 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Learning for Pose-Guided Person Image Synthesis in the Wild
Sep 15, 2024



Current Pose-Guided Person Image Synthesis (PGPIS) methods depend heavily on large amounts of labeled triplet data to train the generator in a supervised manner. However, they often falter when applied to in-the-wild samples, primarily due to the distribution gap between the training datasets and real-world test samples. While some researchers aim to enhance model generalizability through sophisticated training procedures, advanced architectures, or by creating more diverse datasets, we adopt the test-time fine-tuning paradigm to customize a pre-trained Text2Image (T2I) model. However, naively applying test-time tuning results in inconsistencies in facial identities and appearance attributes. To address this, we introduce a Visual Consistency Module (VCM), which enhances appearance consistency by combining the face, text, and image embedding. Our approach, named OnePoseTrans, requires only a single source image to generate high-quality pose transfer results, offering greater stability than state-of-the-art data-driven methods. For each test case, OnePoseTrans customizes a model in around 48 seconds with an NVIDIA V100 GPU.
ConStyle v2: A Strong Prompter for All-in-One Image Restoration
Jun 26, 2024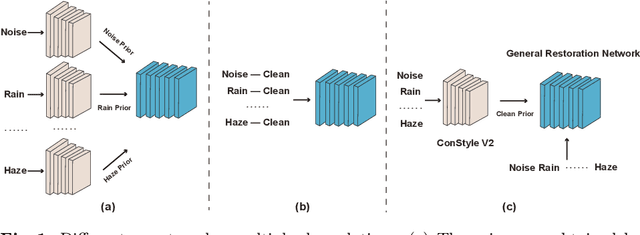
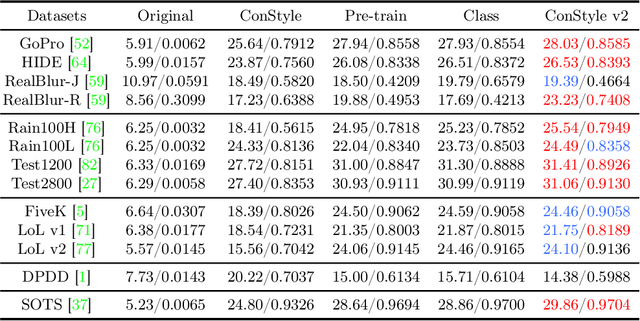
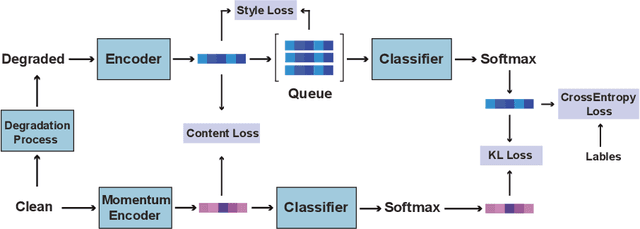
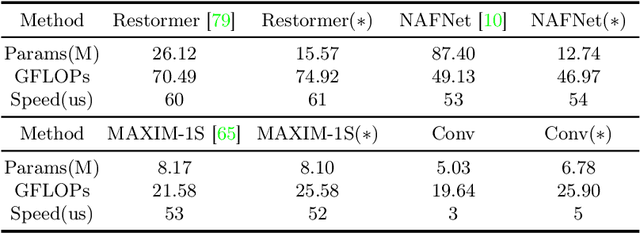
This paper introduces ConStyle v2, a strong plug-and-play prompter designed to output clean visual prompts and assist U-Net Image Restoration models in handling multiple degradations. The joint training process of IRConStyle, an Image Restoration framework consisting of ConStyle and a general restoration network, is divided into two stages: first, pre-training ConStyle alone, and then freezing its weights to guide the training of the general restoration network. Three improvements are proposed in the pre-training stage to train ConStyle: unsupervised pre-training, adding a pretext task (i.e. classification), and adopting knowledge distillation. Without bells and whistles, we can get ConStyle v2, a strong prompter for all-in-one Image Restoration, in less than two GPU days and doesn't require any fine-tuning. Extensive experiments on Restormer (transformer-based), NAFNet (CNN-based), MAXIM-1S (MLP-based), and a vanilla CNN network demonstrate that ConStyle v2 can enhance any U-Net style Image Restoration models to all-in-one Image Restoration models. Furthermore, models guided by the well-trained ConStyle v2 exhibit superior performance in some specific degradation compared to ConStyle.
