 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysLayer: Language-Guided Layered Animation with Depth-Aware Physics
Apr 26, 2026Existing image-to-video generation methods often produce physically implausible motions and lack precise control over object dynamics. While prior approaches have incorporated physics simulators, they remain confined to 2D planar motions and fail to capture depth-aware spatial interactions. We introduce PhysLayer, a novel framework enabling language-guided, depth-aware layered animation of static images. PhysLayer consists of three key components: First, a language-guided scene understanding module that utilizes vision foundation models to decompose scenes into depth-based layers by analyzing object composition, material properties, and physical parameters. Second, a depth-aware layered physics simulation that extends 2D rigid-body dynamics with depth motion and perspective-consistent scaling, enabling more realistic object interactions without requiring full 3D reconstruction. Third, a physics-guided video synthesis module that integrates simulated trajectories with scene-aware relighting for temporally coherent results. Experimental results demonstrate improvements in CLIP-Similarity (+2.2\%), FID score (+9.3\%), and Motion-FID (+3\%), with human evaluation showing enhanced physical plausibility (+24\%) and text-video alignment (+35\%). Our approach provides a practical balance between physical realism and computational efficiency for controllable image animation.
High-fidelity 3D Gaussian Inpainting: preserving multi-view consistency and photorealistic details
Jul 24, 2025Recent advancements in multi-view 3D reconstruction and novel-view synthesis, particularly through Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have greatly enhanced the fidelity and efficiency of 3D content creation. However, inpainting 3D scenes remains a challenging task due to the inherent irregularity of 3D structures and the critical need for maintaining multi-view consistency. In this work, we propose a novel 3D Gaussian inpainting framework that reconstructs complete 3D scenes by leveraging sparse inpainted views. Our framework incorporates an automatic Mask Refinement Process and region-wise Uncertainty-guided Optimization. Specifically, we refine the inpainting mask using a series of operations, including Gaussian scene filtering and back-projection, enabling more accurate localization of occluded regions and realistic boundary restoration. Furthermore, our Uncertainty-guided Fine-grained Optimization strategy, which estimates the importance of each region across multi-view images during training, alleviates multi-view inconsistencies and enhances the fidelity of fine details in the inpainted results. Comprehensive experiments conducted on diverse datasets demonstrate that our approach outperforms existing state-of-the-art methods in both visual quality and view consistency.
One-Shot Learning for Pose-Guided Person Image Synthesis in the Wild
Sep 15, 2024



Current Pose-Guided Person Image Synthesis (PGPIS) methods depend heavily on large amounts of labeled triplet data to train the generator in a supervised manner. However, they often falter when applied to in-the-wild samples, primarily due to the distribution gap between the training datasets and real-world test samples. While some researchers aim to enhance model generalizability through sophisticated training procedures, advanced architectures, or by creating more diverse datasets, we adopt the test-time fine-tuning paradigm to customize a pre-trained Text2Image (T2I) model. However, naively applying test-time tuning results in inconsistencies in facial identities and appearance attributes. To address this, we introduce a Visual Consistency Module (VCM), which enhances appearance consistency by combining the face, text, and image embedding. Our approach, named OnePoseTrans, requires only a single source image to generate high-quality pose transfer results, offering greater stability than state-of-the-art data-driven methods. For each test case, OnePoseTrans customizes a model in around 48 seconds with an NVIDIA V100 GPU.
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Apr 14, 2024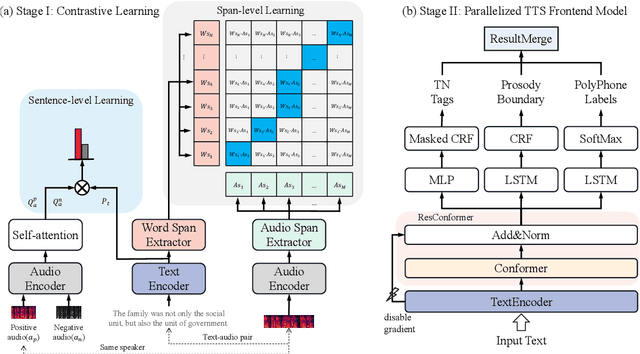
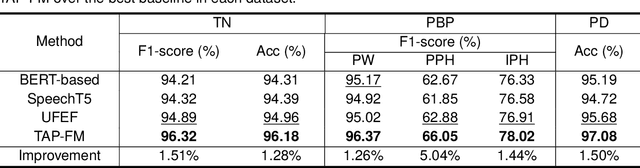

