 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time 3D-aware Portrait Video Relighting
Oct 24, 2024Synthesizing realistic videos of talking faces under custom lighting conditions and viewing angles benefits various downstream applications like video conferencing. However, most existing relighting methods are either time-consuming or unable to adjust the viewpoints. In this paper, we present the first real-time 3D-aware method for relighting in-the-wild videos of talking faces based on Neural Radiance Fields (NeRF). Given an input portrait video, our method can synthesize talking faces under both novel views and novel lighting conditions with a photo-realistic and disentangled 3D representation. Specifically, we infer an albedo tri-plane, as well as a shading tri-plane based on a desired lighting condition for each video frame with fast dual-encoders. We also leverage a temporal consistency network to ensure smooth transitions and reduce flickering artifacts. Our method runs at 32.98 fps on consumer-level hardware and achieves state-of-the-art results in terms of reconstruction quality, lighting error, lighting instability, temporal consistency and inference speed. We demonstrate the effectiveness and interactivity of our method on various portrait videos with diverse lighting and viewing conditions.
NeRFFaceEditing: Disentangled Face Editing in Neural Radiance Fields
Nov 15, 2022



Recent methods for synthesizing 3D-aware face images have achieved rapid development thanks to neural radiance fields, allowing for high quality and fast inference speed. However, existing solutions for editing facial geometry and appearance independently usually require retraining and are not optimized for the recent work of generation, thus tending to lag behind the generation process. To address these issues, we introduce NeRFFaceEditing, which enables editing and decoupling geometry and appearance in the pretrained tri-plane-based neural radiance field while retaining its high quality and fast inference speed. Our key idea for disentanglement is to use the statistics of the tri-plane to represent the high-level appearance of its corresponding facial volume. Moreover, we leverage a generated 3D-continuous semantic mask as an intermediary for geometry editing. We devise a geometry decoder (whose output is unchanged when the appearance changes) and an appearance decoder. The geometry decoder aligns the original facial volume with the semantic mask volume. We also enhance the disentanglement by explicitly regularizing rendered images with the same appearance but different geometry to be similar in terms of color distribution for each facial component separately. Our method allows users to edit via semantic masks with decoupled control of geometry and appearance. Both qualitative and quantitative evaluations show the superior geometry and appearance control abilities of our method compared to existing and alternative solutions.
DrawingInStyles: Portrait Image Generation and Editing with Spatially Conditioned StyleGAN
Mar 05, 2022
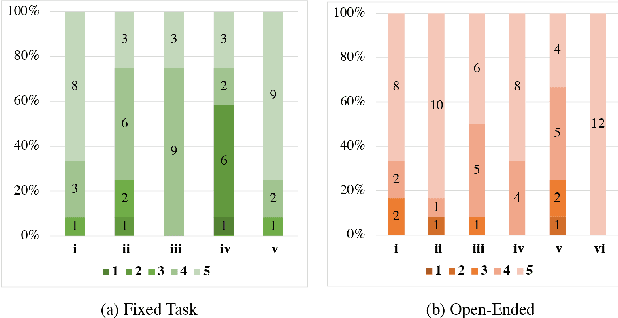

The research topic of sketch-to-portrait generation has witnessed a boost of progress with deep learning techniques. The recently proposed StyleGAN architectures achieve state-of-the-art generation ability but the original StyleGAN is not friendly for sketch-based creation due to its unconditional generation nature. To address this issue, we propose a direct conditioning strategy to better preserve the spatial information under the StyleGAN framework. Specifically, we introduce Spatially Conditioned StyleGAN (SC-StyleGAN for short), which explicitly injects spatial constraints to the original StyleGAN generation process. We explore two input modalities, sketches and semantic maps, which together allow users to express desired generation results more precisely and easily. Based on SC-StyleGAN, we present DrawingInStyles, a novel drawing interface for non-professional users to easily produce high-quality, photo-realistic face images with precise control, either from scratch or editing existing ones. Qualitative and quantitative evaluations show the superior generation ability of our method to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
Deep Generation of Face Images from Sketches
Jun 05, 2020
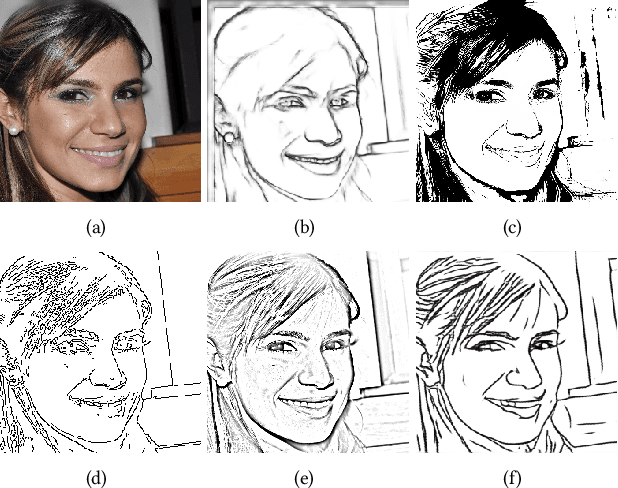
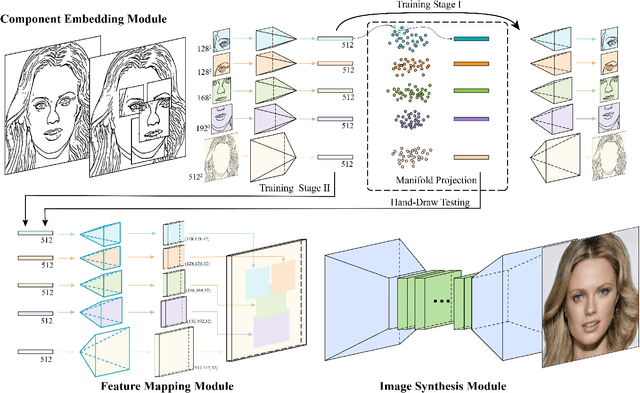

