 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaintNeSF: Artistic Creation of Stylized Scenes with Vectorized 3D Strokes
Nov 27, 2023We present Paint Neural Stroke Field (PaintNeSF), a novel technique to generate stylized images of a 3D scene at arbitrary novel views from multi-view 2D images. Different from existing methods which apply stylization to trained neural radiance fields at the voxel level, our approach draws inspiration from image-to-painting methods, simulating the progressive painting process of human artwork with vector strokes. We develop a palette of stylized 3D strokes from basic primitives and splines, and consider the 3D scene stylization task as a multi-view reconstruction process based on these 3D stroke primitives. Instead of directly searching for the parameters of these 3D strokes, which would be too costly, we introduce a differentiable renderer that allows optimizing stroke parameters using gradient descent, and propose a training scheme to alleviate the vanishing gradient issue. The extensive evaluation demonstrates that our approach effectively synthesizes 3D scenes with significant geometric and aesthetic stylization while maintaining a consistent appearance across different views. Our method can be further integrated with style loss and image-text contrastive models to extend its applications, including color transfer and text-driven 3D scene drawing.
GRIG: Few-Shot Generative Residual Image Inpainting
Apr 24, 2023



Image inpainting is the task of filling in missing or masked region of an image with semantically meaningful contents. Recent methods have shown significant improvement in dealing with large-scale missing regions. However, these methods usually require large training datasets to achieve satisfactory results and there has been limited research into training these models on a small number of samples. To address this, we present a novel few-shot generative residual image inpainting method that produces high-quality inpainting results. The core idea is to propose an iterative residual reasoning method that incorporates Convolutional Neural Networks (CNNs) for feature extraction and Transformers for global reasoning within generative adversarial networks, along with image-level and patch-level discriminators. We also propose a novel forgery-patch adversarial training strategy to create faithful textures and detailed appearances. Extensive evaluations show that our method outperforms previous methods on the few-shot image inpainting task, both quantitatively and qualitatively.
Understanding the Vulnerability of Skeleton-based Human Activity Recognition via Black-box Attack
Nov 21, 2022



Human Activity Recognition (HAR) has been employed in a wide range of applications, e.g. self-driving cars, where safety and lives are at stake. Recently, the robustness of existing skeleton-based HAR methods has been questioned due to their vulnerability to adversarial attacks, which causes concerns considering the scale of the implication. However, the proposed attacks require the full-knowledge of the attacked classifier, which is overly restrictive. In this paper, we show such threats indeed exist, even when the attacker only has access to the input/output of the model. To this end, we propose the very first black-box adversarial attack approach in skeleton-based HAR called BASAR. BASAR explores the interplay between the classification boundary and the natural motion manifold. To our best knowledge, this is the first time data manifold is introduced in adversarial attacks on time series. Via BASAR, we find on-manifold adversarial samples are extremely deceitful and rather common in skeletal motions, in contrast to the common belief that adversarial samples only exist off-manifold. Through exhaustive evaluation, we show that BASAR can deliver successful attacks across classifiers, datasets, and attack modes. By attack, BASAR helps identify the potential causes of the model vulnerability and provides insights on possible improvements. Finally, to mitigate the newly identified threat, we propose a new adversarial training approach by leveraging the sophisticated distributions of on/off-manifold adversarial samples, called mixed manifold-based adversarial training (MMAT). MMAT can successfully help defend against adversarial attacks without compromising classification accuracy.
