 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevant Irrelevance: Generating Alterfactual Explanations for Image Classifiers
May 08, 2024
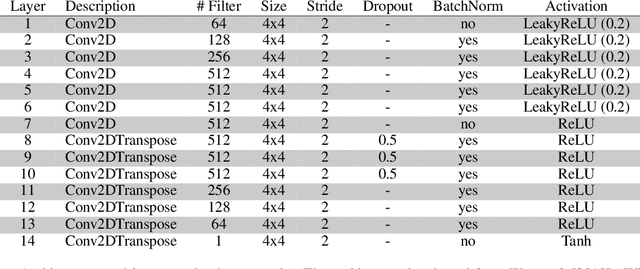

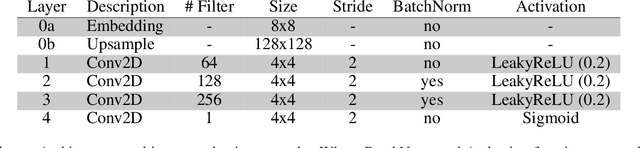
In this paper, we demonstrate the feasibility of alterfactual explanations for black box image classifiers. Traditional explanation mechanisms from the field of Counterfactual Thinking are a widely-used paradigm for Explainable Artificial Intelligence (XAI), as they follow a natural way of reasoning that humans are familiar with. However, most common approaches from this field are based on communicating information about features or characteristics that are especially important for an AI's decision. However, to fully understand a decision, not only knowledge about relevant features is needed, but the awareness of irrelevant information also highly contributes to the creation of a user's mental model of an AI system. To this end, a novel approach for explaining AI systems called alterfactual explanations was recently proposed on a conceptual level. It is based on showing an alternative reality where irrelevant features of an AI's input are altered. By doing so, the user directly sees which input data characteristics can change arbitrarily without influencing the AI's decision. In this paper, we show for the first time that it is possible to apply this idea to black box models based on neural networks. To this end, we present a GAN-based approach to generate these alterfactual explanations for binary image classifiers. Further, we present a user study that gives interesting insights on how alterfactual explanations can complement counterfactual explanations.
Personalizing explanations of AI-driven hints to users' cognitive abilities: an empirical evaluation
Mar 09, 2024



