods have primarily focused on post-hoc adjustments or auxiliary model training; however, many of these approaches necessitate additional supervision or parameter updates. In this work, we propose a novel prompt-based calibration framework inspired by the Credence Calibration Game. Our method establishes a structured interaction loop wherein LLMs receive feedback based on the alignment of their predicted confidence with correctness. Through feedback-driven prompting and natural language summaries of prior performance, our framework dynamically improves model calibration. Extensive experiments across models and game configurations demonstrate consistent improvements in evaluation metrics. Our results highlight the potential of game-based prompting as an effective strategy for LLM calibration. Code and data are available at https://anonymous.4open.science/r/LLM-Calibration/.
NS-FPN: Improving Infrared Small Target Detection and Segmentation from Noise Suppression Perspective
Aug 09, 2025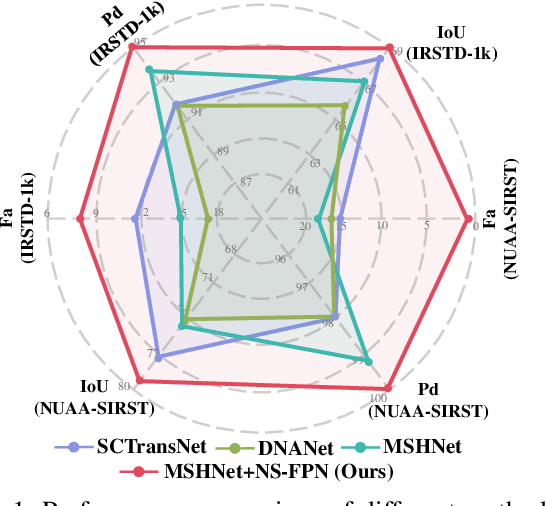

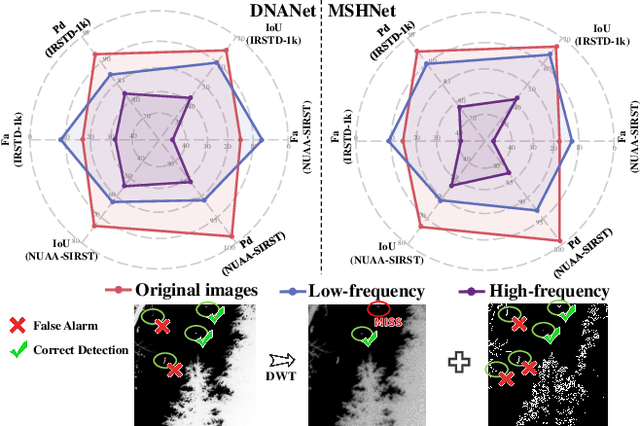
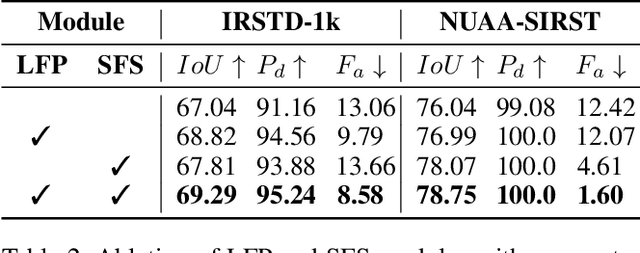
Infrared small target detection and segmentation (IRSTDS) is a critical yet challenging task in defense and civilian applications, owing to the dim, shapeless appearance of targets and severe background clutter. Recent CNN-based methods have achieved promising target perception results, but they only focus on enhancing feature representation to offset the impact of noise, which results in the increased false alarms problem. In this paper, through analyzing the problem from the frequency domain, we pioneer in improving performance from noise suppression perspective and propose a novel noise-suppression feature pyramid network (NS-FPN), which integrates a low-frequency guided feature purification (LFP) module and a spiral-aware feature sampling (SFS) module into the original FPN structure. The LFP module suppresses the noise features by purifying high-frequency components to achieve feature enhancement devoid of noise interference, while the SFS module further adopts spiral sampling to fuse target-relevant features in feature fusion process. Our NS-FPN is designed to be lightweight yet effective and can be easily plugged into existing IRSTDS frameworks. Extensive experiments on the public IRSTDS datasets demonstrate that our method significantly reduces false alarms and achieves superior performance on IRSTDS tasks.