Gradient-based Point Cloud Denoising with Uniformity
Jul 21, 2022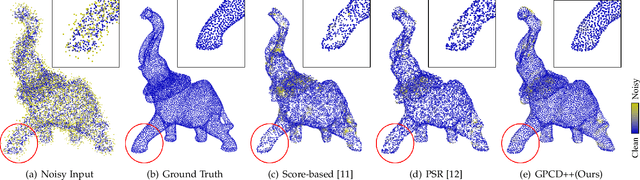
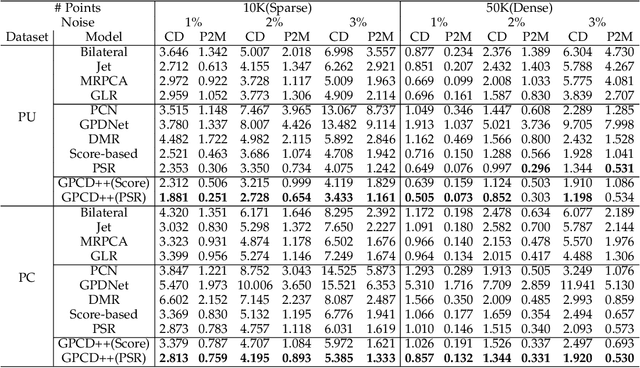
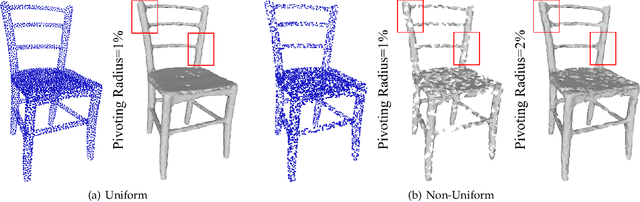
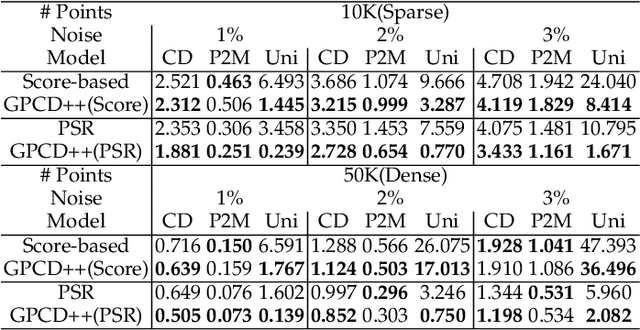
Point clouds captured by depth sensors are often contaminated by noises, obstructing further analysis and applications. In this paper, we emphasize the importance of point distribution uniformity to downstream tasks. We demonstrate that point clouds produced by existing gradient-based denoisers lack uniformity despite having achieved promising quantitative results. To this end, we propose GPCD++, a gradient-based denoiser with an ultra-lightweight network named UniNet to address uniformity. Compared with previous state-of-the-art methods, our approach not only generates competitive or even better denoising results, but also significantly improves uniformity which largely benefits applications such as surface reconstruction.
Parametric Reshaping of Portraits in Videos
May 05, 2022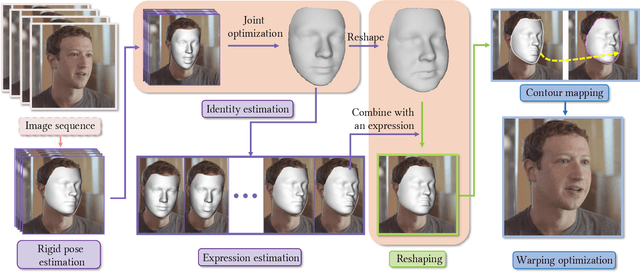

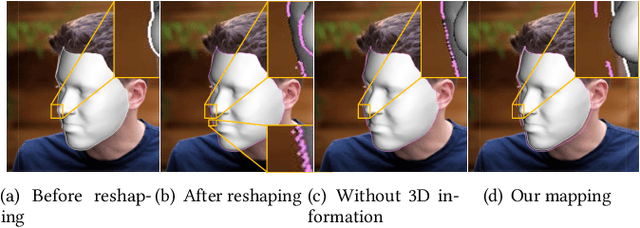

Sharing short personalized videos to various social media networks has become quite popular in recent years. This raises the need for digital retouching of portraits in videos. However, applying portrait image editing directly on portrait video frames cannot generate smooth and stable video sequences. To this end, we present a robust and easy-to-use parametric method to reshape the portrait in a video to produce smooth retouched results. Given an input portrait video, our method consists of two main stages: stabilized face reconstruction, and continuous video reshaping. In the first stage, we start by estimating face rigid pose transformations across video frames. Then we jointly optimize multiple frames to reconstruct an accurate face identity, followed by recovering face expressions over the entire video. In the second stage, we first reshape the reconstructed 3D face using a parametric reshaping model reflecting the weight change of the face, and then utilize the reshaped 3D face to guide the warping of video frames. We develop a novel signed distance function based dense mapping method for the warping between face contours before and after reshaping, resulting in stable warped video frames with minimum distortions. In addition, we use the 3D structure of the face to correct the dense mapping to achieve temporal consistency. We generate the final result by minimizing the background distortion through optimizing a content-aware warping mesh. Extensive experiments show that our method is able to create visually pleasing results by adjusting a simple reshaping parameter, which facilitates portrait video editing for social media and visual effects.