We investigate personalizing the explanations that an Intelligent Tutoring System generates to justify the hints it provides to students to foster their learning. The personalization targets students with low levels of two traits, Need for Cognition and Conscientiousness, and aims to enhance these students' engagement with the explanations, based on prior findings that these students do not naturally engage with the explanations but they would benefit from them if they do. To evaluate the effectiveness of the personalization, we conducted a user study where we found that our proposed personalization significantly increases our target users' interaction with the hint explanations, their understanding of the hints and their learning. Hence, this work provides valuable insights into effectively personalizing AI-driven explanations for cognitively demanding tasks such as learning.
Classification of Alzheimers Disease with Deep Learning on Eye-tracking Data
Sep 22, 2023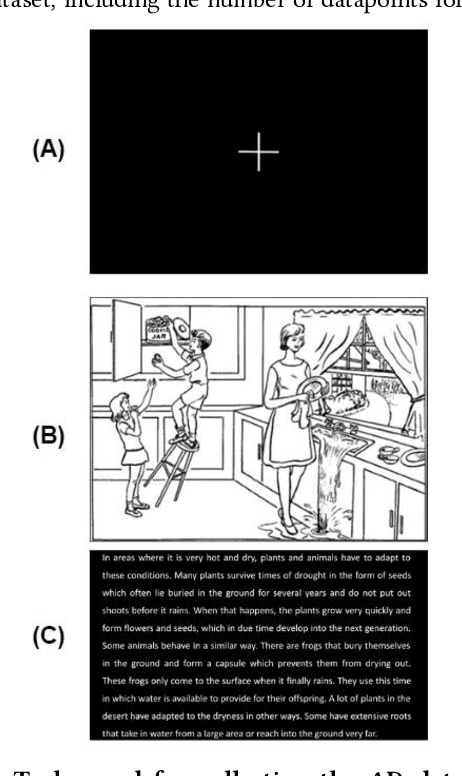
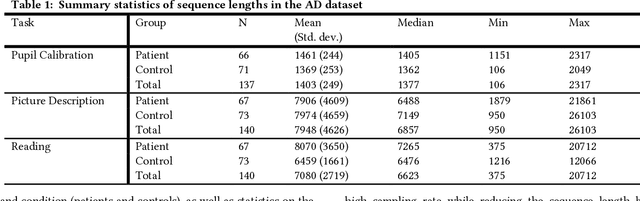
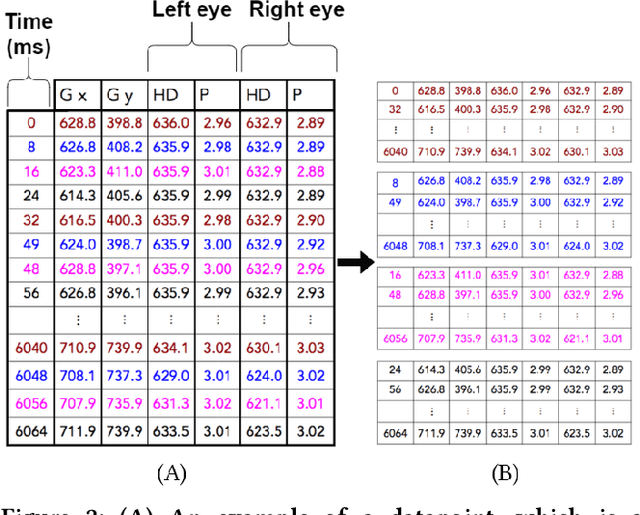
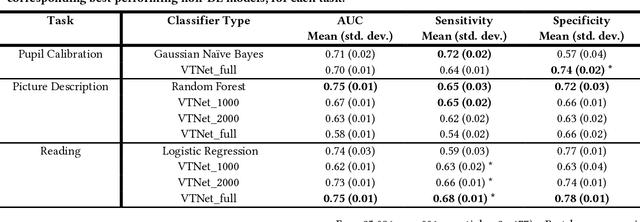
Existing research has shown the potential of classifying Alzheimers Disease (AD) from eye-tracking (ET) data with classifiers that rely on task-specific engineered features. In this paper, we investigate whether we can improve on existing results by using a Deep-Learning classifier trained end-to-end on raw ET data. This classifier (VTNet) uses a GRU and a CNN in parallel to leverage both visual (V) and temporal (T) representations of ET data and was previously used to detect user confusion while processing visual displays. A main challenge in applying VTNet to our target AD classification task is that the available ET data sequences are much longer than those used in the previous confusion detection task, pushing the limits of what is manageable by LSTM-based models. We discuss how we address this challenge and show that VTNet outperforms the state-of-the-art approaches in AD classification, providing encouraging evidence on the generality of this model to make predictions from ET data.
