 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Role of Message Passing in Dual-Privacy Preservation on GNNs
Aug 25, 2023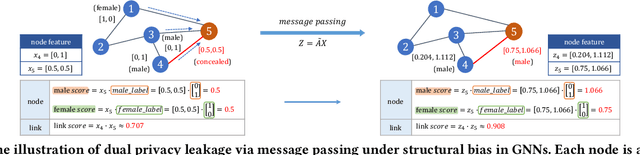

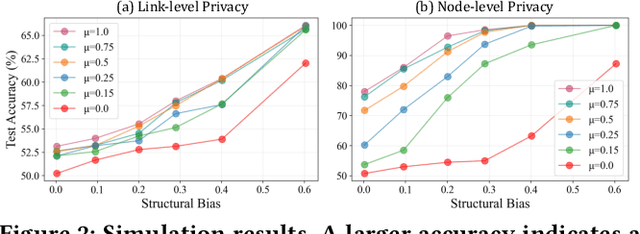
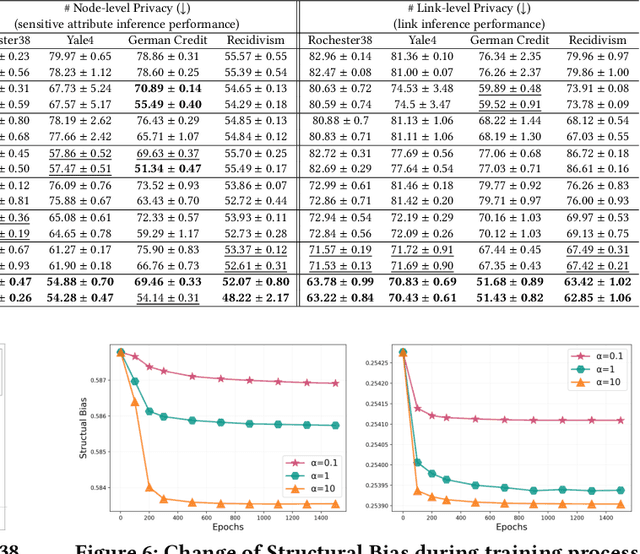
Graph Neural Networks (GNNs) are powerful tools for learning representations on graphs, such as social networks. However, their vulnerability to privacy inference attacks restricts their practicality, especially in high-stake domains. To address this issue, privacy-preserving GNNs have been proposed, focusing on preserving node and/or link privacy. This work takes a step back and investigates how GNNs contribute to privacy leakage. Through theoretical analysis and simulations, we identify message passing under structural bias as the core component that allows GNNs to \textit{propagate} and \textit{amplify} privacy leakage. Building upon these findings, we propose a principled privacy-preserving GNN framework that effectively safeguards both node and link privacy, referred to as dual-privacy preservation. The framework comprises three major modules: a Sensitive Information Obfuscation Module that removes sensitive information from node embeddings, a Dynamic Structure Debiasing Module that dynamically corrects the structural bias, and an Adversarial Learning Module that optimizes the privacy-utility trade-off. Experimental results on four benchmark datasets validate the effectiveness of the proposed model in protecting both node and link privacy while preserving high utility for downstream tasks, such as node classification.