BASAR:Black-box Attack on Skeletal Action Recognition
Mar 19, 2021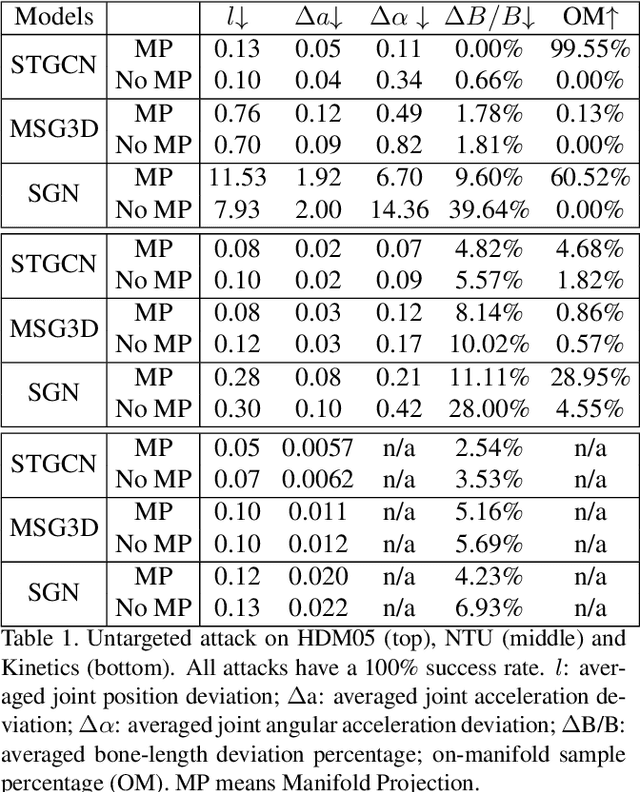
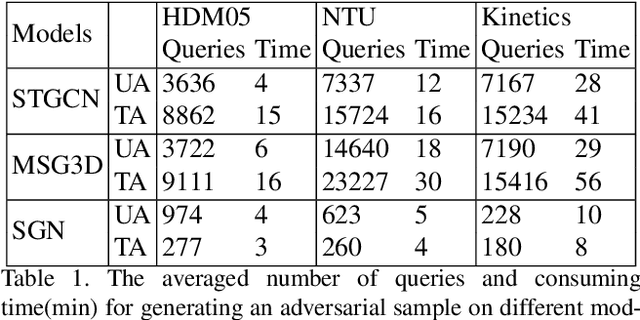
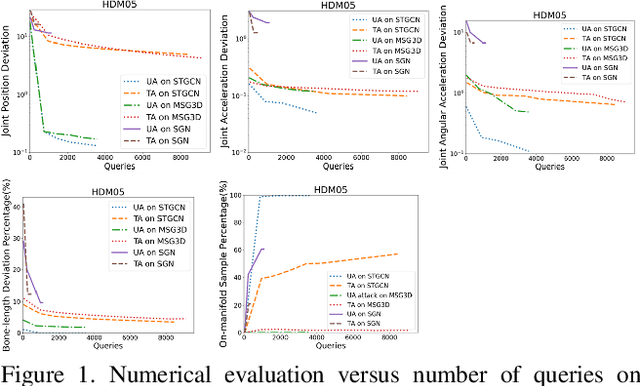
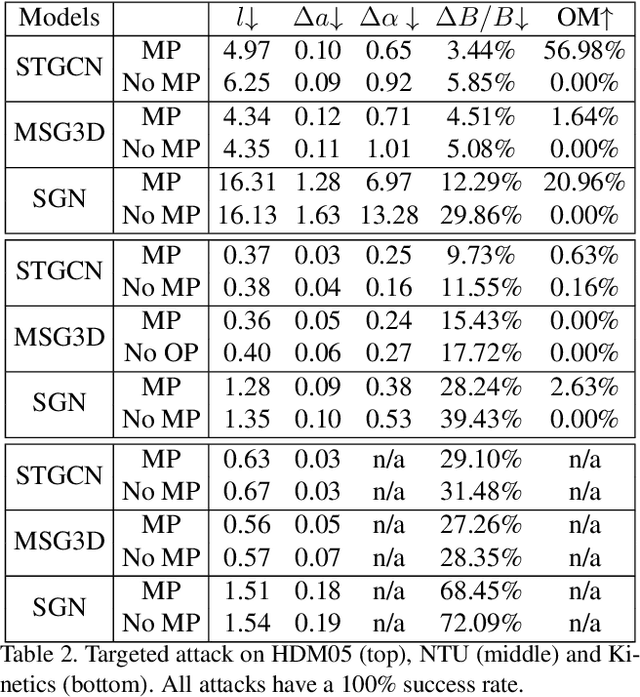
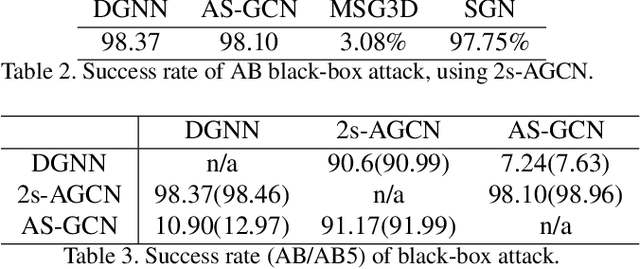
Skeletal motion plays a vital role in human activity recognition as either an independent data source or a complement. The robustness of skeleton-based activity recognizers has been questioned recently, which shows that they are vulnerable to adversarial attacks when the full-knowledge of the recognizer is accessible to the attacker. However, this white-box requirement is overly restrictive in most scenarios and the attack is not truly threatening. In this paper, we show that such threats do exist under black-box settings too. To this end, we propose the first black-box adversarial attack method BASAR. Through BASAR, we show that adversarial attack is not only truly a threat but also can be extremely deceitful, because on-manifold adversarial samples are rather common in skeletal motions, in contrast to the common belief that adversarial samples only exist off-manifold. Through exhaustive evaluation and comparison, we show that BASAR can deliver successful attacks across models, data, and attack modes. Through harsh perceptual studies, we show that it