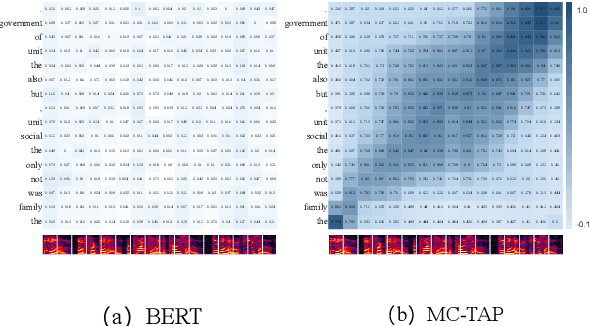
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
Enhancing Zero-shot Counting via Language-guided Exemplar Learning
Feb 08, 2024Recently, Class-Agnostic Counting (CAC) problem has garnered increasing attention owing to its intriguing generality and superior efficiency compared to Category-Specific Counting (CSC). This paper proposes a novel ExpressCount to enhance zero-shot object counting by delving deeply into language-guided exemplar learning. Specifically, the ExpressCount is comprised of an innovative Language-oriented Exemplar Perceptron and a downstream visual Zero-shot Counting pipeline. Thereinto, the perceptron hammers at exploiting accurate exemplar cues from collaborative language-vision signals by inheriting rich semantic priors from the prevailing pre-trained Large Language Models (LLMs), whereas the counting pipeline excels in mining fine-grained features through dual-branch and cross-attention schemes, contributing to the high-quality similarity learning. Apart from building a bridge between the LLM in vogue and the visual counting tasks, expression-guided exemplar estimation significantly advances zero-shot learning capabilities for counting instances with arbitrary classes. Moreover, devising a FSC-147-Express with annotations of meticulous linguistic expressions pioneers a new venue for developing and validating language-based counting models. Extensive experiments demonstrate the state-of-the-art performance of our ExpressCount, even showcasing the accuracy on par with partial CSC models.
GazeCLIP: Towards Enhancing Gaze Estimation via Text Guidance
Jan 07, 2024



Over the past decade, visual gaze estimation has garnered growing attention within the research community, thanks to its wide-ranging application scenarios. While existing estimation approaches have achieved remarkable success in enhancing prediction accuracy, they primarily infer gaze directions from single-image signals and discard the huge potentials of the currently dominant text guidance. Notably, visual-language collaboration has been extensively explored across a range of visual tasks, such as image synthesis and manipulation, leveraging the remarkable transferability of large-scale Contrastive Language-Image Pre-training (CLIP) model. Nevertheless, existing gaze estimation approaches ignore the rich semantic cues conveyed by linguistic signals and priors in CLIP feature space, thereby yielding performance setbacks. In pursuit of making up this gap, we delve deeply into the text-eye collaboration protocol and introduce a novel gaze estimation framework in this paper, referred to as GazeCLIP. Specifically, we intricately design a linguistic description generator to produce text signals with coarse directional cues. Additionally, a CLIP-based backbone that excels in characterizing text-eye pairs for gaze estimation is presented. This is followed by the implementation of a fine-grained multi-modal fusion module aimed at modeling the interrelationships between heterogeneous inputs. Extensive experiments on three challenging datasets demonstrate the superiority of the proposed GazeCLIP which surpasses the previous approaches and achieves the state-of-the-art estimation accuracy.
Fine-grained Text and Image Guided Point Cloud Completion with CLIP Model
Aug 17, 2023



This paper focuses on the recently popular task of point cloud completion guided by multimodal information. Although existing methods have achieved excellent performance by fusing auxiliary images, there are still some deficiencies, including the poor generalization ability of the model and insufficient fine-grained semantic information for extracted features. In this work, we propose a novel multimodal fusion network for point cloud completion, which can simultaneously fuse visual and textual information to predict the semantic and geometric characteristics of incomplete shapes effectively. Specifically, to overcome the lack of prior information caused by the small-scale dataset, we employ a pre-trained vision-language model that is trained with a large amount of image-text pairs. Therefore, the textual and visual encoders of this large-scale model have stronger generalization ability. Then, we propose a multi-stage feature fusion strategy to fuse the textual and visual features into the backbone network progressively. Meanwhile, to further explore the effectiveness of fine-grained text descriptions for point cloud completion, we also build a text corpus with fine-grained descriptions, which can provide richer geometric details for 3D shapes. The rich text descriptions can be used for training and evaluating our network. Extensive quantitative and qualitative experiments demonstrate the superior performance of our method compared to state-of-the-art point cloud completion networks.
CPNet: Exploiting CLIP-based Attention Condenser and Probability Map Guidance for High-fidelity Talking Face Generation
May 23, 2023