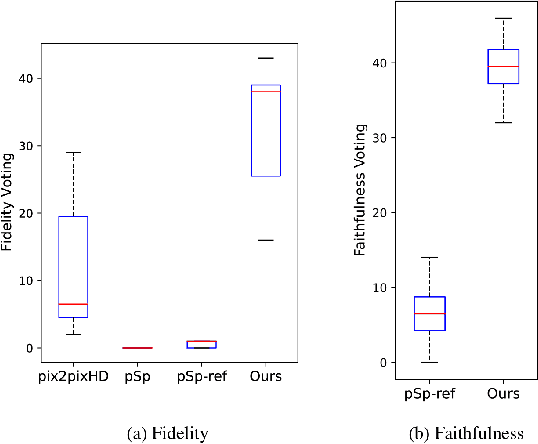
Recent deep image-to-image translation techniques allow fast generation of face images from freehand sketches. However, existing solutions tend to overfit to sketches, thus requiring professional sketches or even edge maps as input. To address this issue, our key idea is to implicitly model the shape space of plausible face images and synthesize a face image in this space to approximate an input sketch. We take a local-to-global approach. We first learn feature embeddings of key face components, and push corresponding parts of input sketches towards underlying component manifolds defined by the feature vectors of face component samples. We also propose another deep neural network to learn the mapping from the embedded component features to realistic images with multi-channel feature maps as intermediate results to improve the information flow. Our method essentially uses input sketches as soft constraints and is thus able to produce high-quality face images even from rough and/or incomplete sketches. Our tool is easy to use even for non-artists, while still supporting fine-grained control of shape details. Both qualitative and quantitative evaluations show the superior generation ability of our system to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
Deep Line Art Video Colorization with a Few References
Mar 30, 2020
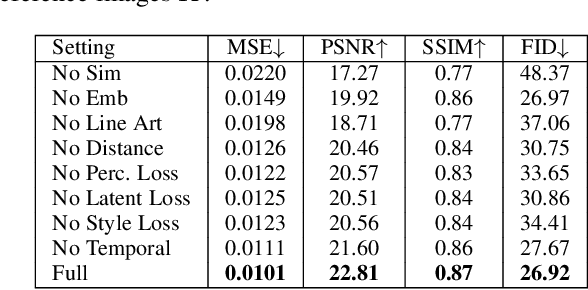
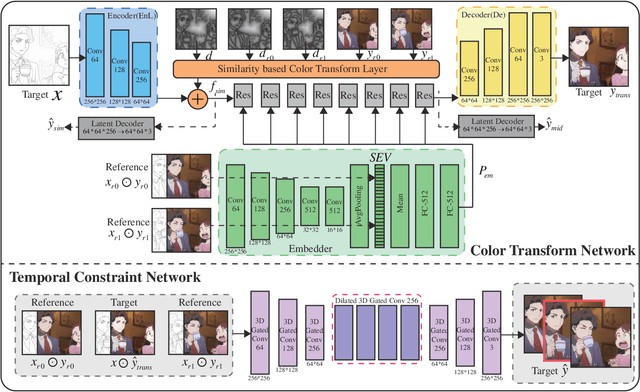
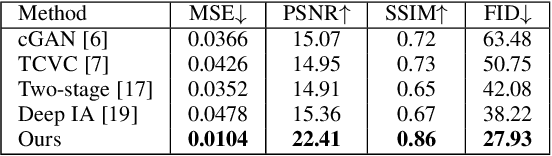
Coloring line art images based on the colors of reference images is an important stage in animation production, which is time-consuming and tedious. In this paper, we propose a deep architecture to automatically color line art videos with the same color style as the given reference images. Our framework consists of a color transform network and a temporal constraint network. The color transform network takes the target line art images as well as the line art and color images of one or more reference images as input, and generates corresponding target color images. To cope with larger differences between the target line art image and reference color images, our architecture utilizes non-local similarity matching to determine the region correspondences between the target image and the reference images, which are used to transform the local color information from the references to the target. To ensure global color style consistency, we further incorporate Adaptive Instance Normalization (AdaIN) with the transformation parameters obtained from a style embedding vector that describes the global color style of the references, extracted by an embedder. The temporal constraint network takes the reference images and the target image together in chronological order, and learns the spatiotemporal features through 3D convolution to ensure the temporal consistency of the target image and the reference image. Our model can achieve even better coloring results by fine-tuning the parameters with only a small amount of samples when dealing with an animation of a new style. To evaluate our method, we build a line art coloring dataset. Experiments show that our method achieves the best performance on line art video coloring compared to the state-of-the-art methods and other baselines.