 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMWM: Intuition Models Complement World Models for Latent Planning
Jun 01, 2026Planning with a learned latent world model is a promising route to control from raw pixels, but a strong world model alone is not enough. We show this experimentally: even with a perfect world model (operationalized by replacing the learned forward predictor with an idealized rollout of the true environment dynamics), a finite-budget sample-based planner still fails on some tasks, indicating that the bottleneck can lie in search rather than in world-model accuracy. Motivated by this gap, we propose IMWM (Intuition Model + World Model), which pairs the world model with an intuition model trained from demonstrations to recognize promising actions. The two models collaborate through three lightweight components: (i) Retrieval Initialization, which initializes the planner's action proposal from a retrieved demonstration; (ii) Hybrid Cost, which combines the intuition score with the world-model rollout cost; and (iii) a Reliability Gate, which adjusts how much the planner trusts intuition in each setting. Across four pixel-based goal-reaching tasks (Two-Room, Reacher, Push-T, and OGBench-Cube), IMWM has higher mean success than the world-model-only planner on all four, with the largest gains on Two-Room (99.2%, +11.5 percentage points) and OGBench-Cube (94.7%, +28.5 percentage points).
Reward-Decomposed Reinforcement Learning for Immersive Video Role-Playing
May 06, 2026Text-based role-playing models can imitate character styles, yet they often fail to reflect a scene's atmosphere and evolving tension, both essential for immersive applications such as Virtual Reality (VR) games and interactive narratives. We study video-grounded role-playing dialogue and introduce EBM-RL (Eye-Brain-Mouth Reinforcement Learning), a decoupled GRPO-based framework that explicitly separates observation ([perception]), reasoning ([think]), and utterance ([answer]). This structure promotes human-like sensory grounding by compelling the model to first attend to visual cues, then form internal interpretations, and finally generate context-appropriate dialogue. EBM-RL integrates four complementary rewards: (i) CLIP-based scene-text alignment to improve ambiance and emotion; (ii) a Perceptual-Cognitive reward that encourages [perception] and [think] processes that increase the likelihood of the reference response; (iii) answer accuracy to ensure faithfulness; and (iv) a dense format reward to enforce the desired structured output. Extensive experiments demonstrate that EBM-RL substantially outperforms text-only role-playing baselines and larger-scale vision-language models on our immersive role-playing benchmark, delivering simultaneous gains in visual-atmosphere consistency and character authenticity. Beyond the role-playing domain, EBM-RL also exhibits strong zero-shot generalization: without any additional fine-tuning, it consistently improves performance on out-of-domain VideoQA benchmarks. We additionally release an open-source dataset for video-grounded role-playing dialogue.
Trifuse: Enhancing Attention-Based GUI Grounding via Multimodal Fusion
Feb 06, 2026GUI grounding maps natural language instructions to the correct interface elements, serving as the perception foundation for GUI agents. Existing approaches predominantly rely on fine-tuning multimodal large language models (MLLMs) using large-scale GUI datasets to predict target element coordinates, which is data-intensive and generalizes poorly to unseen interfaces. Recent attention-based alternatives exploit localization signals in MLLMs attention mechanisms without task-specific fine-tuning, but suffer from low reliability due to the lack of explicit and complementary spatial anchors in GUI images. To address this limitation, we propose Trifuse, an attention-based grounding framework that explicitly integrates complementary spatial anchors. Trifuse integrates attention, OCR-derived textual cues, and icon-level caption semantics via a Consensus-SinglePeak (CS) fusion strategy that enforces cross-modal agreement while retaining sharp localization peaks. Extensive evaluations on four grounding benchmarks demonstrate that Trifuse achieves strong performance without task-specific fine-tuning, substantially reducing the reliance on expensive annotated data. Moreover, ablation studies reveal that incorporating OCR and caption cues consistently improves attention-based grounding performance across different backbones, highlighting its effectiveness as a general framework for GUI grounding.