Recently, talking face generation has drawn ever-increasing attention from the research community in computer vision due to its arduous challenges and widespread application scenarios, e.g. movie animation and virtual anchor. Although persevering efforts have been undertaken to enhance the fidelity and lip-sync quality of generated talking face videos, there is still large room for further improvements of synthesis quality and efficiency. Actually, these attempts somewhat ignore the explorations of fine-granularity feature extraction/integration and the consistency between probability distributions of landmarks, thereby recurring the issues of local details blurring and degraded fidelity. To mitigate these dilemmas, in this paper, a novel CLIP-based Attention and Probability Map Guided Network (CPNet) is delicately designed for inferring high-fidelity talking face videos. Specifically, considering the demands of fine-grained feature recalibration, a clip-based attention condenser is exploited to transfer knowledge with rich semantic priors from the prevailing CLIP model. Moreover, to guarantee the consistency in probability space and suppress the landmark ambiguity, we creatively propose the density map of facial landmark as auxiliary supervisory signal to guide the landmark distribution learning of generated frame. Extensive experiments on the widely-used benchmark dataset demonstrate the superiority of our CPNet against state of the arts in terms of image and lip-sync quality. In addition, a cohort of studies are also conducted to ablate the impacts of the individual pivotal components.
FER-former: Multi-modal Transformer for Facial Expression Recognition
Mar 23, 2023



The ever-increasing demands for intuitive interactions in Virtual Reality has triggered a boom in the realm of Facial Expression Recognition (FER). To address the limitations in existing approaches (e.g., narrow receptive fields and homogenous supervisory signals) and further cement the capacity of FER tools, a novel multifarious supervision-steering Transformer for FER in the wild is proposed in this paper. Referred as FER-former, our approach features multi-granularity embedding integration, hybrid self-attention scheme, and heterogeneous domain-steering supervision. In specific, to dig deep into the merits of the combination of features provided by prevailing CNNs and Transformers, a hybrid stem is designed to cascade two types of learning paradigms simultaneously. Wherein, a FER-specific transformer mechanism is devised to characterize conventional hard one-hot label-focusing and CLIP-based text-oriented tokens in parallel for final classification. To ease the issue of annotation ambiguity, a heterogeneous domains-steering supervision module is proposed to make image features also have text-space semantic correlations by supervising the similarity between image features and text features. On top of the collaboration of multifarious token heads, diverse global receptive fields with multi-modal semantic cues are captured, thereby delivering superb learning capability. Extensive experiments on popular benchmarks demonstrate the superiority of the proposed FER-former over the existing state-of-the-arts.
GCNet: Probing Self-Similarity Learning for Generalized Counting Network
Feb 10, 2023



The class-agnostic counting (CAC) problem has caught increasing attention recently due to its wide societal applications and arduous challenges. To count objects of different categories, existing approaches rely on user-provided exemplars, which is hard-to-obtain and limits their generality. In this paper, we aim to empower the framework to recognize adaptive exemplars within the whole images. A zero-shot Generalized Counting Network (GCNet) is developed, which uses a pseudo-Siamese structure to automatically and effectively learn pseudo exemplar clues from inherent repetition patterns. In addition, a weakly-supervised scheme is presented to reduce the burden of laborious density maps required by all contemporary CAC models, allowing GCNet to be trained using count-level supervisory signals in an end-to-end manner. Without providing any spatial location hints, GCNet is capable of adaptively capturing them through a carefully-designed self-similarity learning strategy. Extensive experiments and ablation studies on the prevailing benchmark FSC147 for zero-shot CAC demonstrate the superiority of our GCNet. It performs on par with existing exemplar-dependent methods and shows stunning cross-dataset generality on crowd-specific datasets, e.g., ShanghaiTech Part A, Part B and UCF_QNRF.