Rethinking Multi-modal Object Detection from the Perspective of Mono-Modality Feature Learning
Mar 14, 2025Multi-Modal Object Detection (MMOD), due to its stronger adaptability to various complex environments, has been widely applied in various applications. Extensive research is dedicated to the RGB-IR object detection, primarily focusing on how to integrate complementary features from RGB-IR modalities. However, they neglect the mono-modality insufficient learning problem that the decreased feature extraction capability in multi-modal joint learning. This leads to an unreasonable but prevalent phenomenon--Fusion Degradation, which hinders the performance improvement of the MMOD model. Motivated by this, in this paper, we introduce linear probing evaluation to the multi-modal detectors and rethink the multi-modal object detection task from the mono-modality learning perspective. Therefore, we construct an novel framework called M$^2$D-LIF, which consists of the Mono-Modality Distillation (M$^2$D) method and the Local Illumination-aware Fusion (LIF) module. The M$^2$D-LIF framework facilitates the sufficient learning of mono-modality during multi-modal joint training and explores a lightweight yet effective feature fusion manner to achieve superior object detection performance. Extensive experiments conducted on three MMOD datasets demonstrate that our M$^2$D-LIF effectively mitigates the Fusion Degradation phenomenon and outperforms the previous SOTA detectors.
Conformalized Link Prediction on Graph Neural Networks
Jun 26, 2024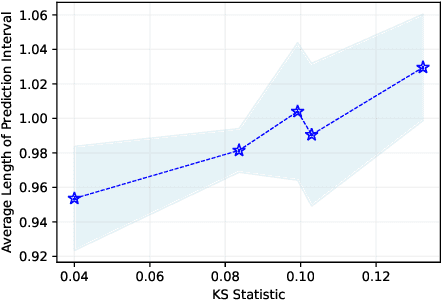
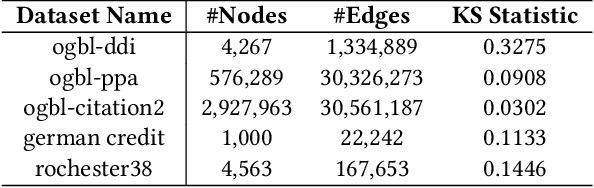
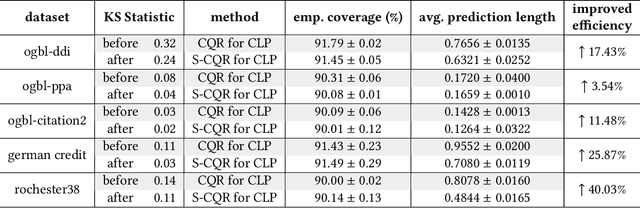
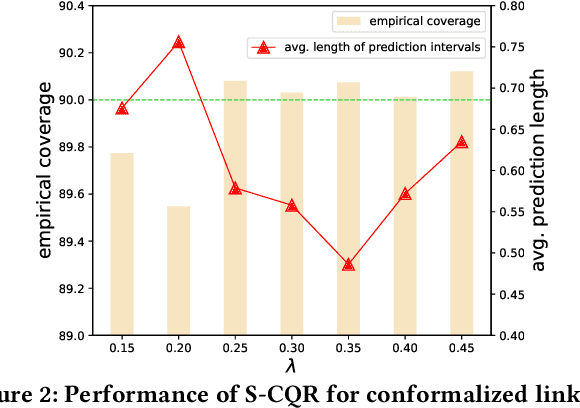
Graph Neural Networks (GNNs) excel in diverse tasks, yet their applications in high-stakes domains are often hampered by unreliable predictions. Although numerous uncertainty quantification methods have been proposed to address this limitation, they often lack \textit{rigorous} uncertainty estimates. This work makes the first attempt to introduce a distribution-free and model-agnostic uncertainty quantification approach to construct a predictive interval with a statistical guarantee for GNN-based link prediction. We term it as \textit{conformalized link prediction.} Our approach builds upon conformal prediction (CP), a framework that promises to construct statistically robust prediction sets or intervals. We first theoretically and empirically establish a permutation invariance condition for the application of CP in link prediction tasks, along with an exact test-time coverage. Leveraging the important structural information in graphs, we then identify a novel and crucial connection between a graph's adherence to the power law distribution and the efficiency of CP. This insight leads to the development of a simple yet effective sampling-based method to align the graph structure with a power law distribution prior to the standard CP procedure. Extensive experiments demonstrate that for conformalized link prediction, our approach achieves the desired marginal coverage while significantly improving the efficiency of CP compared to baseline methods.