Multi-Agent Intelligence for Multidisciplinary Decision-Making in Gastrointestinal Oncology
Dec 23, 2025Multimodal clinical reasoning in the field of gastrointestinal (GI) oncology necessitates the integrated interpretation of endoscopic imagery, radiological data, and biochemical markers. Despite the evident potential exhibited by Multimodal Large Language Models (MLLMs), they frequently encounter challenges such as context dilution and hallucination when confronted with intricate, heterogeneous medical histories. In order to address these limitations, a hierarchical Multi-Agent Framework is proposed, which emulates the collaborative workflow of a human Multidisciplinary Team (MDT). The system attained a composite expert evaluation score of 4.60/5.00, thereby demonstrating a substantial improvement over the monolithic baseline. It is noteworthy that the agent-based architecture yielded the most substantial enhancements in reasoning logic and medical accuracy. The findings indicate that mimetic, agent-based collaboration provides a scalable, interpretable, and clinically robust paradigm for automated decision support in oncology.
Mono4DEditor: Text-Driven 4D Scene Editing from Monocular Video via Point-Level Localization of Language-Embedded Gaussians
Oct 10, 2025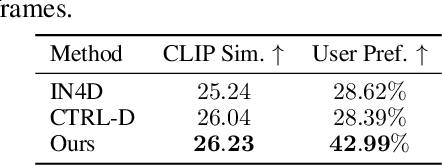
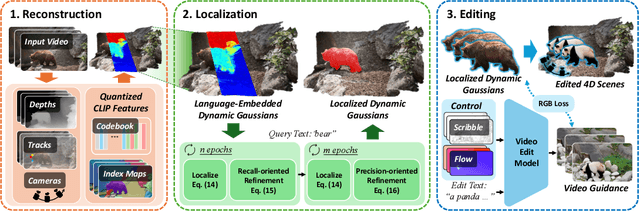
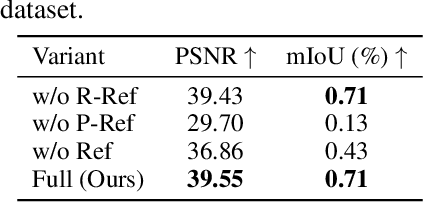

Editing 4D scenes reconstructed from monocular videos based on text prompts is a valuable yet challenging task with broad applications in content creation and virtual environments. The key difficulty lies in achieving semantically precise edits in localized regions of complex, dynamic scenes, while preserving the integrity of unedited content. To address this, we introduce Mono4DEditor, a novel framework for flexible and accurate text-driven 4D scene editing. Our method augments 3D Gaussians with quantized CLIP features to form a language-embedded dynamic representation, enabling efficient semantic querying of arbitrary spatial regions. We further propose a two-stage point-level localization strategy that first selects candidate Gaussians via CLIP similarity and then refines their spatial extent to improve accuracy. Finally, targeted edits are performed on localized regions using a diffusion-based video editing model, with flow and scribble guidance ensuring spatial fidelity and temporal coherence. Extensive experiments demonstrate that Mono4DEditor enables high-quality, text-driven edits across diverse scenes and object types, while preserving the appearance and geometry of unedited areas and surpassing prior approaches in both flexibility and visual fidelity.
YUNet: Improved YOLOv11 Network for Skyline Detection
Feb 18, 2025Skyline detection plays an important role in geolocalizaion, flight control, visual navigation, port security, etc. The appearance of the sky and non-sky areas are variable, because of different weather or illumination environment, which brings challenges to skyline detection. In this research, we proposed the YUNet algorithm, which improved the YOLOv11 architecture to segment the sky region and extract the skyline in complicated and variable circumstances. To improve the ability of multi-scale and large range contextual feature fusion, the YOLOv11 architecture is extended as an UNet-like architecture, consisting of an encoder, neck and decoder submodule. The encoder extracts the multi-scale features from the given images. The neck makes fusion of these multi-scale features. The decoder applies the fused features to complete the prediction rebuilding. To validate the proposed approach, the YUNet was tested on Skyfinder and CH1 datasets for segmentation and skyline detection respectively. Our test shows that the IoU of YUnet segmentation can reach 0.9858, and the average error of YUnet skyline detection is just 1.36 pixels. The implementation is published at https://github.com/kuazhangxiaoai/SkylineDet-YOLOv11Seg.git.
