 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimInsert: Seamless Video Object Insertion via Regional Sparse Attention Fusion
May 22, 2026Video object insertion requires ensuring spatio-temporal coherence and interactive realism, extending far beyond simple content placement. However, current approaches are often hindered by a reliance on explicit motion engineering or resource-intensive retraining, restricting their flexibility and generalization. To bridge this gap, we present \textit{SimInsert}, a training-free paradigm that efficiently decouples the task into intuitive single-frame editing and semantic motion description. By harnessing the robust generative priors of image-to-video diffusion models, SimInsert propagates edits temporally, strictly preserving background invariance while enabling plausible, text-driven interactions between the inserted object and the dynamic environment. Our approach hinges on non-invasive guidance mechanisms that enforce structural consistency, facilitate seamless boundary fusion, and counteract the fidelity drift that typically accumulates during the denoising trajectory. Extensive quantitative experiments validate our efficacy: SimInsert surpasses state-of-the-art methods with an 18.8\% gain in PSNR, 20.1\% in SSIM, and a 44.1\% decrease in LPIPS, offering a streamlined solution for high-fidelity video editing.
An Empirical Study of the Imbalance Issue in Software Vulnerability Detection
Feb 12, 2026Vulnerability detection is crucial to protect software security. Nowadays, deep learning (DL) is the most promising technique to automate this detection task, leveraging its superior ability to extract patterns and representations within extensive code volumes. Despite its promise, DL-based vulnerability detection remains in its early stages, with model performance exhibiting variability across datasets. Drawing insights from other well-explored application areas like computer vision, we conjecture that the imbalance issue (the number of vulnerable code is extremely small) is at the core of the phenomenon. To validate this, we conduct a comprehensive empirical study involving nine open-source datasets and two state-of-the-art DL models. The results confirm our conjecture. We also obtain insightful findings on how existing imbalance solutions perform in vulnerability detection. It turns out that these solutions perform differently as well across datasets and evaluation metrics. Specifically: 1) Focal loss is more suitable to improve the precision, 2) mean false error and class-balanced loss encourages the recall, and 3) random over-sampling facilitates the F1-measure. However, none of them excels across all metrics. To delve deeper, we explore external influences on these solutions and offer insights for developing new solutions.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
FreeControl: Efficient, Training-Free Structural Control via One-Step Attention Extraction
Nov 07, 2025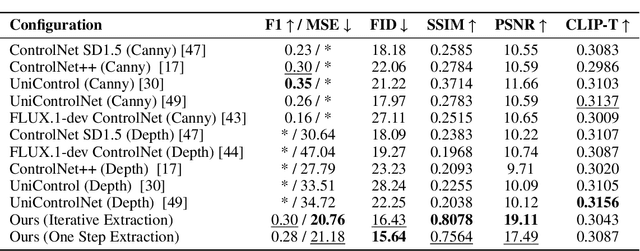
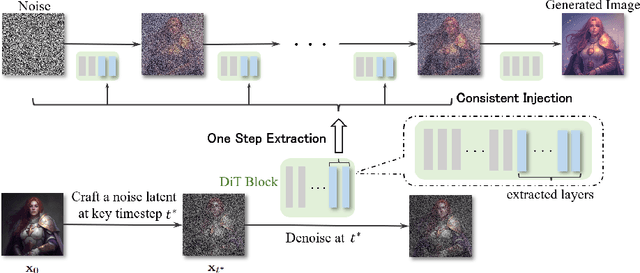
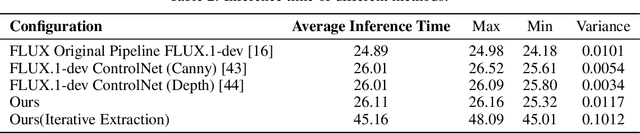