UniRGB-IR: A Unified Framework for Visible-Infrared Downstream Tasks via Adapter Tuning
Apr 26, 2024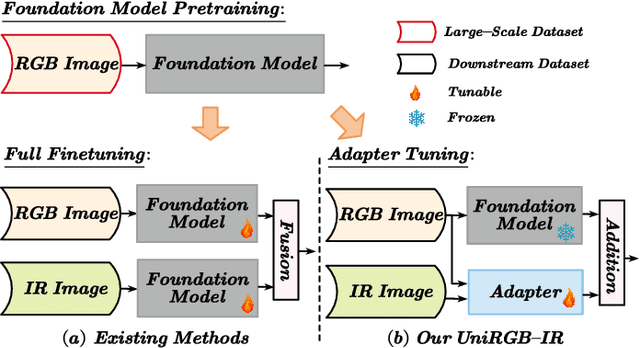

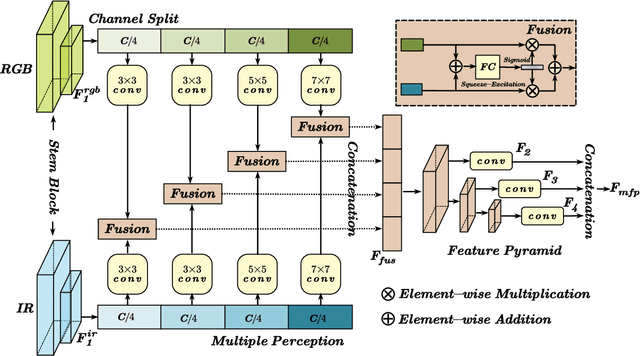
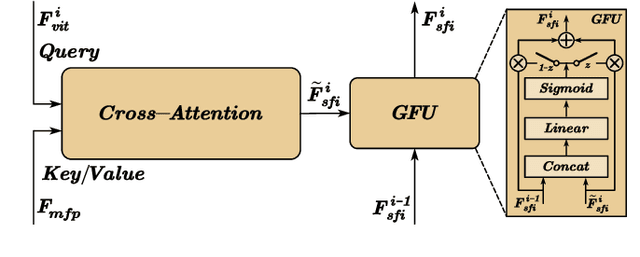
Semantic analysis on visible (RGB) and infrared (IR) images has gained attention for its ability to be more accurate and robust under low-illumination and complex weather conditions. Due to the lack of pre-trained foundation models on the large-scale infrared image datasets, existing methods prefer to design task-specific frameworks and directly fine-tune them with pre-trained foundation models on their RGB-IR semantic relevance datasets, which results in poor scalability and limited generalization. In this work, we propose a scalable and efficient framework called UniRGB-IR to unify RGB-IR downstream tasks, in which a novel adapter is developed to efficiently introduce richer RGB-IR features into the pre-trained RGB-based foundation model. Specifically, our framework consists of a vision transformer (ViT) foundation model, a Multi-modal Feature Pool (MFP) module and a Supplementary Feature Injector (SFI) module. The MFP and SFI modules cooperate with each other as an adpater to effectively complement the ViT features with the contextual multi-scale features. During training process, we freeze the entire foundation model to inherit prior knowledge and only optimize the MFP and SFI modules. Furthermore, to verify the effectiveness of our framework, we utilize the ViT-Base as the pre-trained foundation model to perform extensive experiments. Experimental results on various RGB-IR downstream tasks demonstrate that our method can achieve state-of-the-art performance. The source code and results are available at https://github.com/PoTsui99/UniRGB-IR.git.