achieves effective yet imperceptible attacks. By analyzing the attack on different activity recognizers, BASAR helps identify the potential causes of their vulnerability and provides insights on what classifiers are likely to be more robust against attack.
Understanding the Robustness of Skeleton-based Action Recognition under Adversarial Attack
Mar 18, 2021
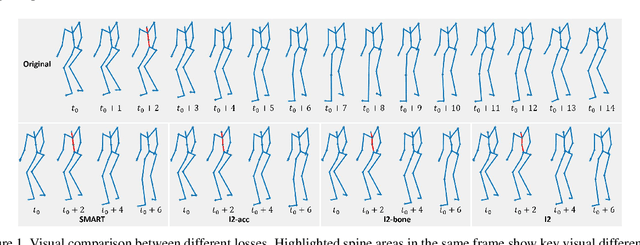
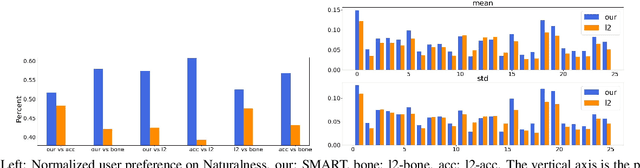
Action recognition has been heavily employed in many applications such as autonomous vehicles, surveillance, etc, where its robustness is a primary concern. In this paper, we examine the robustness of state-of-the-art action recognizers against adversarial attack, which has been rarely investigated so far. To this end, we propose a new method to attack action recognizers that rely on 3D skeletal motion. Our method involves an innovative perceptual loss that ensures the imperceptibility of the attack. Empirical studies demonstrate that our method is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Our method shows that adversarial attack on 3D skeletal motions, one type of time-series data, is significantly different from traditional adversarial attack problems. Its success raises serious concern on the robustness of action recognizers and provides insights on potential improvements.
Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation
Apr 09, 2020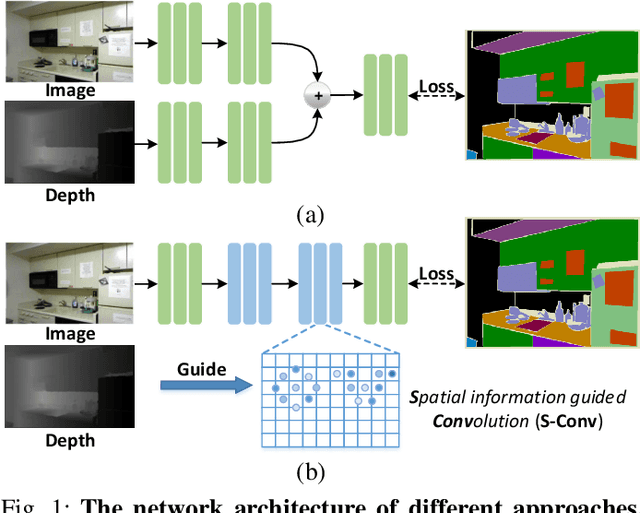
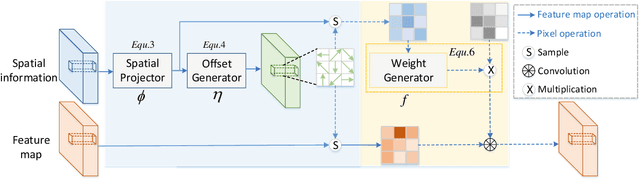
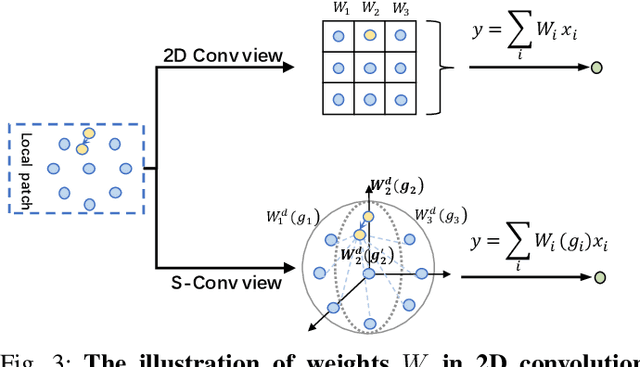
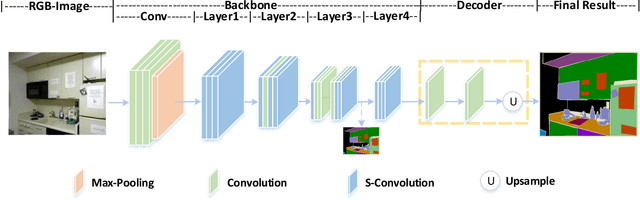
3D spatial information is known to be beneficial to the semantic segmentation task. Most existing methods take 3D spatial data as an additional input, leading to a two-stream segmentation network that processes RGB and 3D spatial information separately. This solution greatly increases the inference time and severely limits its scope for real-time applications. To solve this problem, we propose Spatial information guided Convolution (S-Conv), which allows efficient RGB feature and 3D spatial information integration. S-Conv is competent to infer the sampling offset of the convolution kernel guided by the 3D spatial information, helping the convolutional layer adjust the receptive field and adapt to geometric transformations. S-Conv also incorporates geometric information into the feature learning process by generating spatially adaptive convolutional weights. The capability of perceiving geometry is largely enhanced without much affecting the amount of parameters and computational cost. We further embed S-Conv into a semantic segmentation network, called Spatial information Guided convolutional Network (SGNet), resulting in real-time inference and state-of-the-art performance on NYUDv2 and SUNRGBD datasets.
