 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Spatial Reasoning by Mobile Robots for Reconstruction and Navigation in Dynamic LiDAR Scenes
May 18, 2025



Our brain has an inner global positioning system which enables us to sense and navigate 3D spaces in real time. Can mobile robots replicate such a biological feat in a dynamic environment? We introduce the first spatial reasoning framework for real-time surface reconstruction and navigation that is designed for outdoor LiDAR scanning data captured by ground mobile robots and capable of handling moving objects such as pedestrians. Our reconstruction-based approach is well aligned with the critical cellular functions performed by the border vector cells (BVCs) over all layers of the medial entorhinal cortex (MEC) for surface sensing and tracking. To address the challenges arising from blurred boundaries resulting from sparse single-frame LiDAR points and outdated data due to object movements, we integrate real-time single-frame mesh reconstruction, via visibility reasoning, with robot navigation assistance through on-the-fly 3D free space determination. This enables continuous and incremental updates of the scene and free space across multiple frames. Key to our method is the utilization of line-of-sight (LoS) vectors from LiDAR, which enable real-time surface normal estimation, as well as robust and instantaneous per-voxel free space updates. We showcase two practical applications: real-time 3D scene reconstruction and autonomous outdoor robot navigation in real-world conditions. Comprehensive experiments on both synthetic and real scenes highlight our method's superiority in speed and quality over existing real-time LiDAR processing approaches.
ArcPro: Architectural Programs for Structured 3D Abstraction of Sparse Points
Mar 05, 2025We introduce ArcPro, a novel learning framework built on architectural programs to recover structured 3D abstractions from highly sparse and low-quality point clouds. Specifically, we design a domain-specific language (DSL) to hierarchically represent building structures as a program, which can be efficiently converted into a mesh. We bridge feedforward and inverse procedural modeling by using a feedforward process for training data synthesis, allowing the network to make reverse predictions. We train an encoder-decoder on the points-program pairs to establish a mapping from unstructured point clouds to architectural programs, where a 3D convolutional encoder extracts point cloud features and a transformer decoder autoregressively predicts the programs in a tokenized form. Inference by our method is highly efficient and produces plausible and faithful 3D abstractions. Comprehensive experiments demonstrate that ArcPro outperforms both traditional architectural proxy reconstruction and learning-based abstraction methods. We further explore its potential to work with multi-view image and natural language inputs.