Mutimodal Ranking Optimization for Heterogeneous Face Re-identification
Dec 11, 2022
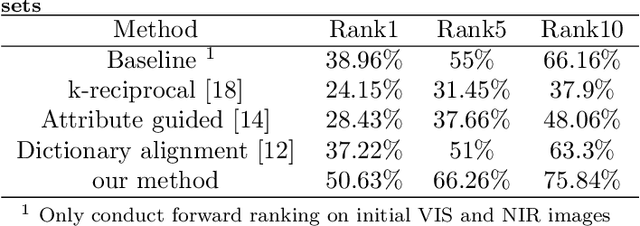

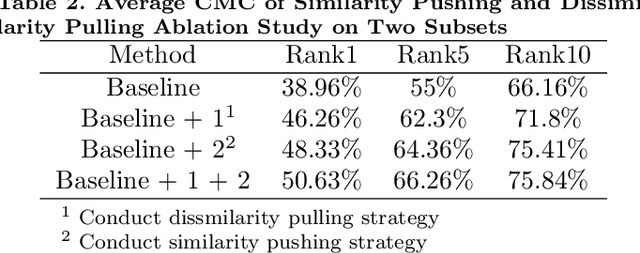
Heterogeneous face re-identification, namely matching heterogeneous faces across disjoint visible light (VIS) and near-infrared (NIR) cameras, has become an important problem in video surveillance application. However, the large domain discrepancy between heterogeneous NIR-VIS faces makes the performance of face re-identification degraded dramatically. To solve this problem, a multimodal fusion ranking optimization algorithm for heterogeneous face re-identification is proposed in this paper. Firstly, we design a heterogeneous face translation network to obtain multimodal face pairs, including NIR-VIS/NIR-NIR/VIS-VIS face pairs, through mutual transformation between NIR-VIS faces. Secondly, we propose linear and non-linear fusion strategies to aggregate initial ranking lists of multimodal face pairs and acquire the optimized re-ranked list based on modal complementarity. The experimental results show that the proposed multimodal fusion ranking optimization algorithm can effectively utilize the complementarity and outperforms some relative methods on the SCface dataset.
Evaluating the Faithfulness of Saliency-based Explanations for Deep Learning Models for Temporal Colour Constancy
Nov 15, 2022
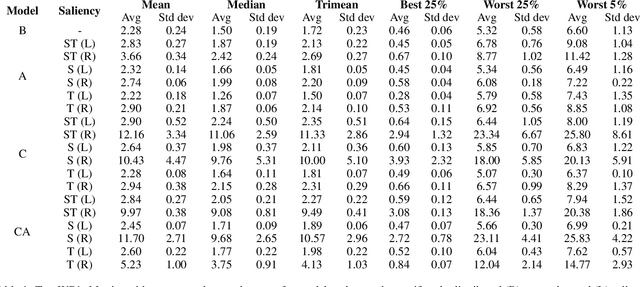

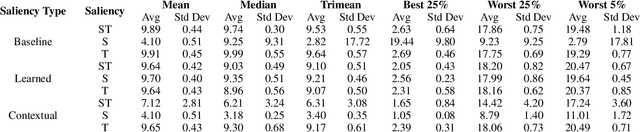
The opacity of deep learning models constrains their debugging and improvement. Augmenting deep models with saliency-based strategies, such as attention, has been claimed to help get a better understanding of the decision-making process of black-box models. However, some recent works challenged saliency's faithfulness in the field of Natural Language Processing (NLP), questioning attention weights' adherence to the true decision-making process of the model. We add to this discussion by evaluating the faithfulness of in-model saliency applied to a video processing task for the first time, namely, temporal colour constancy. We perform the evaluation by adapting to our target task two tests for faithfulness from recent NLP literature, whose methodology we refine as part of our contributions. We show that attention fails to achieve faithfulness, while confidence, a particular type of in-model visual saliency, succeeds.