Maximizing User Connectivity in AI-Enabled Multi-UAV Networks: A Distributed Strategy Generalized to Arbitrary User Distributions
Nov 07, 2024



Deep reinforcement learning (DRL) has been extensively applied to Multi-Unmanned Aerial Vehicle (UAV) network (MUN) to effectively enable real-time adaptation to complex, time-varying environments. Nevertheless, most of the existing works assume a stationary user distribution (UD) or a dynamic one with predicted patterns. Such considerations may make the UD-specific strategies insufficient when a MUN is deployed in unknown environments. To this end, this paper investigates distributed user connectivity maximization problem in a MUN with generalization to arbitrary UDs. Specifically, the problem is first formulated into a time-coupled combinatorial nonlinear non-convex optimization with arbitrary underlying UDs. To make the optimization tractable, a multi-agent CNN-enhanced deep Q learning (MA-CDQL) algorithm is proposed. The algorithm integrates a ResNet-based CNN to the policy network to analyze the input UD in real time and obtain optimal decisions based on the extracted high-level UD features. To improve the learning efficiency and avoid local optimums, a heatmap algorithm is developed to transform the raw UD to a continuous density map. The map will be part of the true input to the policy network. Simulations are conducted to demonstrate the efficacy of UD heatmaps and the proposed algorithm in maximizing user connectivity as compared to K-means methods.
Learning with Dynamics: Autonomous Regulation of UAV Based Communication Networks with Dynamic UAV Crew
Sep 25, 2024Unmanned Aerial Vehicle (UAV) based communication networks (UCNs) are a key component in future mobile networking. To handle the dynamic environments in UCNs, reinforcement learning (RL) has been a promising solution attributed to its strong capability of adaptive decision-making free of the environment models. However, most existing RL-based research focus on control strategy design assuming a fixed set of UAVs. Few works have investigated how UCNs should be adaptively regulated when the serving UAVs change dynamically. This article discusses RL-based strategy design for adaptive UCN regulation given a dynamic UAV set, addressing both reactive strategies in general UCNs and proactive strategies in solar-powered UCNs. An overview of the UCN and the RL framework is first provided. Potential research directions with key challenges and possible solutions are then elaborated. Some of our recent works are presented as case studies to inspire innovative ways to handle dynamic UAV crew with different RL algorithms.
PAT: Pruning-Aware Tuning for Large Language Models
Aug 27, 2024
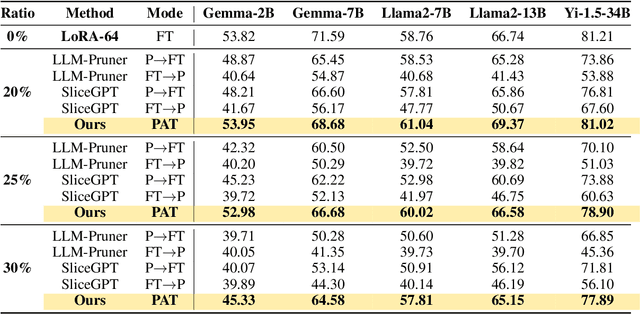
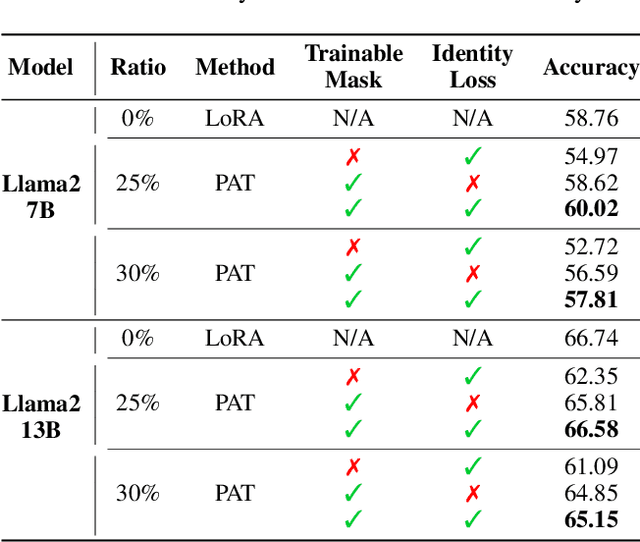
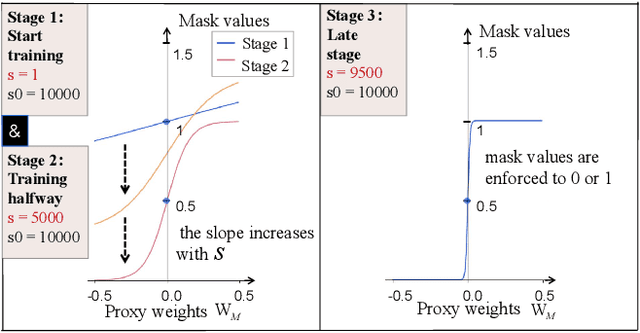