Evaluating the overall sensitivity of saliency-based explanation methods
Jun 21, 2023
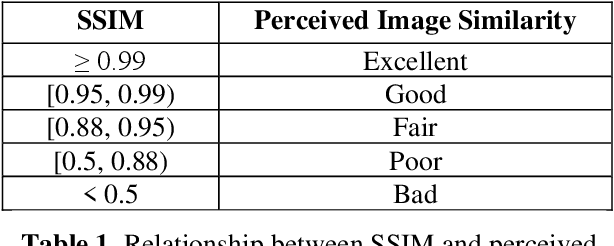
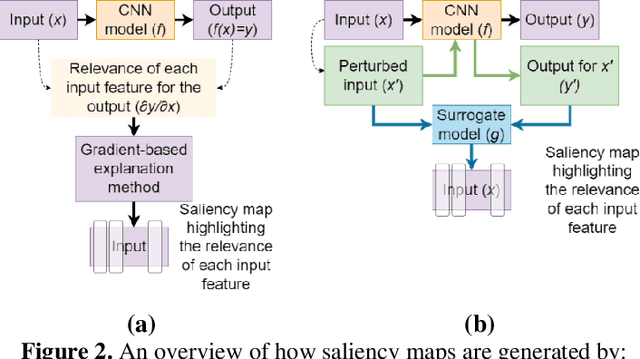
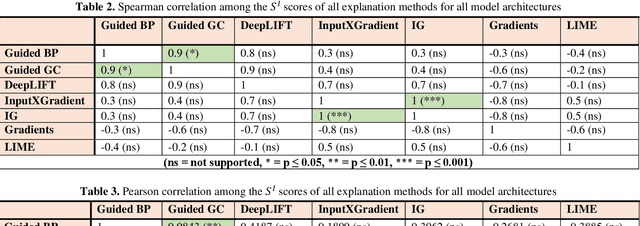
We address the need to generate faithful explanations of "black box" Deep Learning models. Several tests have been proposed to determine aspects of faithfulness of explanation methods, but they lack cross-domain applicability and a rigorous methodology. Hence, we select an existing test that is model agnostic and is well-suited for comparing one aspect of faithfulness (i.e., sensitivity) of multiple explanation methods, and extend it by specifying formal thresh-olds and building criteria to determine the over-all sensitivity of the explanation method. We present examples of how multiple explanation methods for Convolutional Neural Networks can be compared using this extended methodology. Finally, we discuss the relationship between sensitivity and faithfulness and consider how the test can be adapted to assess different explanation methods in other domains.
GANonymization: A GAN-based Face Anonymization Framework for Preserving Emotional Expressions
May 03, 2023

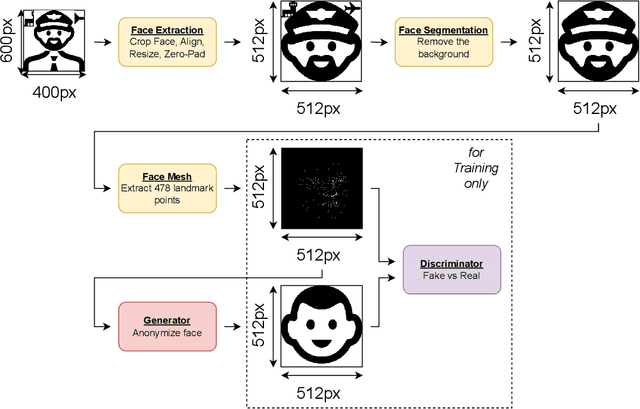

In recent years, the increasing availability of personal data has raised concerns regarding privacy and security. One of the critical processes to address these concerns is data anonymization, which aims to protect individual privacy and prevent the release of sensitive information. This research focuses on the importance of face anonymization. Therefore, we introduce GANonymization, a novel face anonymization framework with facial expression-preserving abilities. Our approach is based on a high-level representation of a face which is synthesized into an anonymized version based on a generative adversarial network (GAN). The effectiveness of the approach was assessed by evaluating its performance in removing identifiable facial attributes to increase the anonymity of the given individual face. Additionally, the performance of preserving facial expressions was evaluated on several affect recognition datasets and outperformed the state-of-the-art method in most categories. Finally, our approach was analyzed for its ability to remove various facial traits, such as jewelry, hair color, and multiple others. Here, it demonstrated reliable performance in removing these attributes. Our results suggest that GANonymization is a promising approach for anonymizing faces while preserving facial expressions.