Cascading Convolutional Temporal Colour Constancy
Jun 15, 2021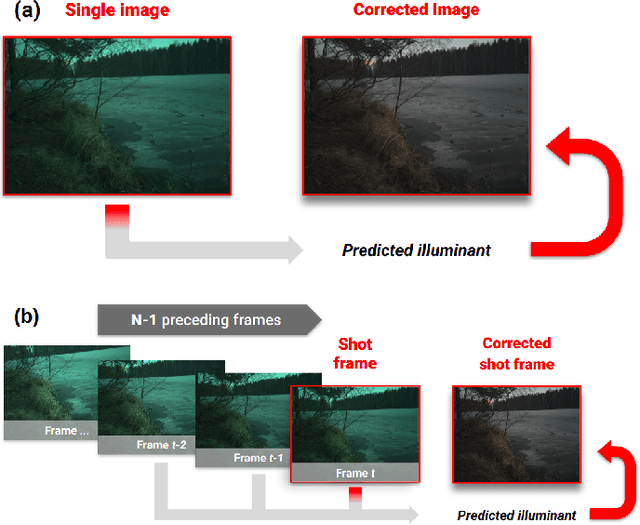
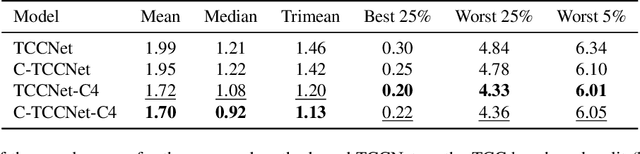
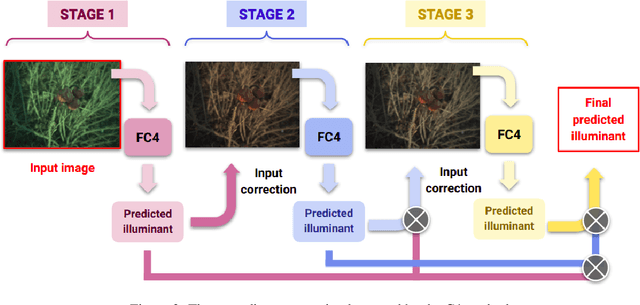
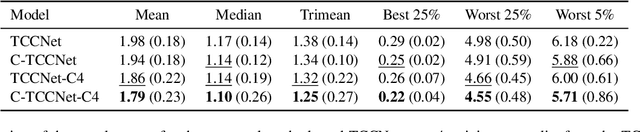
Computational Colour Constancy (CCC) consists of estimating the colour of one or more illuminants in a scene and using them to remove unwanted chromatic distortions. Much research has focused on illuminant estimation for CCC on single images, with few attempts of leveraging the temporal information intrinsic in sequences of correlated images (e.g., the frames in a video), a task known as Temporal Colour Constancy (TCC). The state-of-the-art for TCC is TCCNet, a deep-learning architecture that uses a ConvLSTM for aggregating the encodings produced by CNN submodules for each image in a sequence. We extend this architecture with different models obtained by (i) substituting the TCCNet submodules with C4, the state-of-the-art method for CCC targeting images; (ii) adding a cascading strategy to perform an iterative improvement of the estimate of the illuminant. We tested our models on the recently released TCC benchmark and achieved results that surpass the state-of-the-art. Analyzing the impact of the number of frames involved in illuminant estimation on performance, we show that it is possible to reduce inference time by training the models on few selected frames from the sequences while retaining comparable accuracy.
A Distributed Fair Machine Learning Framework with Private Demographic Data Protection
Sep 17, 2019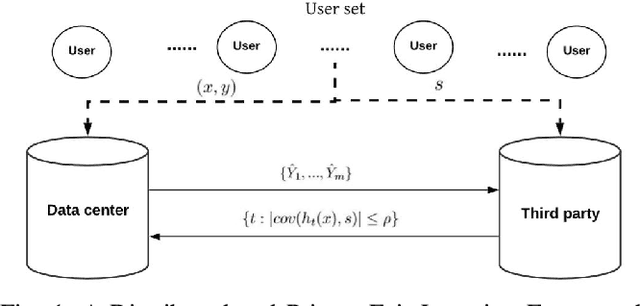
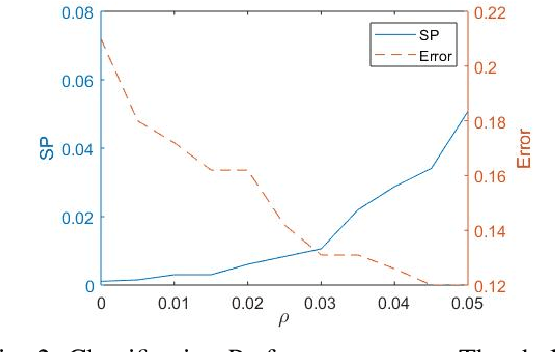
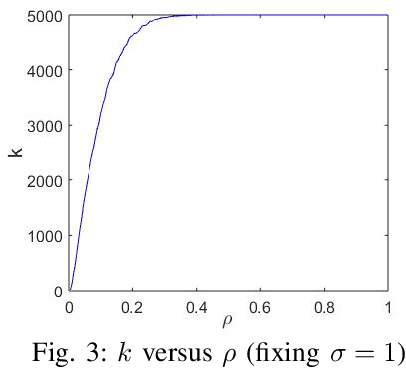
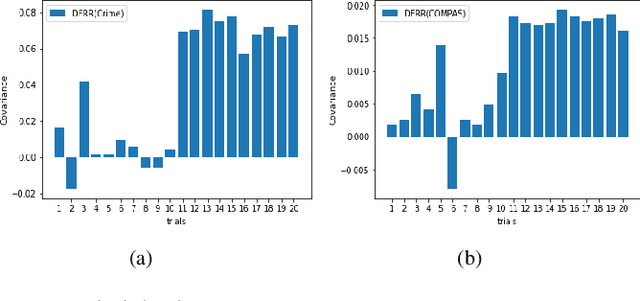