Large language models (LLMs) excel in language tasks, especially with supervised fine-tuning after pre-training. However, their substantial memory and computational requirements hinder practical applications. Structural pruning, which reduces less significant weight dimensions, is one solution. Yet, traditional post-hoc pruning often leads to significant performance loss, with limited recovery from further fine-tuning due to reduced capacity. Since the model fine-tuning refines the general and chaotic knowledge in pre-trained models, we aim to incorporate structural pruning with the fine-tuning, and propose the Pruning-Aware Tuning (PAT) paradigm to eliminate model redundancy while preserving the model performance to the maximum extend. Specifically, we insert the innovative Hybrid Sparsification Modules (HSMs) between the Attention and FFN components to accordingly sparsify the upstream and downstream linear modules. The HSM comprises a lightweight operator and a globally shared trainable mask. The lightweight operator maintains a training overhead comparable to that of LoRA, while the trainable mask unifies the channels to be sparsified, ensuring structural pruning. Additionally, we propose the Identity Loss which decouples the transformation and scaling properties of the HSMs to enhance training robustness. Extensive experiments demonstrate that PAT excels in both performance and efficiency. For example, our Llama2-7b model with a 25\% pruning ratio achieves 1.33$\times$ speedup while outperforming the LoRA-finetuned model by up to 1.26\% in accuracy with a similar training cost. Code: https://github.com/kriskrisliu/PAT_Pruning-Aware-Tuning
Language Embedded 3D Gaussians for Open-Vocabulary Scene Understanding
Nov 30, 2023



Open-vocabulary querying in 3D space is challenging but essential for scene understanding tasks such as object localization and segmentation. Language-embedded scene representations have made progress by incorporating language features into 3D spaces. However, their efficacy heavily depends on neural networks that are resource-intensive in training and rendering. Although recent 3D Gaussians offer efficient and high-quality novel view synthesis, directly embedding language features in them leads to prohibitive memory usage and decreased performance. In this work, we introduce Language Embedded 3D Gaussians, a novel scene representation for open-vocabulary query tasks. Instead of embedding high-dimensional raw semantic features on 3D Gaussians, we propose a dedicated quantization scheme that drastically alleviates the memory requirement, and a novel embedding procedure that achieves smoother yet high accuracy query, countering the multi-view feature inconsistencies and the high-frequency inductive bias in point-based representations. Our comprehensive experiments show that our representation achieves the best visual quality and language querying accuracy across current language-embedded representations, while maintaining real-time rendering frame rates on a single desktop GPU.