IRConStyle: Image Restoration Framework Using Contrastive Learning and Style Transfer
Mar 07, 2024
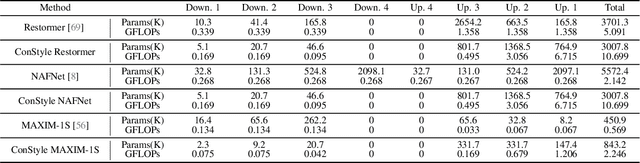
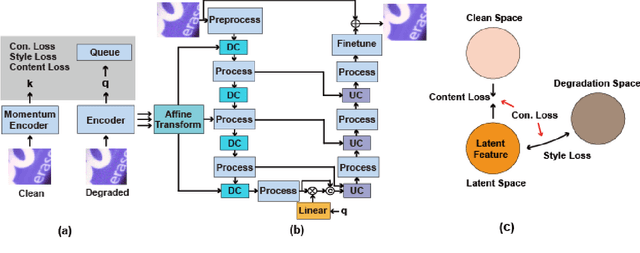
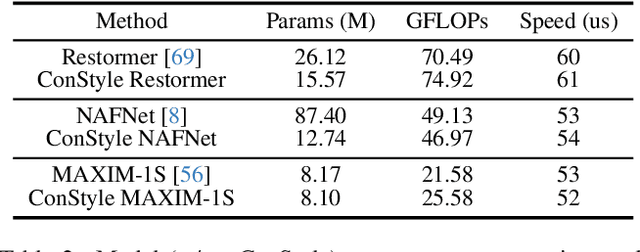
Recently, the contrastive learning paradigm has achieved remarkable success in high-level tasks such as classification, detection, and segmentation. However, contrastive learning applied in low-level tasks, like image restoration, is limited, and its effectiveness is uncertain. This raises a question: Why does the contrastive learning paradigm not yield satisfactory results in image restoration? In this paper, we conduct in-depth analyses and propose three guidelines to address the above question. In addition, inspired by style transfer and based on contrastive learning, we propose a novel module for image restoration called \textbf{ConStyle}, which can be efficiently integrated into any U-Net structure network. By leveraging the flexibility of ConStyle, we develop a \textbf{general restoration network} for image restoration. ConStyle and the general restoration network together form an image restoration framework, namely \textbf{IRConStyle}. To demonstrate the capability and compatibility of ConStyle, we replace the general restoration network with transformer-based, CNN-based, and MLP-based networks, respectively. We perform extensive experiments on various image restoration tasks, including denoising, deblurring, deraining, and dehazing. The results on 19 benchmarks demonstrate that ConStyle can be integrated with any U-Net-based network and significantly enhance performance. For instance, ConStyle NAFNet significantly outperforms the original NAFNet on SOTS outdoor (dehazing) and Rain100H (deraining) datasets, with PSNR improvements of 4.16 dB and 3.58 dB with 85% fewer parameters.
LIR: Efficient Degradation Removal for Lightweight Image Restoration
Feb 02, 2024



Recently, there have been significant advancements in Image Restoration based on CNN and transformer. However, the inherent characteristics of the Image Restoration task are often overlooked in many works. These works often focus on the basic block design and stack numerous basic blocks to the model, leading to redundant parameters and unnecessary computations and hindering the efficiency of the image restoration. In this paper, we propose a Lightweight Image Restoration network called LIR to efficiently remove degradation (blur, rain, noise, haze, etc.). A key component in LIR is the Efficient Adaptive Attention (EAA) Block, which is mainly composed of Adaptive Filters and Attention Blocks. It is capable of adaptively sharpening contours, removing degradation, and capturing global information in various image restoration scenes in an efficient and computation-friendly manner. In addition, through a simple structural design, LIR addresses the degradations existing in the local and global residual connections that are ignored by modern networks. Extensive experiments demonstrate that our LIR achieves comparable performance to state-of-the-art networks on most benchmarks with fewer parameters and computations. It is worth noting that our LIR produces better visual results than state-of-the-art networks that are more in line with the human aesthetic.