BlockGAN: Learning 3D Object-aware Scene Representations from Unlabelled Images
Feb 26, 2020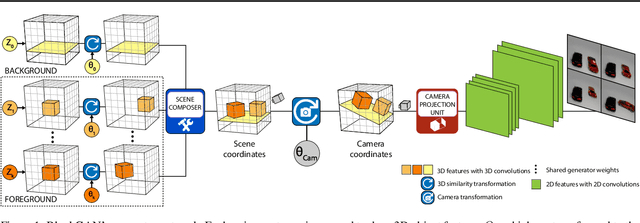
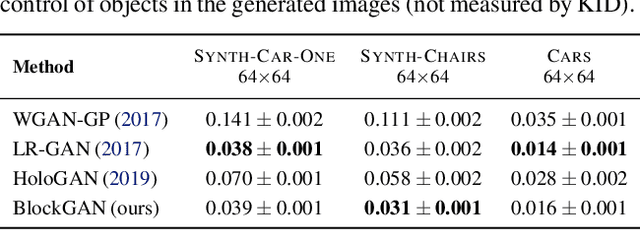
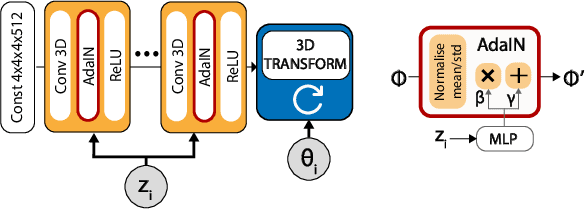

We present BlockGAN, an image generative model that learns object-aware 3D scene representations directly from unlabelled 2D images. Current work on scene representation learning either ignores scene background or treats the whole scene as one object. Meanwhile, work that considers scene compositionality treats scene objects only as image patches or 2D layers with alpha maps. Inspired by the computer graphics pipeline, we design BlockGAN to learn to first generate 3D features of background and foreground objects, then combine them into 3D features for the wholes cene, and finally render them into realistic images. This allows BlockGAN to reason over occlusion and interaction between objects' appearance, such as shadow and lighting, and provides control over each object's 3D pose and identity, while maintaining image realism. BlockGAN is trained end-to-end, using only unlabelled single images, without the need for 3D geometry, pose labels, object masks, or multiple views of the same scene. Our experiments show that using explicit 3D features to represent objects allows BlockGAN to learn disentangled representations both in terms of objects (foreground and background) and their properties (pose and identity).
Rank3DGAN: Semantic mesh generation using relative attributes
May 28, 2019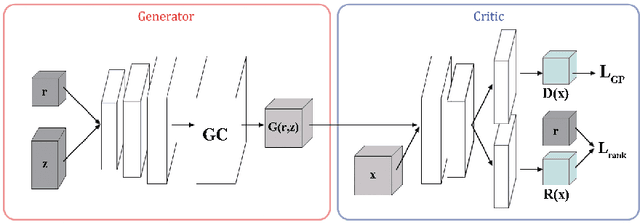

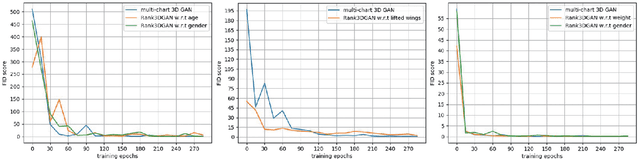
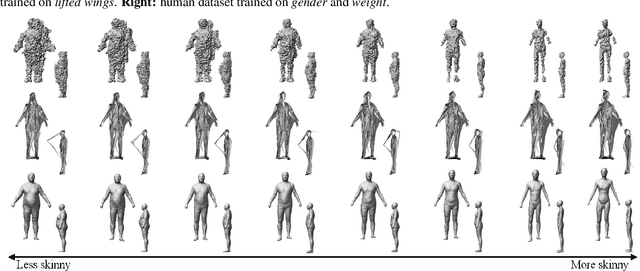
In this paper, we investigate a novel problem of using generative adversarial networks in the task of 3D shape generation according to semantic attributes. Recent works map 3D shapes into 2D parameter domain, which enables training Generative Adversarial Networks (GANs) for 3D shape generation task. We extend these architectures to the conditional setting, where we generate 3D shapes with respect to subjective attributes defined by the user. Given pairwise comparisons of 3D shapes, our model performs two tasks: it learns a generative model with a controlled latent space, and a ranking function for the 3D shapes based on their multi-chart representation in 2D. The capability of the model is demonstrated with experiments on HumanShape, Basel Face Model and reconstructed 3D CUB datasets. We also present various applications that benefit from our model, such as multi-attribute exploration, mesh editing, and mesh attribute transfer.