Systematic Literature Review of Vision-Based Approaches to Outdoor Livestock Monitoring with Lessons from Wildlife Studies
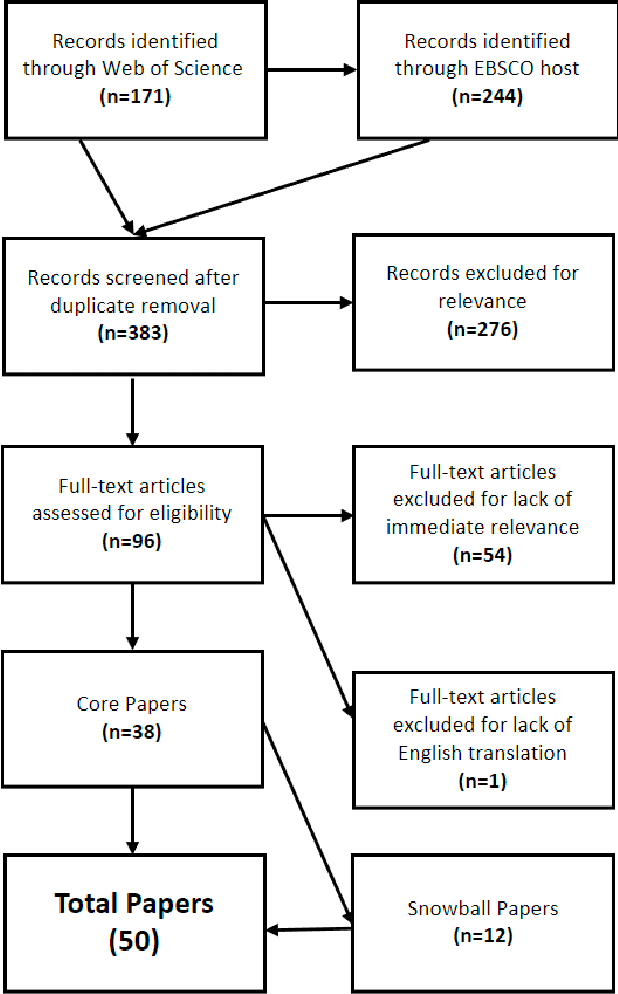
Oct 07, 2024

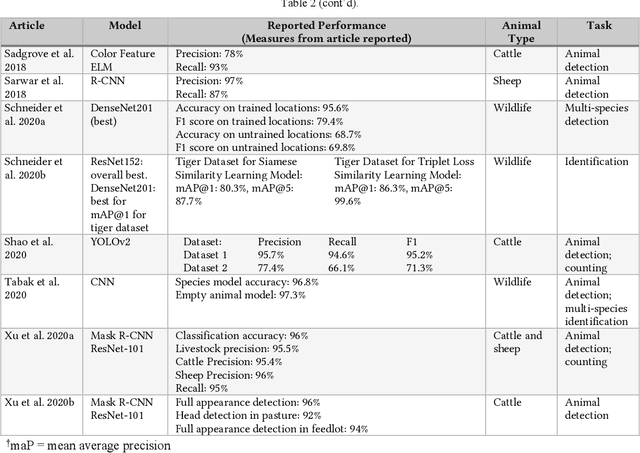
Precision livestock farming (PLF) aims to improve the health and welfare of livestock animals and farming outcomes through the use of advanced technologies. Computer vision, combined with recent advances in machine learning and deep learning artificial intelligence approaches, offers a possible solution to the PLF ideal of 24/7 livestock monitoring that helps facilitate early detection of animal health and welfare issues. However, a significant number of livestock species are raised in large outdoor habitats that pose technological challenges for computer vision approaches. This review provides a comprehensive overview of computer vision methods and open challenges in outdoor animal monitoring. We include research from both the livestock and wildlife fields in the review because of the similarities in appearance, behaviour, and habitat for many livestock and wildlife. We focus on large terrestrial mammals, such as cattle, horses, deer, goats, sheep, koalas, giraffes, and elephants. We use an image processing pipeline to frame our discussion and highlight the current capabilities and open technical challenges at each stage of the pipeline. The review found a clear trend towards the use of deep learning approaches for animal detection, counting, and multi-species classification. We discuss in detail the applicability of current vision-based methods to PLF contexts and promising directions for future research.
Textured-GS: Gaussian Splatting with Spatially Defined Color and Opacity
Jul 13, 2024
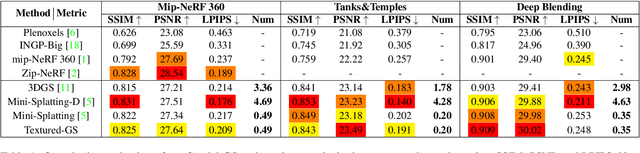
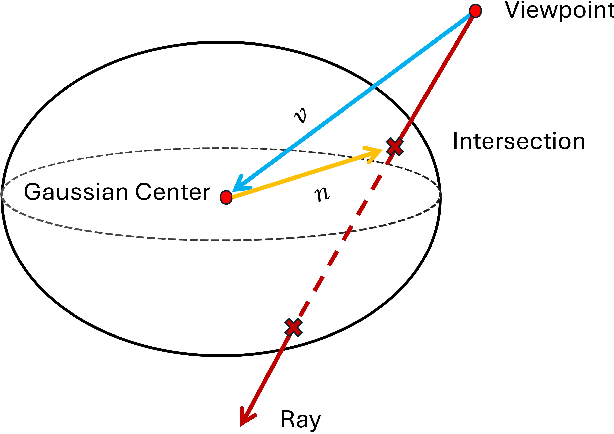
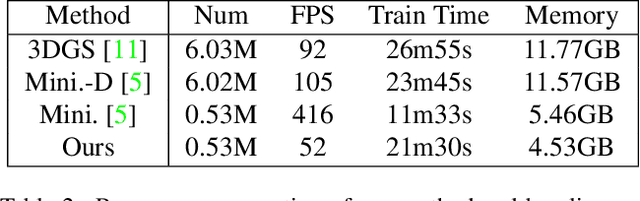
In this paper, we introduce Textured-GS, an innovative method for rendering Gaussian splatting that incorporates spatially defined color and opacity variations using Spherical Harmonics (SH). This approach enables each Gaussian to exhibit a richer representation by accommodating varying colors and opacities across its surface, significantly enhancing rendering quality compared to traditional methods. To demonstrate the merits of our approach, we have adapted the Mini-Splatting architecture to integrate textured Gaussians without increasing the number of Gaussians. Our experiments across multiple real-world datasets show that Textured-GS consistently outperforms both the baseline Mini-Splatting and standard 3DGS in terms of visual fidelity. The results highlight the potential of Textured-GS to advance Gaussian-based rendering technologies, promising more efficient and high-quality scene reconstructions.
