 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECKBench: Benchmarking Multi-Agent Frameworks for Academic Slide Generation and Editing
Feb 10, 2026Automatically generating and iteratively editing academic slide decks requires more than document summarization. It demands faithful content selection, coherent slide organization, layout-aware rendering, and robust multi-turn instruction following. However, existing benchmarks and evaluation protocols do not adequately measure these challenges. To address this gap, we introduce the Deck Edits and Compliance Kit Benchmark (DECKBench), an evaluation framework for multi-agent slide generation and editing. DECKBench is built on a curated dataset of paper to slide pairs augmented with realistic, simulated editing instructions. Our evaluation protocol systematically assesses slide-level and deck-level fidelity, coherence, layout quality, and multi-turn instruction following. We further implement a modular multi-agent baseline system that decomposes the slide generation and editing task into paper parsing and summarization, slide planning, HTML creation, and iterative editing. Experimental results demonstrate that the proposed benchmark highlights strengths, exposes failure modes, and provides actionable insights for improving multi-agent slide generation and editing systems. Overall, this work establishes a standardized foundation for reproducible and comparable evaluation of academic presentation generation and editing. Code and data are publicly available at https://github.com/morgan-heisler/DeckBench .
Evaluating the Faithfulness of Saliency-based Explanations for Deep Learning Models for Temporal Colour Constancy
Nov 15, 2022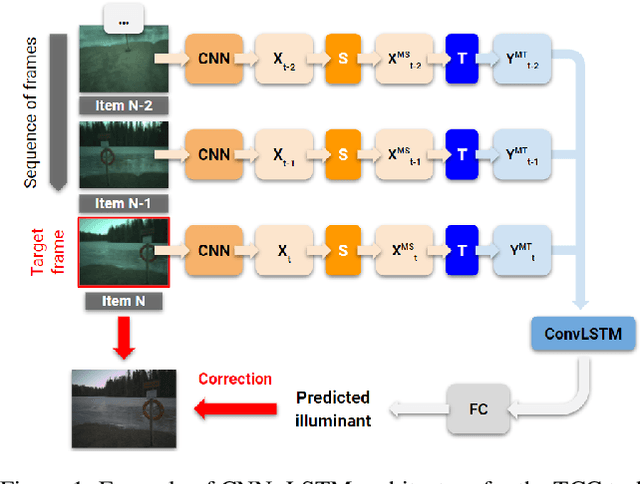
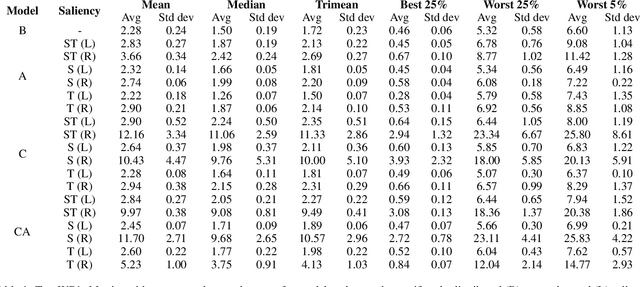

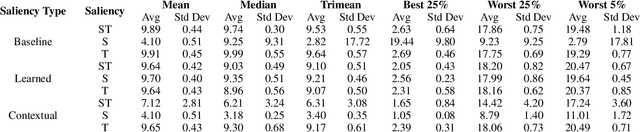
The opacity of deep learning models constrains their debugging and improvement. Augmenting deep models with saliency-based strategies, such as attention, has been claimed to help get a better understanding of the decision-making process of black-box models. However, some recent works challenged saliency's faithfulness in the field of Natural Language Processing (NLP), questioning attention weights' adherence to the true decision-making process of the model. We add to this discussion by evaluating the faithfulness of in-model saliency applied to a video processing task for the first time, namely, temporal colour constancy. We perform the evaluation by adapting to our target task two tests for faithfulness from recent NLP literature, whose methodology we refine as part of our contributions. We show that attention fails to achieve faithfulness, while confidence, a particular type of in-model visual saliency, succeeds.