A Theoretical Framework for AI Models Explainability
Dec 29, 2022
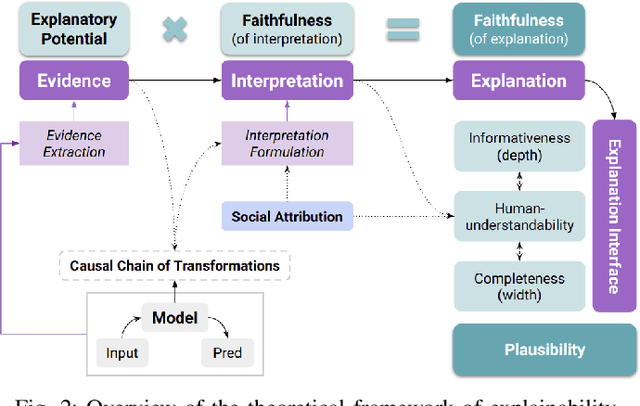
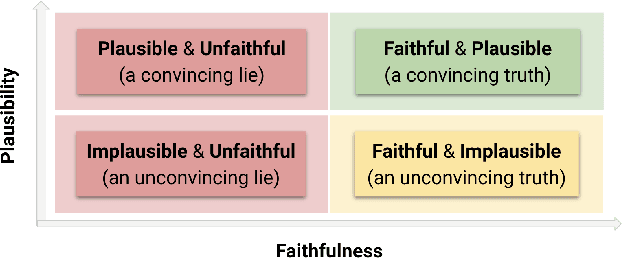
Explainability is a vibrant research topic in the artificial intelligence community, with growing interest across methods and domains. Much has been written about the topic, yet explainability still lacks shared terminology and a framework capable of providing structural soundness to explanations. In our work, we address these issues by proposing a novel definition of explanation that is a synthesis of what can be found in the literature. We recognize that explanations are not atomic but the product of evidence stemming from the model and its input-output and the human interpretation of this evidence. Furthermore, we fit explanations into the properties of faithfulness (i.e., the explanation being a true description of the model's decision-making) and plausibility (i.e., how much the explanation looks convincing to the user). Using our proposed theoretical framework simplifies how these properties are ope rationalized and provide new insight into common explanation methods that we analyze as case studies.
Evaluating the Faithfulness of Saliency-based Explanations for Deep Learning Models for Temporal Colour Constancy
Nov 15, 2022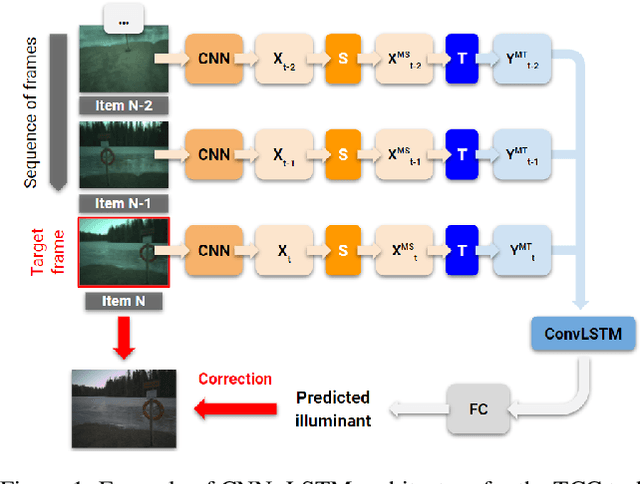
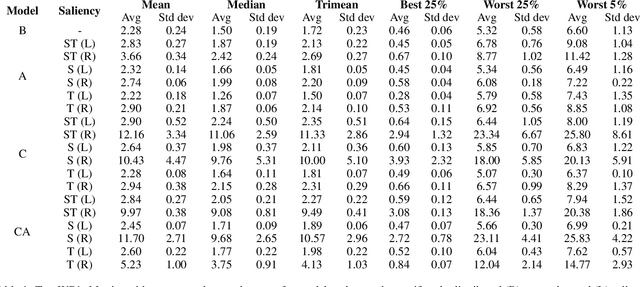

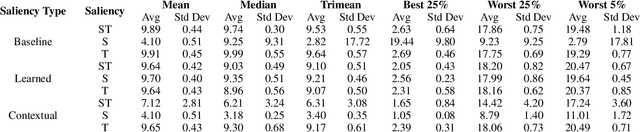
The opacity of deep learning models constrains their debugging and improvement. Augmenting deep models with saliency-based strategies, such as attention, has been claimed to help get a better understanding of the decision-making process of black-box models. However, some recent works challenged saliency's faithfulness in the field of Natural Language Processing (NLP), questioning attention weights' adherence to the true decision-making process of the model. We add to this discussion by evaluating the faithfulness of in-model saliency applied to a video processing task for the first time, namely, temporal colour constancy. We perform the evaluation by adapting to our target task two tests for faithfulness from recent NLP literature, whose methodology we refine as part of our contributions. We show that attention fails to achieve faithfulness, while confidence, a particular type of in-model visual saliency, succeeds.