Fair machine learning has become a significant research topic with broad societal impact. However, most fair learning methods require direct access to personal demographic data, which is increasingly restricted to use for protecting user privacy (e.g. by the EU General Data Protection Regulation). In this paper, we propose a distributed fair learning framework for protecting the privacy of demographic data. We assume this data is privately held by a third party, which can communicate with the data center (responsible for model development) without revealing the demographic information. We propose a principled approach to design fair learning methods under this framework, exemplify four methods and show they consistently outperform their existing counterparts in both fairness and accuracy across three real-world data sets. We theoretically analyze the framework, and prove it can learn models with high fairness or high accuracy, with their trade-offs balanced by a threshold variable.
A Wearable Tactile Sensor Array for Large Area Remote Vibration Sensing in the Hand
Aug 22, 2019
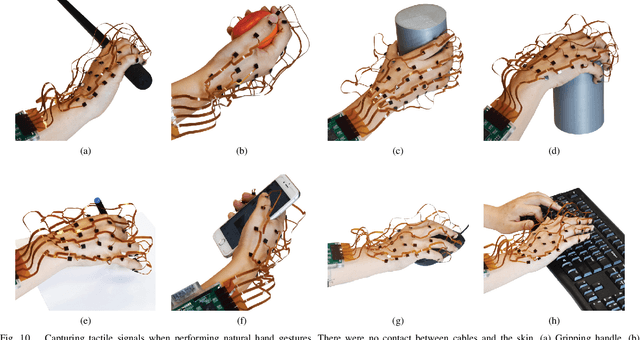
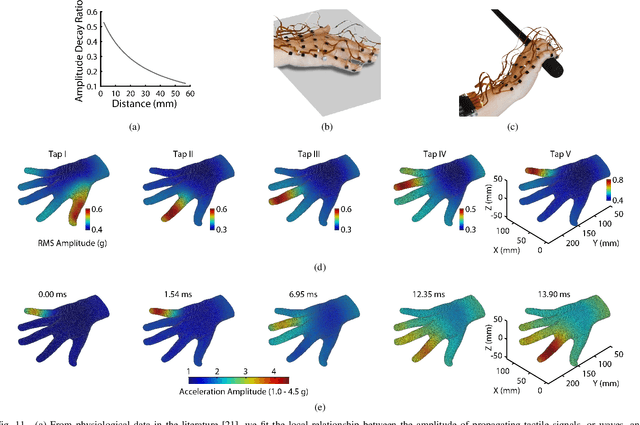
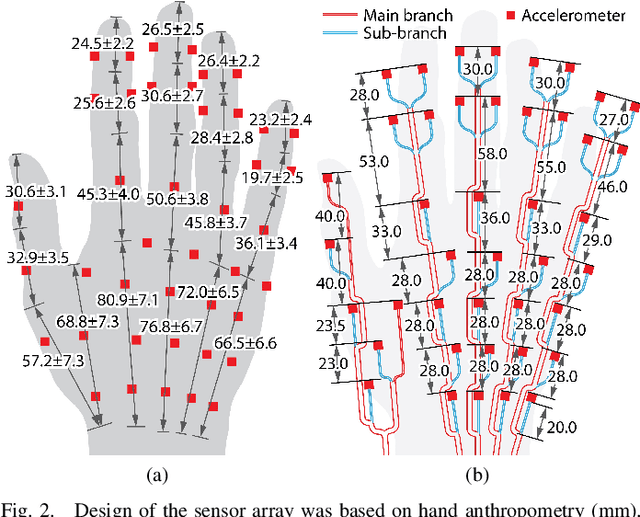
Tactile sensing is a essential for skilled manipulation and object perception, but existing devices are unable to capture mechanical signals in the full gamut of regimes that are important for human touch sensing, and are unable to emulate the sensing abilities of the human hand. Recent research reveals that human touch sensing relies on the transmission of mechanical waves throughout tissues of the hand. This provides the hand with remarkable abilities to remotely capture distributed vibration signatures of touch contact. Little engineering attention has been given to important sensory system. Here, we present a wearable device inspired by the anatomy and function of