Controlling the spatial and semantic structure of diffusion-generated images remains a challenge. Existing methods like ControlNet rely on handcrafted condition maps and retraining, limiting flexibility and generalization. Inversion-based approaches offer stronger alignment but incur high inference cost due to dual-path denoising. We present FreeControl, a training-free framework for semantic structural control in diffusion models. Unlike prior methods that extract attention across multiple timesteps, FreeControl performs one-step attention extraction from a single, optimally chosen key timestep and reuses it throughout denoising. This enables efficient structural guidance without inversion or retraining. To further improve quality and stability, we introduce Latent-Condition Decoupling (LCD): a principled separation of the key timestep and the noised latent used in attention extraction. LCD provides finer control over attention quality and eliminates structural artifacts. FreeControl also supports compositional control via reference images assembled from multiple sources - enabling intuitive scene layout design and stronger prompt alignment. FreeControl introduces a new paradigm for test-time control, enabling structurally and semantically aligned, visually coherent generation directly from raw images, with the flexibility for intuitive compositional design and compatibility with modern diffusion models at approximately 5 percent additional cost.
A Multi-Dataset Evaluation of Models for Automated Vulnerability Repair
Jun 05, 2025Software vulnerabilities pose significant security threats, requiring effective mitigation. While Automated Program Repair (APR) has advanced in fixing general bugs, vulnerability patching, a security-critical aspect of APR remains underexplored. This study investigates pre-trained language models, CodeBERT and CodeT5, for automated vulnerability patching across six datasets and four languages. We evaluate their accuracy and generalization to unknown vulnerabilities. Results show that while both models face challenges with fragmented or sparse context, CodeBERT performs comparatively better in such scenarios, whereas CodeT5 excels in capturing complex vulnerability patterns. CodeT5 also demonstrates superior scalability. Furthermore, we test fine-tuned models on both in-distribution (trained) and out-of-distribution (unseen) datasets. While fine-tuning improves in-distribution performance, models struggle to generalize to unseen data, highlighting challenges in robust vulnerability detection. This study benchmarks model performance, identifies limitations in generalization, and provides actionable insights to advance automated vulnerability patching for real-world security applications.
StyleMorpheus: A Style-Based 3D-Aware Morphable Face Model
Mar 14, 2025



For 3D face modeling, the recently developed 3D-aware neural rendering methods are able to render photorealistic face images with arbitrary viewing directions. The training of the parametric controllable 3D-aware face models, however, still relies on a large-scale dataset that is lab-collected. To address this issue, this paper introduces "StyleMorpheus", the first style-based neural 3D Morphable Face Model (3DMM) that is trained on in-the-wild images. It inherits 3DMM's disentangled controllability (over face identity, expression, and appearance) but without the need for accurately reconstructed explicit 3D shapes. StyleMorpheus employs an auto-encoder structure. The encoder aims at learning a representative disentangled parametric code space and the decoder improves the disentanglement using shape and appearance-related style codes in the different sub-modules of the network. Furthermore, we fine-tune the decoder through style-based generative adversarial learning to achieve photorealistic 3D rendering quality. The proposed style-based design enables StyleMorpheus to achieve state-of-the-art 3D-aware face reconstruction results, while also allowing disentangled control of the reconstructed face. Our model achieves real-time rendering speed, allowing its use in virtual reality applications. We also demonstrate the capability of the proposed style-based design in face editing applications such as style mixing and color editing. Project homepage: https://github.com/ubc-3d-vision-lab/StyleMorpheus.
Deep learning based infrared small object segmentation: Challenges and future directions
Feb 20, 2025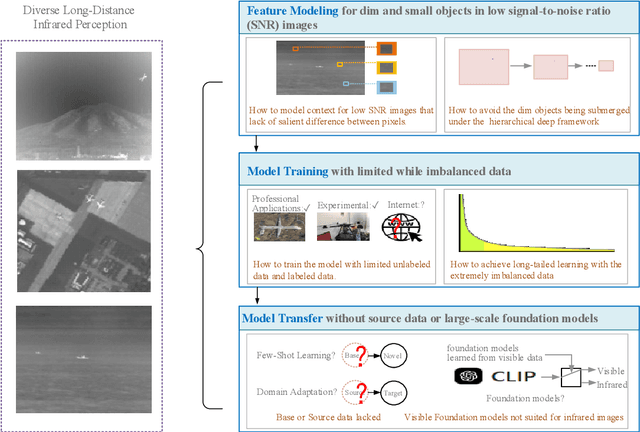