Cascading Convolutional Temporal Colour Constancy
Jun 15, 2021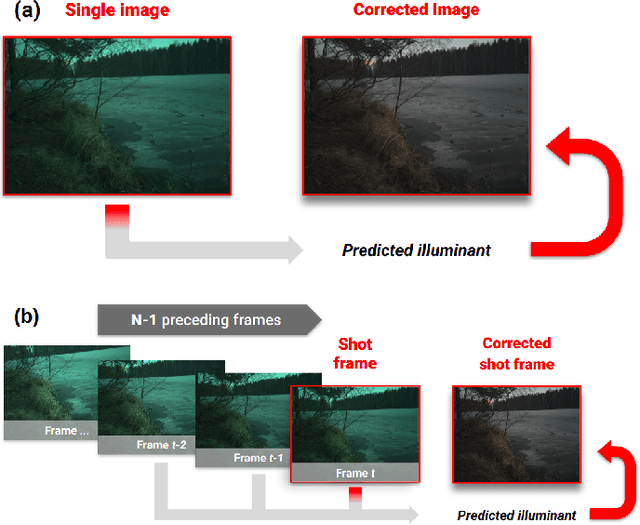
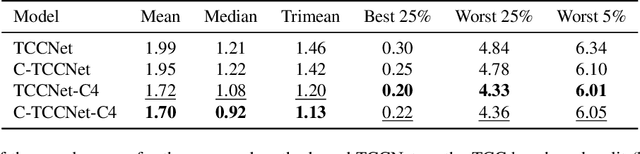
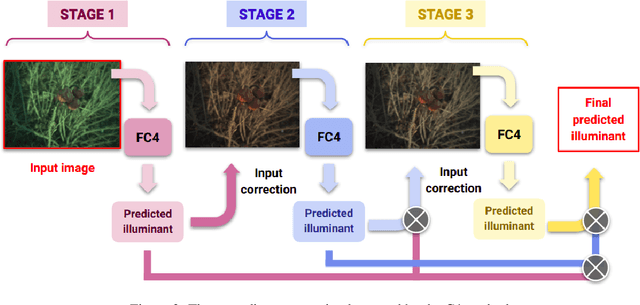
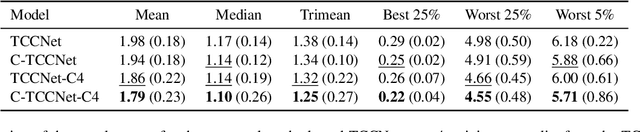
Computational Colour Constancy (CCC) consists of estimating the colour of one or more illuminants in a scene and using them to remove unwanted chromatic distortions. Much research has focused on illuminant estimation for CCC on single images, with few attempts of leveraging the temporal information intrinsic in sequences of correlated images (e.g., the frames in a video), a task known as Temporal Colour Constancy (TCC). The state-of-the-art for TCC is TCCNet, a deep-learning architecture that uses a ConvLSTM for aggregating the encodings produced by CNN submodules for each image in a sequence. We extend this architecture with different models obtained by (i) substituting the TCCNet submodules with C4, the state-of-the-art method for CCC targeting images; (ii) adding a cascading strategy to perform an iterative improvement of the estimate of the illuminant. We tested our models on the recently released TCC benchmark and achieved results that surpass the state-of-the-art. Analyzing the impact of the number of frames involved in illuminant estimation on performance, we show that it is possible to reduce inference time by training the models on few selected frames from the sequences while retaining comparable accuracy.
