 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoughLaneNet: Lane Detection with Deep Hough Transform and Dynamic Convolution
Jul 07, 2023
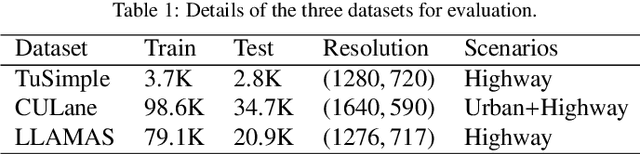

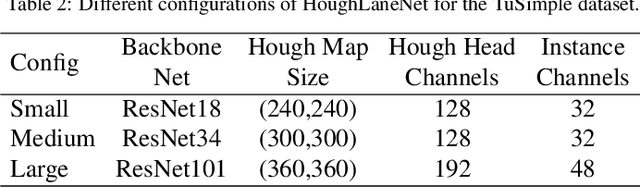
The task of lane detection has garnered considerable attention in the field of autonomous driving due to its complexity. Lanes can present difficulties for detection, as they can be narrow, fragmented, and often obscured by heavy traffic. However, it has been observed that the lanes have a geometrical structure that resembles a straight line, leading to improved lane detection results when utilizing this characteristic. To address this challenge, we propose a hierarchical Deep Hough Transform (DHT) approach that combines all lane features in an image into the Hough parameter space. Additionally, we refine the point selection method and incorporate a Dynamic Convolution Module to effectively differentiate between lanes in the original image. Our network architecture comprises a backbone network, either a ResNet or Pyramid Vision Transformer, a Feature Pyramid Network as the neck to extract multi-scale features, and a hierarchical DHT-based feature aggregation head to accurately segment each lane. By utilizing the lane features in the Hough parameter space, the network learns dynamic convolution kernel parameters corresponding to each lane, allowing the Dynamic Convolution Module to effectively differentiate between lane features. Subsequently, the lane features are fed into the feature decoder, which predicts the final position of the lane. Our proposed network structure demonstrates improved performance in detecting heavily occluded or worn lane images, as evidenced by our extensive experimental results, which show that our method outperforms or is on par with state-of-the-art techniques.
Deep Line Art Video Colorization with a Few References
Mar 30, 2020
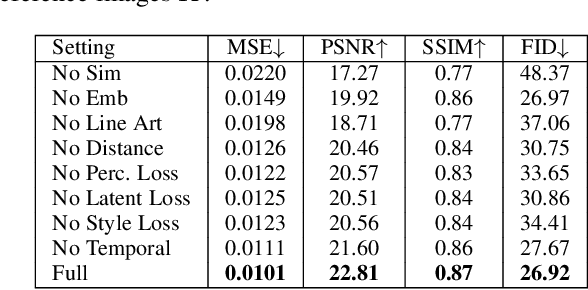
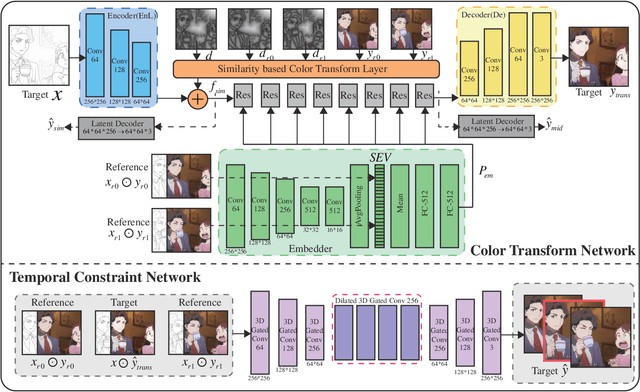
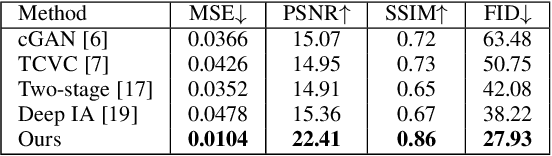
Coloring line art images based on the colors of reference images is an important stage in animation production, which is time-consuming and tedious. In this paper, we propose a deep architecture to automatically color line art videos with the same color style as the given reference images. Our framework consists of a color transform network and a temporal constraint network. The color transform network takes the target line art images as well as the line art and color images of one or more reference images as input, and generates corresponding target color images. To cope with larger differences between the target line art image and reference color images, our architecture utilizes non-local similarity matching to determine the region correspondences between the target image and the reference images, which are used to transform the local color information from the references to the target. To ensure global color style consistency, we further incorporate Adaptive Instance Normalization (AdaIN) with the transformation parameters obtained from a style embedding vector that describes the global color style of the references, extracted by an embedder. The temporal constraint network takes the reference images and the target image together in chronological order, and learns the spatiotemporal features through 3D convolution to ensure the temporal consistency of the target image and the reference image. Our model can achieve even better coloring results by fine-tuning the parameters with only a small amount of samples when dealing with an animation of a new style. To evaluate our method, we build a line art coloring dataset. Experiments show that our method achieves the best performance on line art video coloring compared to the state-of-the-art methods and other baselines.