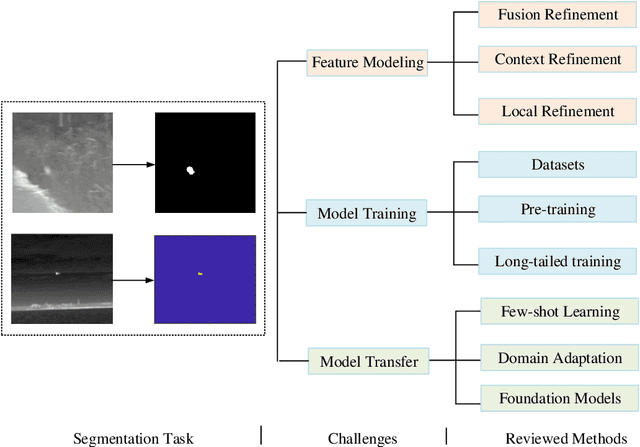

Infrared sensing is a core method for supporting unmanned systems, such as autonomous vehicles and drones. Recently, infrared sensors have been widely deployed on mobile and stationary platforms for detection and classification of objects from long distances and in wide field of views. Given its success in the vision image analysis domain, deep learning has also been applied for object recognition in infrared images. However, techniques that have proven successful in visible light perception face new challenges in the infrared domain. These challenges include extremely low signal-to-noise ratios in infrared images, very small and blurred objects of interest, and limited availability of labeled/unlabeled training data due to the specialized nature of infrared sensors. Numerous methods have been proposed in the literature for the detection and classification of small objects in infrared images achieving varied levels of success. There is a need for a survey paper that critically analyzes existing techniques in this domain, identifies unsolved challenges and provides future research directions. This paper fills the gap and offers a concise and insightful review of deep learning-based methods. It also identifies the challenges faced by existing infrared object segmentation methods and provides a structured review of existing infrared perception methods from the perspective of these challenges and highlights the motivations behind the various approaches. Finally, this review suggests promising future directions based on recent advancements within this domain.
Gaussian Deja-vu: Creating Controllable 3D Gaussian Head-Avatars with Enhanced Generalization and Personalization Abilities
Sep 26, 2024
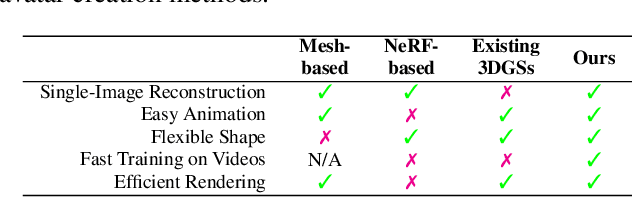


Recent advancements in 3D Gaussian Splatting (3DGS) have unlocked significant potential for modeling 3D head avatars, providing greater flexibility than mesh-based methods and more efficient rendering compared to NeRF-based approaches. Despite these advancements, the creation of controllable 3DGS-based head avatars remains time-intensive, often requiring tens of minutes to hours. To expedite this process, we here introduce the ``Gaussian D\'ej\`a-vu" framework, which first obtains a generalized model of the head avatar and then personalizes the result. The generalized model is trained on large 2D (synthetic and real) image datasets. This model provides a well-initialized 3D Gaussian head that is further refined using a monocular video to achieve the personalized head avatar. For personalizing, we propose learnable expression-aware rectification blendmaps to correct the initial 3D Gaussians, ensuring rapid convergence without the reliance on neural networks. Experiments demonstrate that the proposed method meets its objectives. It outperforms state-of-the-art 3D Gaussian head avatars in terms of photorealistic quality as well as reduces training time consumption to at least a quarter of the existing methods, producing the avatar in minutes.
One-Shot Learning for Pose-Guided Person Image Synthesis in the Wild
Sep 15, 2024



Current Pose-Guided Person Image Synthesis (PGPIS) methods depend heavily on large amounts of labeled triplet data to train the generator in a supervised manner. However, they often falter when applied to in-the-wild samples, primarily due to the distribution gap between the training datasets and real-world test samples. While some researchers aim to enhance model generalizability through sophisticated training procedures, advanced architectures, or by creating more diverse datasets, we adopt the test-time fine-tuning paradigm to customize a pre-trained Text2Image (T2I) model. However, naively applying test-time tuning results in inconsistencies in facial identities and appearance attributes. To address this, we introduce a Visual Consistency Module (VCM), which enhances appearance consistency by combining the face, text, and image embedding. Our approach, named OnePoseTrans, requires only a single source image to generate high-quality pose transfer results, offering greater stability than state-of-the-art data-driven methods. For each test case, OnePoseTrans customizes a model in around 48 seconds with an NVIDIA V100 GPU.
Towards Secure and Usable 3D Assets: A Novel Framework for Automatic Visible Watermarking
Aug 31, 2024



3D models, particularly AI-generated ones, have witnessed a recent surge across various industries such as entertainment. Hence, there is an alarming need to protect the intellectual property and avoid the misuse of these valuable assets. As a viable solution to address these concerns, we rigorously define the novel task of automated 3D visible watermarking in terms of two competing aspects: watermark quality and asset utility. Moreover, we propose a method of embedding visible watermarks that automatically determines the right location, orientation, and number of watermarks to be placed on arbitrary 3D assets for high watermark quality and asset utility. Our method is based on a novel rigid-body optimization that uses back-propagation to automatically learn transforms for ideal watermark placement. In addition, we propose a novel curvature-matching method for fusing the watermark into the 3D model that further improves readability and security. Finally, we provide a detailed experimental analysis on two benchmark 3D datasets validating the superior performance of our approach in comparison to baselines. Code and demo are available.