Cascading Convolutional Temporal Colour Constancy
Jun 15, 2021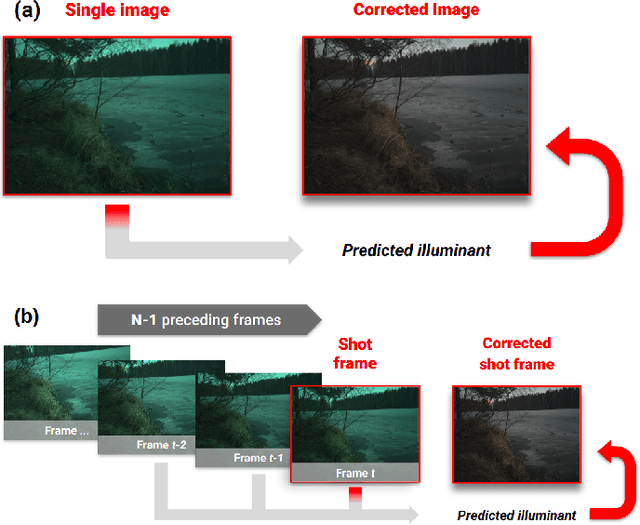
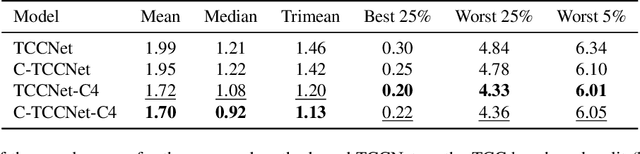
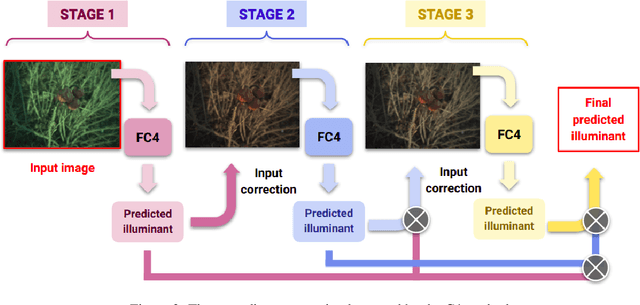
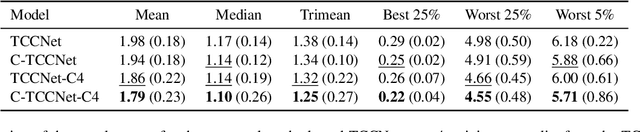
Computational Colour Constancy (CCC) consists of estimating the colour of one or more illuminants in a scene and using them to remove unwanted chromatic distortions. Much research has focused on illuminant estimation for CCC on single images, with few attempts of leveraging the temporal information intrinsic in sequences of correlated images (e.g., the frames in a video), a task known as Temporal Colour Constancy (TCC). The state-of-the-art for TCC is TCCNet, a deep-learning architecture that uses a ConvLSTM for aggregating the encodings produced by CNN submodules for each image in a sequence. We extend this architecture with different models obtained by (i) substituting the TCCNet submodules with C4, the state-of-the-art method for CCC targeting images; (ii) adding a cascading strategy to perform an iterative improvement of the estimate of the illuminant. We tested our models on the recently released TCC benchmark and achieved results that surpass the state-of-the-art. Analyzing the impact of the number of frames involved in illuminant estimation on performance, we show that it is possible to reduce inference time by training the models on few selected frames from the sequences while retaining comparable accuracy.
Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting
May 19, 2020
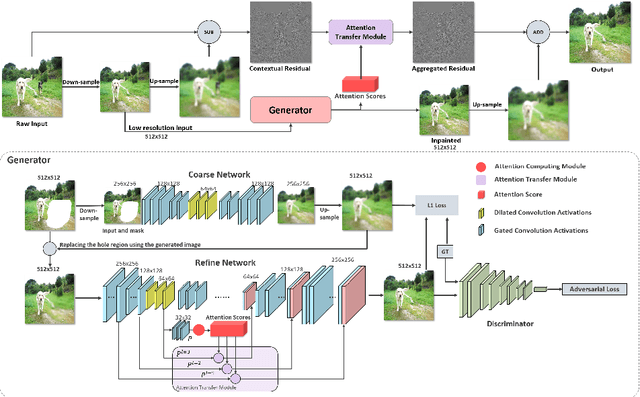


Recently data-driven image inpainting methods have made inspiring progress, impacting fundamental image editing tasks such as object removal and damaged image repairing. These methods are more effective than classic approaches, however, due to memory limitations they can only handle low-resolution inputs, typically smaller than 1K. Meanwhile, the resolution of photos captured with mobile devices increases up to 8K. Naive up-sampling of the low-resolution inpainted result can merely yield a large yet blurry result. Whereas, adding a high-frequency residual image onto the large blurry image can generate a sharp result, rich in details and textures. Motivated by this, we propose a Contextual Residual Aggregation (CRA) mechanism that can produce high-frequency residuals for missing contents by weighted aggregating residuals from contextual patches, thus only requiring a low-resolution prediction from the network. Since convolutional layers of the neural network only need to operate on low-resolution inputs and outputs, the cost of memory and computing power is thus well suppressed. Moreover, the need for high-resolution training datasets is alleviated. In our experiments, we train the proposed model on small images with resolutions 512x512 and perform inference on high-resolution images, achieving compelling inpainting quality. Our model can inpaint images as large as 8K with considerable hole sizes, which is intractable with previous learning-based approaches. We further elaborate on the light-weight design of the network architecture, achieving real-time performance on 2K images on a GTX 1080 Ti GPU. Codes are available at: Atlas200dk/sample-imageinpainting-HiFill.