the hand and by human sensory abilities. The device is based on a 126 channel sensor array capable of capturing high resolution tactile signals during natural manual activities. It employs a network of miniature three-axis sensors mounted on a flexible circuit whose geometry and topology were designed match the anatomy of the hand, permitting data capture during natural interactions, while minimizing artifacts. Each sensor possesses a frequency bandwidth matching the human tactile frequency range. Data is acquired in real time via a custom FPGA and an I$^2$C network. We also present physiologically informed signal processing methods for reconstructing whole hand tactile signals using data from this system. We report experiments that demonstrate the ability of this system to accurately capture remotely produced whole hand tactile signals during manual interactions.
Fair Kernel Regression via Fair Feature Embedding in Kernel Space
Jul 04, 2019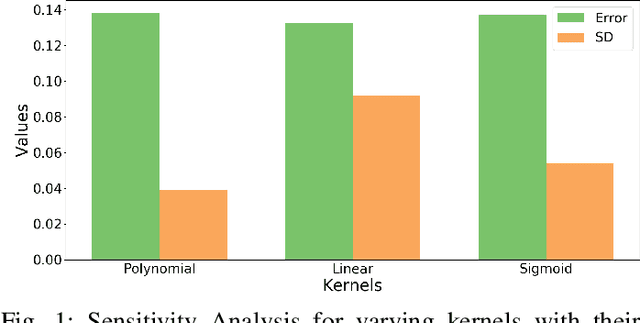
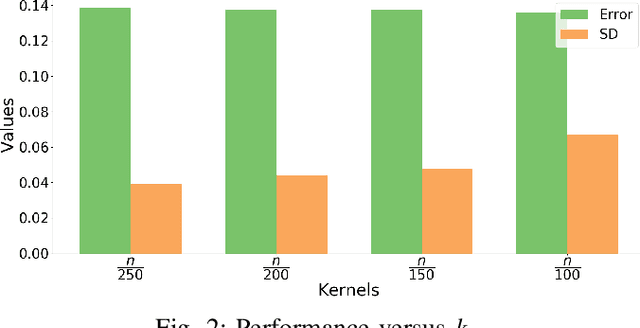
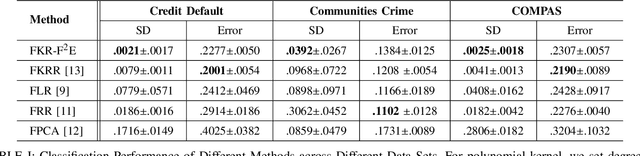
In recent years, there have been significant efforts on mitigating unethical demographic biases in machine learning methods. However, very little is done for kernel methods. In this paper, we propose a new fair kernel regression method via fair feature embedding (FKR-F$^2$E) in kernel space. Motivated by prior works on feature selection in kernel space and feature processing for fair machine learning, we propose to learn fair feature embedding functions that minimize demographic discrepancy of feature distributions in kernel space. Compared to the state-of-the-art fair kernel regression method and several baseline methods, we show FKR-F$^2$E achieves significantly lower prediction disparity across three real-world data sets.