A Framework to Counteract Suboptimal User-Behaviors in Exploratory Learning Environments: an Application to MOOCs
Jun 14, 2021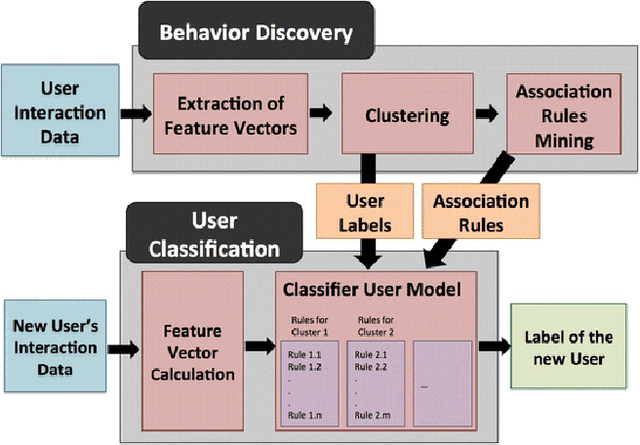

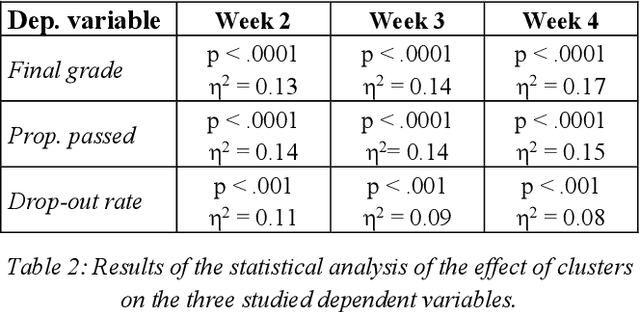
While there is evidence that user-adaptive support can greatly enhance the effectiveness of educational systems, designing such support for exploratory learning environments (e.g., simulations) is still challenging due to the open-ended nature of their interaction. In particular, there is little a priori knowledge of which student's behaviors can be detrimental to learning in such environments. To address this problem, we focus on a data-driven user-modeling framework that uses logged interaction data to learn which behavioral or activity patterns should trigger help during interaction with a specific learning environment. This framework has been successfully used to provide adaptive support in interactive learning simulations. Here we present a novel application of this framework we are working on, namely to Massive Open Online Courses (MOOCs), a form of exploratory environment that could greatly benefit from adaptive support due to the large diversity of their users, but typically lack of such adaptation. We describe an experiment aimed at investigating the value of our framework to identify student's behaviors that can justify adapting to, and report some preliminary results.
A Neural Architecture for Detecting Confusion in Eye-tracking Data
Mar 13, 2020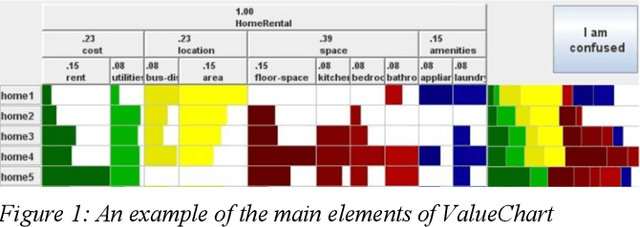

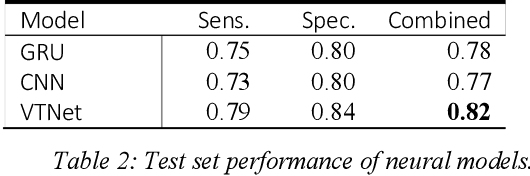
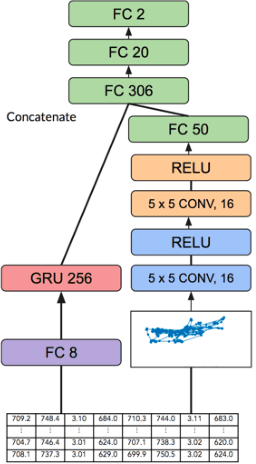
Encouraged by the success of deep learning in a variety of domains, we investigate a novel application of its methods on the effectiveness of detecting user confusion in eye-tracking data. We introduce an architecture that uses RNN and CNN sub-models in parallel to take advantage of the temporal and visuospatial aspects of our data. Experiments with a dataset of user interactions with the ValueChart visualization tool show that our model outperforms an existing model based on Random Forests resulting in a 22% improvement in combined sensitivity & specificity.