SealD-NeRF: Interactive Pixel-Level Editing for Dynamic Scenes by Neural Radiance Fields
Feb 21, 2024



The widespread adoption of implicit neural representations, especially Neural Radiance Fields (NeRF), highlights a growing need for editing capabilities in implicit 3D models, essential for tasks like scene post-processing and 3D content creation. Despite previous efforts in NeRF editing, challenges remain due to limitations in editing flexibility and quality. The key issue is developing a neural representation that supports local edits for real-time updates. Current NeRF editing methods, offering pixel-level adjustments or detailed geometry and color modifications, are mostly limited to static scenes. This paper introduces SealD-NeRF, an extension of Seal-3D for pixel-level editing in dynamic settings, specifically targeting the D-NeRF network. It allows for consistent edits across sequences by mapping editing actions to a specific timeframe, freezing the deformation network responsible for dynamic scene representation, and using a teacher-student approach to integrate changes.
Enhancing Zero-shot Counting via Language-guided Exemplar Learning
Feb 08, 2024Recently, Class-Agnostic Counting (CAC) problem has garnered increasing attention owing to its intriguing generality and superior efficiency compared to Category-Specific Counting (CSC). This paper proposes a novel ExpressCount to enhance zero-shot object counting by delving deeply into language-guided exemplar learning. Specifically, the ExpressCount is comprised of an innovative Language-oriented Exemplar Perceptron and a downstream visual Zero-shot Counting pipeline. Thereinto, the perceptron hammers at exploiting accurate exemplar cues from collaborative language-vision signals by inheriting rich semantic priors from the prevailing pre-trained Large Language Models (LLMs), whereas the counting pipeline excels in mining fine-grained features through dual-branch and cross-attention schemes, contributing to the high-quality similarity learning. Apart from building a bridge between the LLM in vogue and the visual counting tasks, expression-guided exemplar estimation significantly advances zero-shot learning capabilities for counting instances with arbitrary classes. Moreover, devising a FSC-147-Express with annotations of meticulous linguistic expressions pioneers a new venue for developing and validating language-based counting models. Extensive experiments demonstrate the state-of-the-art performance of our ExpressCount, even showcasing the accuracy on par with partial CSC models.
GRIG: Few-Shot Generative Residual Image Inpainting
Apr 24, 2023



Image inpainting is the task of filling in missing or masked region of an image with semantically meaningful contents. Recent methods have shown significant improvement in dealing with large-scale missing regions. However, these methods usually require large training datasets to achieve satisfactory results and there has been limited research into training these models on a small number of samples. To address this, we present a novel few-shot generative residual image inpainting method that produces high-quality inpainting results. The core idea is to propose an iterative residual reasoning method that incorporates Convolutional Neural Networks (CNNs) for feature extraction and Transformers for global reasoning within generative adversarial networks, along with image-level and patch-level discriminators. We also propose a novel forgery-patch adversarial training strategy to create faithful textures and detailed appearances. Extensive evaluations show that our method outperforms previous methods on the few-shot image inpainting task, both quantitatively and qualitatively.
FER-former: Multi-modal Transformer for Facial Expression Recognition
Mar 23, 2023



The ever-increasing demands for intuitive interactions in Virtual Reality has triggered a boom in the realm of Facial Expression Recognition (FER). To address the limitations in existing approaches (e.g., narrow receptive fields and homogenous supervisory signals) and further cement the capacity of FER tools, a novel multifarious supervision-steering Transformer for FER in the wild is proposed in this paper. Referred as FER-former, our approach features multi-granularity embedding integration, hybrid self-attention scheme, and heterogeneous domain-steering supervision. In specific, to dig deep into the merits of the combination of features provided by prevailing CNNs and Transformers, a hybrid stem is designed to cascade two types of learning paradigms simultaneously. Wherein, a FER-specific transformer mechanism is devised to characterize conventional hard one-hot label-focusing and CLIP-based text-oriented tokens in parallel for final classification. To ease the issue of annotation ambiguity, a heterogeneous domains-steering supervision module is proposed to make image features also have text-space semantic correlations by supervising the similarity between image features and text features. On top of the collaboration of multifarious token heads, diverse global receptive fields with multi-modal semantic cues are captured, thereby delivering superb learning capability. Extensive experiments on popular benchmarks demonstrate the superiority of the proposed FER-former over the existing state-of-the-arts.
Visibility-Aware Pixelwise View Selection for Multi-View Stereo Matching
Feb 14, 2023The performance of PatchMatch-based multi-view stereo algorithms depends heavily on the source views selected for computing matching costs. Instead of modeling the visibility of different views, most existing approaches handle occlusions in an ad-hoc manner. To address this issue, we propose a novel visibility-guided pixelwise view selection scheme in this paper. It progressively refines the set of source views to be used for each pixel in the reference view based on visibility information provided by already validated solutions. In addition, the Artificial Multi-Bee Colony (AMBC) algorithm is employed to search for optimal solutions for different pixels in parallel. Inter-colony communication is performed both within the same image and among different images. Fitness rewards are added to validated and propagated solutions, effectively enforcing the smoothness of neighboring pixels and allowing better handling of textureless areas. Experimental results on the DTU dataset show our method achieves state-of-the-art performance among non-learning-based methods and retrieves more details in occluded and low-textured regions.
GCNet: Probing Self-Similarity Learning for Generalized Counting Network
Feb 10, 2023The class-agnostic counting (CAC) problem has caught increasing attention recently due to its wide societal applications and arduous challenges. To count objects of different categories, existing approaches rely on user-provided exemplars, which is hard-to-obtain and limits their generality. In this paper, we aim to empower the framework to recognize adaptive exemplars within the whole images. A zero-shot Generalized Counting Network (GCNet) is developed, which uses a pseudo-Siamese structure to automatically and effectively learn pseudo exemplar clues from inherent repetition patterns. In addition, a weakly-supervised scheme is presented to reduce the burden of laborious density maps required by all contemporary CAC models, allowing GCNet to be trained using count-level supervisory signals in an end-to-end manner. Without providing any spatial location hints, GCNet is capable of adaptively capturing them through a carefully-designed self-similarity learning strategy. Extensive experiments and ablation studies on the prevailing benchmark FSC147 for zero-shot CAC demonstrate the superiority of our GCNet. It performs on par with existing exemplar-dependent methods and shows stunning cross-dataset generality on crowd-specific datasets, e.g., ShanghaiTech Part A, Part B and UCF_QNRF.